Itt az Nvidia legújabb grafikus architektúrája, a Turing
Megérkezett az Nvidia legújabb grafikus mikroarchitektúrája, a Turing, ezzel együtt pedig az arra épülő első termékek is bemutatkoztak. A Santa Clarai-i székhelyű chiptervező vadiúj fejlesztése számos újítást vezet be a Pascalhoz és a Voltához képest. Az Nvidia viszonylag felületes bemutatója alapján a tervezők célkeresztjében elsősorban a ray tracing, illetve a gépi tanulásos végrehajtás továbbfejlesztése állt, az új mikroarchitektúra ugyanis számos ezekre irányuló funkciót vezet be. Turing alapokon első körben professzionális, Quadro kártyák érkeznek, ám borítékolhatóan ezekkel együtt (vagy inkább előbb) új GeForce-ok is bemutatkoznak.
A kódfejtés nagymestereként ismert brit matematikusról elnevezett Turing egyik legfontosabb újítása az úgynevezett Hybrid Rendering. Ez a globális bevilágítási rendertechnikán alapuló ray tracing (sugárkövetés), illetve a hagyományos raszterizált grafika egyvelegét jelenti. Utóbbival egyre nehezebben látványos előrelépést felmutatni, egyes vélemények szerint a technika már elérte lehetőségeinek határait. Ezt vallja az Nvidia is, aki a minőség javításához most a ray tracinget hívja segítségül. Az Nvidia legutóbb márciusban demonstrálta ray tracing fejlesztését amelyet a lassan tíz éve bemutatott OptiX API-n, a közelmúltban debütált DirectX Raytracing API-n, illetve Vulkánnal is el lehet érni.

Részben ehhez gyúrta ki a Turingot a chiptervező, amely dedikált végrehajtókat kapott az RT (Ray Tracing) magok formájában. A fejlesztésről egyelőre csupán néhány mondatban beszélt a cég, amely szerint a blokkok az úgynevezett ray-triangle intersection checks és bounding volume hierarchy (BVH) manipulation műveleteket hivatott jelentősen gyorsítani. Az Nvidia ígérete szerint ezzel a legerősebb Turing GPU másodpercenként 10 milliárd sugár (gigarays) feldolgolására képes, amely a nyers tempót nézve óriási, huszonötszörös gyorsulást jelent a legerősebb Pascalhoz viszonyítva. Az effektív gyorsulás ennél szerényebb lehet, az Nvidia hatszoros szorzóról beszélt az említett elődhöz képest.
Az új grafikus mikroarchitektúra azonban nem csak az utóbb említett fejlesztéshez képest hoz előrelépést. A Turingba bekerült a Voltában debütált Tensor mag is, egészen pontosan annak egy továbbfejlesztett variánsa. Ez eredetileg a gépi tanulásos műveletek gyorsítása miatt jött világra, a Turinggal viszont ezt igyekszik a grafikában, azon belül is a ray tracingben is kamatoztatni a cég. A Tensor magok ugyanis befoghatóak a megjelenítés gyorsításához is, gépi tanulásos algoritmussal ugyanis az egyes jelenetekből a felesleges sugarak (rays) "kivághatóak". Ehhez az NVIDIA NGX formájában egy új SDK-t is kiad a cég, amellyel a Tensor magok különféle képfeldolgozási segédműveletekre is befoghatóak lesznek. Emellett természetesen adatközpontos környezetben is működnek az egységek, ráadásul bizonyos esetekben gyorsabban mint a Voltánál.
A frontendes szakma tündöklése és alkonya A modern JS keretrendszerek önálló kompetenciává emelték a frontend-fejlesztést. Most viszont úgy tűnik, hogy ez a szakma kikophat a piacról.
A tervezőcég ugyanis tovább bővítette a Tensor magok által gyorsítható műveletek listáját, amelyek ezzel INT8 (8 bites integer) mellett már INT4 (4 bites integer) műveleteket is képes végrehajtani, az előbbihez képest kétszeres tempó mellett. Az Nvidia arról egyelőre hallgat, hogy pontosan milyen módszerrel oldja meg az INT4 végrehajtást, amely alacsony pontosságú formátum bizonyos gépi tanulásos modellek esetén komoly sebességnövekedést hozhat. Az Nvidia ezen képesség boncolását vélhetően az új Tesla kártyák bemutatására tartogatja, amely jelen állás szerint még hónapokra lehet.
Végül, de nem utolsó sorban az alap építőelemnek számító Streaming Multiprocessor (SM) is továbbfejlődött. A fejlesztés keretében a Turing megörökölte a Volta eddigi egyik sajátosságát, az integer és a lebegőpontos végrehajtók ugyanis immár két külön blokkban, elszeparáltan vannak jelen, amely független (és teljesen párhuzamos) végrehajtást tesz lehetővé. A Voltánál látottak alapján ezzel például gyorsítható a címgenerálás és az FMA (Fused Multiply Add) műveletek végrehajtása. Bár az Nvidia egyelőre nem erősített meg, a Turing vélhetően a gyorsabb végrehajtással kecsegtető fast FP16-ot is támogatja. Ez dióhéjban azt jelentheti, hogy az Nvidia új üdvöskéje is támogatja az RPM-et (Rapid Packed Math). A konkurens AMD Vegával bemutatkozott képességgel több kisebb műveletet lehet egyetlen csokorba fogni és tempósabban végrehajtani. Ezzel egyes jelenetek jelentősen gyorsíthatóak, bizonyos esetekben ugyanis egyszerűen nincs szükség az egyszeres pontosságra (FP32).

Az úgynevezett "unified cache architecture" fejlesztésről egyelőre hallgat az Nvidia, az egyik GPU-t ábrázoló képen azonban felbukkant az "Unified L1 cache" képesség, amely egységesített elsőszintű gyorsítótárra utal. Hasonlót a Voltánál is láthattunk, ott az L1-et a megosztott memóriával vonta össze az Nvidia, azonban egyelőre nem tudni, hogy jelen esetben is erről van-e szó. A tervezőcég csupán annyit árult el, hogy a gyorsítótár sávszélessége kétszerese az "előző generációénak", azonban arra nem derült fény, hogy itt a Pascalra vagy a Voltára céloztak a készítők. Végezetül variable rate shading képességet érdemes kiemelni, amelyről szintén csak pár mondatot közölt a cég. Ez alapján a lehetőséget meglovagolva egyes shaderek felbontása eltérhet, amellyel az erőforrások koncentrálhatóak a fontosabb, részletgazdagabb, vagy a gyorsabb végrehajtást igénylő shaderekre.
...és a körítés
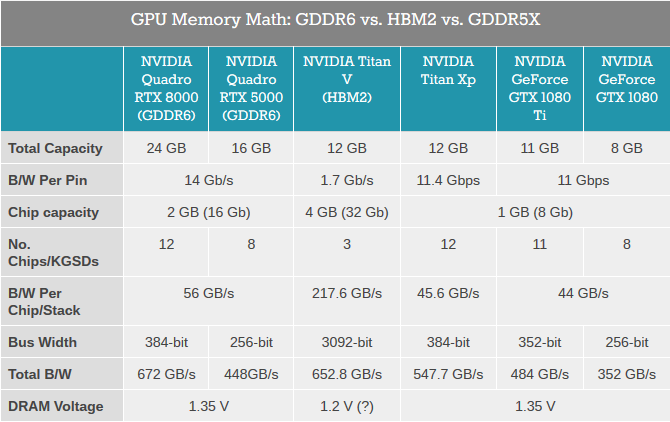
Az Nvidia bejelentése alapján a Turing mikroarchitektúrális fejlesztések mellett új memóriát is kap, az érkező videokártyák egy részén ugyanis már GDDR6 chipek lesznek. Ahogy arról korábban már többször írt a HWSW, az új memóriatípus lényegesen nagyobb kapacitássűrűséget és sávszélességet hoz, amelyet kihasználva például azonos darabszám mellett növelhető a kapacitás és sávszélesség, vagy akár a korábbi értékek állíthatóak elő kevesebb chippel, kisebb komplexitás mellett - magyarán olcsóbban. Joggal merülhet fel a kérdés, hogy az Nvidia miért nem HBM2 chipeket választott a Turing mellé. A válasz prózai, a villámgyors rétegzett memória ugyanis nem csak rendkívül hatékony, de rendkívül drága is, a chipek mellett ugyanis a gyártási költség is tetemes az összeköttetéshez szükséges interpózer miatt.
 forrás: AnandTech
forrás: AnandTech
Az első Turingokhoz a Samsung elérhető leggyorsabb, 14 Gbps sebességű GDDR6 chipjeit választotta az Nvidia. Ezekből modellektől függően (erről később) 12 (384 bites busz) vagy 8 (256 bites busz) darab került fel a GPU mellé. A chipenkénti (a GDDR5-höz viszonyított) nagyobb sávszélességnek hála ezzel 672, valamint 448 GB/s-os sávszélességet rakott össze az Nvidia. Előbbi felülmúlja a három darab HBM2-vel szerelt Titan V értékét, a GDDR6 tehát számos esetben jelenthet költséghatékonyabb alternatívát a rétegzett memóriával szemben.
Az első Turing alapú termékek (Quadrók) NVLink csatolóval is rendelkeznek, amelynek hála két kártya drótozható össze a nagyobb tempó eléréséhez. A busz sebességéről egyelőre nem beszélt az Nvidia, azonban vélhetően 100 GB/s a sávszélesség. Az NVLinkkel szemben újdonság a VirtualLink, amely VR-headsetek szabványos csatlakozója. Az USB Type-C csatolós megoldásnak hála az eszközökről eltűnhetnek a zavaró "kábelcopfok", és a szemüvegek egyetlen vezetéken csatlakozhatnak majd a számítógéphez. Végül, de nem utolsó sorban a fixfunkciós NVENC kódolóblokk is frissült, amely immár képes 8K HEVC anyagok feldolgozására is a korábban megismert módon, vagyis rendkívül alacsony fogyasztás mellett.
Új Quadrók
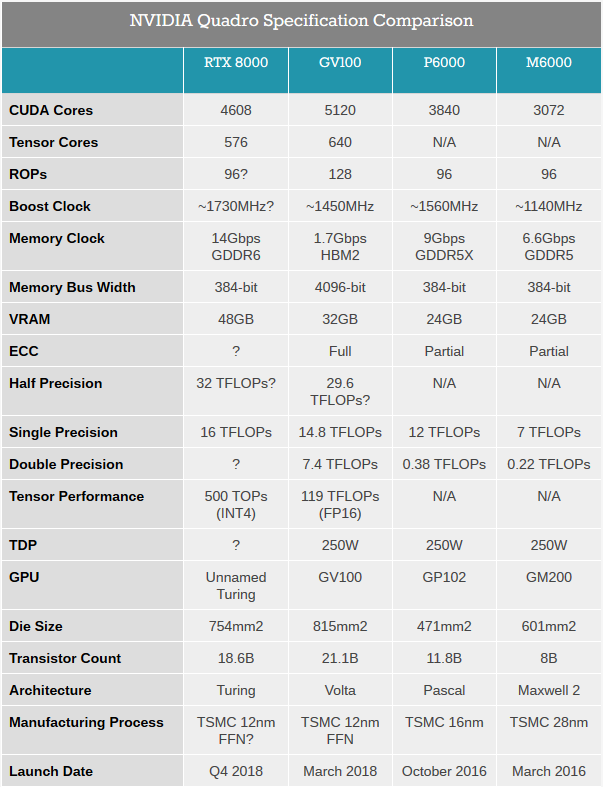
Az Nvidia első körben professzionális kártyákat, vagyis Quadrókat jelentett be a Turingra építve. Ezek a Ray Tracing iránynak megfelelően RTX 8000, RTX 6000, és RTX 5000 típusjelzéssel kerülnek majd piacra valamikor a következő hónapok, legkésőbb az utolsó negyedév során. A tervezőcég csak a csúcsmodell, vagyis az RTX 8000 specifikációiról beszélt a teljesség igénye nélkül. A kártyára egy egyelőre meg nem nevezett, 4608 CUDA maggal szerelt GPU kerül, amelynek alapterülete hatalmas, 754 mm2. A lapka nem sokkal kisebb mint GV100-as Volta, amely 815 mm2-en 21,1 milliárd tranzisztort fektet le. Az első Turingba ennél kevesebb, "csupán" 18,6 milliárd tranzisztor került, amely a már említett CUDA magok mellett 576 darab Tensor magot is felvonultat. A Quadro RTX 8000 maximális GPU-órajele 1730 MHz körül alakulhat, amely meglehetősen magas, magasabb mint a GV100-é vagy a P6000-é.
 forrás: AnandTech
forrás: AnandTech
Ezzel együtt az új csúcskártya nagyobb tempót ígér, az ugyanis egyszeres pontosság mellett 16 TFLOPS-ot kínál (GV100: 14,8, Tesla V100: 15), félpontosság mellett pedig ennek (valószínűleg) dupláját. Említésre méltó még az úgynevezett Tensor teljesítmény, az RTX 8000 ugyanis a feljebb részletezett fejlesztését meglovagolva 500 TOPs-ra képes INT4 műveletek esetében. Eközben a GV100 csak egyszeres pontosságú lebegőpontos (FP16) műveletekre képes, amely alacsonyabb, 119 TFLOPs-os tempót jelent. Végül, de nem utolsó sorban érdemes még kiemelni a memória kapacitását, az Nvidia ugyanis 48 gigabájt VRAM-mal szerelte a potom nettó 10 000 dolláros RTX 8000-et, amely 50 százalékkal magasabb a korábbi Quadro GV100 értékénél.
Az, hogy mindez pontosan miként tükröződik a gyakorlatban, egyelőre nem árulta el az Nvidia, amely még belső méréseket sem közölt. Jelen állás szerint a független mérésekre az év utolsó negyedévéig kell várni, ekkora kerülnek piacra az új Quadrók. A pletykák szerint azonban az ugyancsak Turingra épülő GeForce-ok ennél hamarabb megjelenhetnek, már akár a hónap végén befuthatnak a csúcsmodellek, így egyes fejlesztések gyakorlati hasznára pár héten belül érkezhet válasz.