A nagyvállalati és üzleti piacra fókuszál az Nvidia
Elsősorban nagyvállalati lábát igyekezett kigyúrni saját konferenciáján elhangzott bejelentéseivel az Nvidia, amely eközben a grafikáról, illetve az önvezető autók fejlesztéséről sem feledkezett meg.
Bár átütő újdonságot nem mutatott be épp zajló GTC rendezvényén az Nvidia, így is volt miről beszélnie nyitóelőadásán a vállalatot kormányzó Jensen Huangnak. A korábbi pletykákkal ellentétben a játékosokat szinte teljesen hanyagolta a bejelentésáradat, helyettük pedig a nagyvállalati piacot, a fejlesztőket, illetve az önvezető autókat emelte porondra az Nvidia. Ennek megfelelően nagy GPU-s klasztert és új szervert, munkaállomásokba szánt új csúcskártyát, valamint az önvezető autós platform jövőjét boncolgatta cég első embere.
A keynote előadás bár grafikával nyitott, a témát viszonylag hamar kivesézte Huang. Elsőként az Nvidia RTX technológia került terítékre, amely a valós idejű ray tracing igyekszik szélesebb körben bevezetni. A globális bevilágítási rendertechnikák, mint amilyen a ray tracing is, sokkal realisztikusabb világot eredményeznek, valósidejű interaktív alkalmazásuk ugyanakkor mindeddig túlságosan számításigényesnek bizonyult, ezért jóformán csak renderelt videókban találkozhattunk velük, valósidejű megjelenítésben nem. A hardverek rohamos fejlődésével ugyanakkor már elérhető közelségbe került a ray tracing alkalmazása, miközben a hagyományos raszterizált grafika egyre nehezebben képes látványos előrelépést felmutatni, egyes vélemények szerint a technika már elérte lehetőségeinek határait.

Az RTX gyakorlatilag az Nvidia ray tracing keresztplatform grafikai szabványa, amelyet a lassan tíz éve bemutatott OptiX API-n, a közelmúltban debütált DirectX Raytracing API-n, illetve hamarosan a Vulkánon át is el lehet (majd) érni, egyelőre csak Volta-alapú GPU-val. Többek között ehhez kínálja legújabb Quadro kártyáját a cég, amely a GV100-as csúcsprocesszorra épül. Az 5120 darab CUDA magot, 32 gigabájt fedélzeti HBM2 memóriát, ezekkel pedig a dupla pontosság mellett akár 7,4 TFLOPS-ot kínáló Quadro GV100-ból kettőt is össze lehet kötni, hála az NVLink busznak.
Ehhez ugyanakkor alaposan zsebbe kell nyúlni, az Nvidia legújabb professzionális kártyája ugyanis 9000 dollárba kerül. Az új Quadróval rövidebb idő alatt hozható létre a ray tracinges jelenetek előnézete, amellyel felgyorsítható a végtermék elkészítése. A bemutató alapján a valós idejű ray tracinghez négy GV100 szükséges - ami nem ígéretes. Eszerint ugyanis még nagyjából 5-10 év kellhet ahhoz, hogy a mainstream videokártyák teljesítményszintje elegendő legyen a realisztikusabb megjelenítést kínáló technológia meghajtásához, addig viszont legfeljebb nyomokban tartalmazhatnak valós idejű ray tracinget mainstream alkalmazások (pl. játékok).
Nagyon nagy "GPU" és új HPC szerver
Bár ahogy már utaltunk rá, új GPU-t nem mutatott be az Nvidia, egy azokra épülő, kvázi összefüggő egységnek tekinthető impozáns klaszter előkerült a színpadon. A tizenhat darab, immár fejenként 32 gigabájt memóriával felvértezett Tesla V100 önmagában még nem lenne akkora durranás, azonban az egyes GPU-kat az újonnan bemutatott NVSwitch segítségével összedrótozta a cég, így azok (messziről nézve) egy nagy összefüggő processzornak is tekinthetőek. Az igazi újdonságot jelentő, saját tervezésű, fejenként tizennyolc NVLinket tartalmazó NVSwitch lapkából összesen tizenkét darab szükséges a rendszer működéséhez. Ezzel a GPU-nkénti sávszélesség eléri a 300 GB/s-t, ami a PCI Express értékének nagyjából húszszorosa, a fabricként funkcionáló alrendszerrel pedig a GPU-k hozzáférhetnek egymás memóriaterületeihez is, tehát a rendszer koherens.

Mindez óriási számítási teljesítményt nyújt, az összesen 81 920 CUDA mag, illetve az 512 gigabájtnyi, 14,4 TB/s aggregált sávszélességet kínáló memóriának hála a kapacitás mélytanulásos (félpontosságú) műveletek esetében 2 petaflopsra rúghat, amely már szuperszámítógépes mércével nézve is számottevő - ez ma elegendő lenne a Top 500-as listába kerüléshez. A tizenhat GPU-ból álló klasztert természetesen nem csak mutatóba rakta össze az Nvidia, azt két Intel Xeon Platinum, 1,5 terabájt memória, valamint 30 terabájt NVMe SSD társaságában a közel két éve bemutatott DGX-1 utódjaként dobja piacra a cég.
A DGX-2 névre keresztelt, 10 kilowattos fogyasztású szervert elsősorban mérnöki-tudományos feladatokhoz, például deep learninghez ajánlja az Nvidia, "baráti árért" cserébe. A fogyasztási adat igen figyelemre méltó, az ilyen nyers teljesítményű szuperszámítógépek 600-3000 kilowatt között szoktak fogyasztani, az Nvidia tehát nem csak teljesítménysűrűségben, hanem hatékonyságban is nagyságrendeket javít. A dobozba zárt szuperszámítógépeként aposztrofált komplett rendszerért ugyanis 400 000 dollárt kér az Nvidia, amely a meglobogtatott számítási teljesítmény fényében valóban nem hangzik rosszul. A szerver ugyanis a cég szerint nyolcad áron, illetve töredék fogyasztás (1/18) és helyigény (1/60) mellett üzemeltethető egy hasonló számítási teljesítményre képes, kvázi hagyományos klaszterhez mérve.

Szintén előrelépett az NVIDIA GPU Cloud, vagyis a cég gépi tanulásra vonatkozó keretrendszereket és más eszközöket (pl. harmadik féltől származó alkalmazásokat) biztosító csomagja. A GPU Cloud immár harminc különféle konténert kezel, a Google, Alibaba, AWS mellett pedig már az Oracle Cloud is támogatott. Szintén jelentős újítás a Kubernetes támogatás megjelenése, amely az Nvidia szerint gyönyörűen skálázódik GPU-kkal. A Kubernetes megoldásával a Linuxon futó konténerek egységes rendszerként üzemeltethetőek, mérettől szinte függetlenül. Az egy központra kötött konténerek logikusan rendszerezhetőek, migrálhatóak a csomópontok között és automatikus skálázódnak.
Mi a helyzet az önvezetéssel?
Végül, de nem utolsó sorban az Nvidia egyik úttörő fejlesztésének számító önvezető rendszerről is szó esett. A pár éve szinte folyamatosan a porondon álló téma a múlt heti szerencsétlen baleset miatt különösen aktuális. Jensen Huang szerint platform fejlesztése rendkívüli kihívásokat rejt, amelyen folyamatosan dolgozik vállalata. Huang az eseményen elmondta, hogy az Uber érintett autója ugyan használ Nvidia-komponenseket, nem a Drive platformra épít - ez utóbbi tartalmazná a szenzortömböt, a feldolgozást végző szoftverplatformot és számos egyéb kiegészítőt is, az Uber azonban inkább saját platform fejlesztésébe vágta a baltáját.
Az AI ára Fizetnek a befektetők, fizetnek a felhasználók, és nagy árat fizet az IT munkaerőpiac is. Vékony jégen járunk. Itt a 85. kraftie adás.
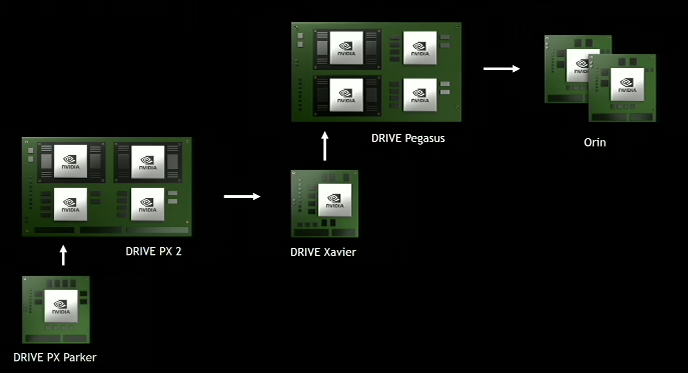
Huang szavai alapján a rendszerével felszerelt járművek évente 3 milliárd kilométert futnak, a tesztekben pedig 370 partner vesz részt. Eközben vállalata már a hardver következő iterációján dolgozik, az idei év második felében érkező Xavier, illetve Pegasus után az Orin következik, amelyről a kódnevén túl egyelőre mást nem árult el az Nvidia első embere.