Szuperszámítógépekhez kínál új utasításkészletet az ARM
Kifejezetten HPC-s környezetbe, szuperszámítógépekhez tervezte legújabb utasításkészletét az ARM, melynek segítségével jelentősen gyorsíthatóak a különféle vektoros műveletek.
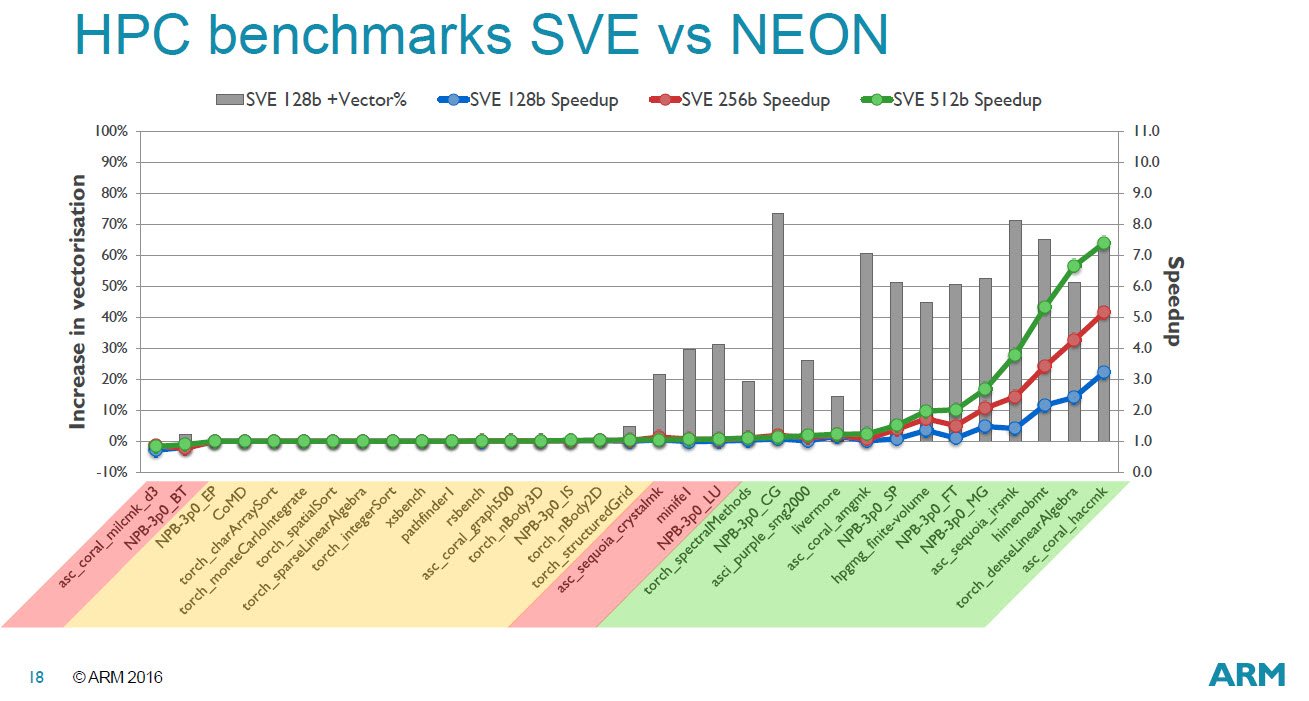
Szuperszámítógépekhez tervezte új utasításkészletét az ARM: az ARMv8-A utasításarchitektúrához illeszthető SVE (Scalable Vector Extensions) flexibilis megoldást kínál az egyedi processzorokat tervező cégeknek, a SIMD ugyanis 128-tól egészen 2048 bitig skálázódik, 128 bites lépcsőkben. Az első SVE-t kihasználó rendszer a Fujitsu "Post-K" szuperszámítógépe lehet, amelynek megjelenése 2020 környékére tehető.
Az új utasításkészlet nem csak nevében hasonlít az Intel AVX-ére (Advanced Vector Extensions), mindkét készlet vektorműveletek gyorsítására szolgál, a két megoldás között ugyanakkor egy alapvető különbséget jelent, hogy az Intel fejlesztése (jelenleg) 256 és 512 bites regiszterekkel működik, az ARM megoldásánál viszont ennek akár négyszeresét, 2048 bitet ígér.

Emellett a vektorok hossza az aktuális igényeknek megfelelően viszonylag rugalmasan, 128 bites lépcsőkben variálható a 128 és 2048 bit közötti tartományban. Ennek kiaknázását segíti a VLA (vector-length agnostic) programozási modell, melynek segítéségével kihasználható az SVE rugalmassága. A VLA mentén elég egyszer összerakni a szoftvert, az képes lesz kihasználni az SVE teljes spektrumát, amennyiben később például a hosszabb vektorokra lenne szükség.
De nem csak szoftveres oldalról rugalmas az SVE. A processzormagban található végrehajtók is eltérő szélesek lehetnek, így például várható 128, 1024, vagy akár 2048 bites egységgel szerelt CPU mag is. A kompatibilitás biztosításához bármilyen kód képes lesz lefutni bármilyen széles végrehajtón, például egy 1024 bites SVE kódot nyolc darabra bontva hajtja majd végre a legkisebb, 128 bites egység. Ez természetesen nem optimális, a végrehajtás nagyjából nyolcszor több időt vesz igénybe mintha egyetlen 1024 bites egységen futna le a számítás, de ez még mindig jobb, mintha a kód egyáltalán nem működne.
A másik véglet, amikor szélesebb végrehajtón futnak le kisebb műveletek. Ebben az esetben a rendszer megpróbálja egy csokorba fogni ezeket, hogy egyetlen ütemben el tudja végezni a műveleteket, így növelve az IPC-t, tehát az órajelenként lefuttatott műveletek számát. Az említett esetekre nem kell felkészíteni a szoftvereket, az optimális végrehajtásról minden esetben a processzor mikroarchitektúrája gondoskodik. A végrehajtók szélességéről a processzormagok tervezői dönthetnek a mindenkori igényeknek, illetve azon az alapvető tulajdonság fényében, hogy a nagyobb egységek rendszerint több tranzisztort igényelnek, illetve fogyasztásuk is magasabb.

Fontos megjegyezni, hogy SVE nem váltja le, csupán kiegészíti a ma már szinte az összes ARM processzorban megtalálható NEON-t. Utóbbi egyszerűbb, 64 és 128 bites vektorokkal működik, és az általános számítások gyorsítására fókuszál, amiből többek között különféle multimédiás kódok profitálhatnak, például képfeldolgozás, játékok, stb. Ezzel szemben az SVE-t kifejezetten a HPC-s igényeknek tervezte az ARM, mely területen többszörös gyorsulást hozhat az új utasításkészlet.
Találkozzunk, idén is lesz SYSADMINDAY! Július 17-én lesz a hazai Sysadminday! Standup, üzemeltetői meetup, kvízek, szakmázás, barátok, még több sörcsap.
A HPC-piacon eddig egyáltalán nem volt jelent az ARM, amin a cég feltett szándéka változtatni. A területen az Intel évek óta szinte egyeduralkodó, a legújabb TOP500-as listában toronymagasan vezetnek a Xeon processzorok, a gyártó termékei összesen 455 rendszerben vannak jelen. A második az IBM, a Nagy Kék processzorai mindössze 23 gépben dolgoznak, AMD Opteronok pedig már csak 13 rendszerben vannak jelen.
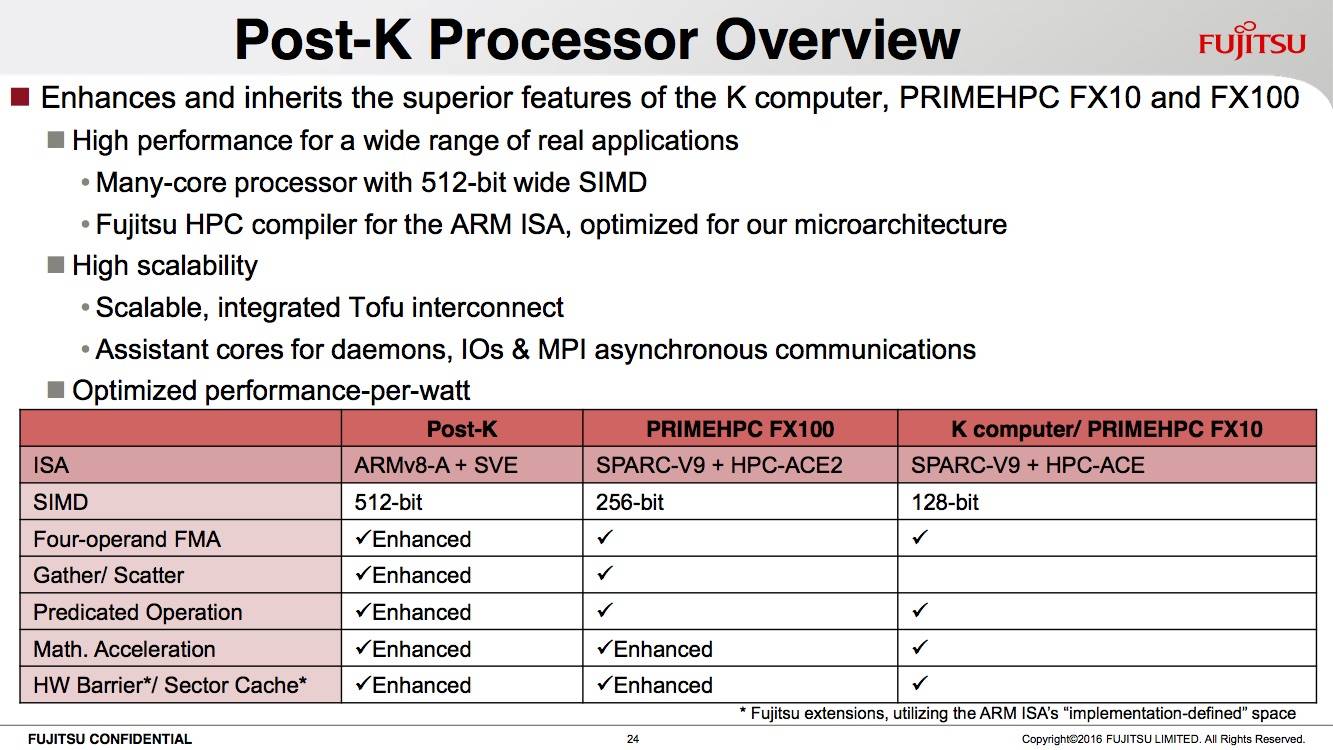
A küzdelembe legkorábban az évtized végén szólhat bele az ARM. A tervezőcég a Fujitsuval közösen dolgozik az első exascale szuperszámítógépen, a "Post-K" kódnevű rendszer számításai kapacitása a tervek szerint el fogja érni az 1000 petaflopsot, ami a nyár elején bejelentett 125 petaflopsos kínai gép teljesítményének nyolcszorosa lenne. Ennek, az egyelőre hatalmasnak tűnő számítási teljesítménynek a most bejelentett új utasításkészlet adhatja az alapját, a 2020 környékére ígért rendszer 512 bites SVE végrehajtókkal érkezhet.