Bővítőkártyáról a CPU-foglalatba költözik a Xeon Phi
A denveri SC13 konferenciát használta az Intel arra, hogy bejelentse a mérnöki-tudományos alkalmazások gyorsítására használt Xeon Phi termékcsalád jövőjével kapcsolatos terveit. A következő generációs Xeon Phi, kódnevén Knights Landing már nem PCI Express felületű bővítőkártyán kap helyet, hanem közvetlenül a szerverek processzorfoglalatába illeszkedik.
Finoman szólva is rögös az útja a Xeon Phinek, amely eredetileg egy grafikus feladatok gyorsítására szánt chipként kezdtek tervezni az Intelnél, hogy aztán a mérnöki-tudományos területre helyezzék át a fókuszt. Az eredetileg Larrabeeként nevezett projektről először 2007-ben, az őszi Intel Developer Forumon beszélt a cég elnök-vezérigazgatója. Az eredeti tervek szerit a Larrabee a mai GPU-khoz hasonló áramkör lett volna, amely a mérnöki-tudományos alkalmazások mellett a high-end grafika terén is megállta volna a helyét és az elgondolások alapján 2009 körül került volna be integrált vezérlőként az Intel processzoraiba.
A chipgyártó végtelenül egyszerű x86 processzormagok tömegével képzelte el a nagy teljesítményű kódok párhuzamos végrehajtását, amelynek fejlesztéséről egy ideig semmit nem lehetett hallani. 2009-ben, tehát az eredetileg kitűzött megjelenés évében a vállalat 2010-re tolta el a premiert, majd később bejelentette, a projektet teljesen törölte. Ez azonban nem azt jelenti, hogy a Larrabee fejlesztésekor felhalmozott tudást kukázta volna a chipgyártó vállalat, csupán annyit, hogy a grafikus feladatok végrehajtására szánt x86-os chip kiadásáról letett, mivel az egyszerűen nem lett volna versenyképes az akkori GeForce és Radeon lapkákkal.
Grafikus vezérlőből HPC-gyorsító lesz
A GPU-gyártók akkor már erőteljesen mozogtak a mérnöki-tudományos alkalmazások irányába a GPGPU elgondolás kiterjesztésével, az Intel pedig felismerte, hogy ezek a pozícióit veszélyeztetik - amennyiben a számítások jó részét rá lehet bízni egy Tesla vagy FirePro kártyára, kevesebb Xeon fogy majd. A Larrabee projekt fókuszát ekkor fordították a mérnöki-tudományos alkalmazások felé végleg, és 2010-ben az Intel már nyíltan arról beszélt, készül egy sok, egyszerű x86 processzormagra épülő chipje, amely önálló bővítőkártyán lesz elérhető a nagy számítási teljesítményt igénylő feladatok gyorsítására.

A koncepció kísértetiesen hasonlít a GPGPU-k elgondolásához, azonban míg a GPGPU-kkal az NVIDIA és az AMD a grafikus chipek felől közelít az általános számítások felé, addig a Many Integrated Core projekt az Intel hagyományos területe felől, az általános célú x86 mikroprocesszorok oldaláról érkezik. A 45 nanométers, Knights Ferry kódnevű lapka végül 2011-ben érkezett meg, elsőként fejlesztői prototípusként, majd 2012-ben befutott a 22 nanométeres Knights Corner, amely Xeon Phi néven már kereskedelmi forgalomba is került - ilyenek gyorsítják a világ legnagyobb teljesítményű szuperszámítógépét, a Tianhe-2-t is. A Knights Corner 64 darab egyszerű, P54C-leszármazott (eredeti, MMX nélküli Pentium) x64 magot tartalmaz széles vektorizált (SIMD) kiterjesztéssel, 100 új utasítással és négy utasításszál párhuzamos végrehajtásának lehetőségével (Hyper-Threading).
Az Intel sem tagadja egyébként a GPGPU jelentőségét és potenciálját, mindazonáltal azt tartja, ezeknek a kártyáknak a hatékony programozásához új módszereket, új nyelveket és új fejlesztői eszközöket kell megismerni, ezzel szemben az x86-alapú "Knights" kártyákra a már évek óta jól bevált Intel fejlesztői eszközökkel (fordítókkal, debuggerekkel) lehet dolgozni, ami olcsóbbá teszi a folyamatot és egyszerűbbé a meglevő kódok adaptálását. Lényegében elég a kódban néhány extra sort elhelyezni ahhoz, hogy a korábban x86 processzorokon futtatott feladatok a bővítőkártyákon fussanak, jóval nagyobb sebességgel.
Knights Ferry: Xeon Phi a processzorfoglalatban
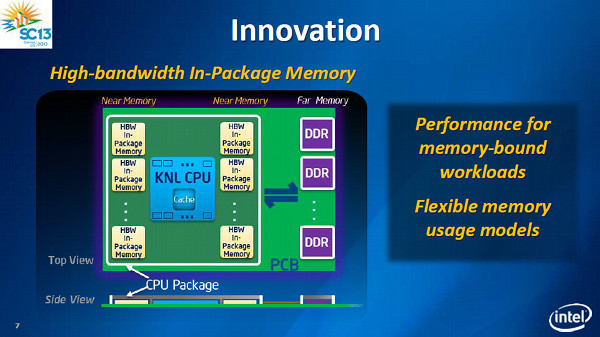
A bővítőkártyás megközelítés legnagyobb hátránya - és ez alól a Tesla és FirePro sem mentesek persze -, hogy a párhuzamos feladatvégzésre szánt kódot és az adatokat a rendszermemória és a kártya memóriája között folyamatosan másolgatni kell, ami lelassítja a műveletvégzést. Úgyhogy az Intel úgy döntött, a következő generációs Knights chipje, a már 14 nanométeres csíkszélességgel készülő, talán 2015-ben érkező Knights Landing szakít az eddigi koncepcióval és bővítőkártya helyett közvetlenül a processzorfoglalatba építhető kivitelben is hozzáférhető lesz.

Az AI ára Fizetnek a befektetők, fizetnek a felhasználók, és nagy árat fizet az IT munkaerőpiac is. Vékony jégen járunk. Itt a 85. kraftie adás.
Egyelőre nem nyilvános,a Knights Landing pontosan hány és milyen processzormagot tartalmaz majd, a HWSW úgy tudja, 72 darab Silvermont-alapú CPU dolgozik a lapkán out of order lebegőpontos egységgel és 512 bites AVX kiterjesztéssel. Azt azonban nyilvánosságra hozta a gyártó, hogy a lapka háromrétegű memóriaarchitektúrát alkalmaz: az első réteget a magonként dedikált, a szilícium szintjén integrált cache jelenti, a Knights Ferry esetében ez egyébként magonként 32+32 kilobájt elsőszintű 512 kilobájt másodszintű gyorsítótár volt. A második réteget a Knights Landing esetében a chip tokozásába integrált, nagy sávszélességű memória jelenti, a harmadik pedig a rendszermemória.
A processzorfoglalatba illeszkedő lapkának közvetlen hozzáférése lesz a rendszermemóriához, így elvileg tovább nőhet a teljesítménye, nem lesz szükség az adatok másolgatására a kártya és a rendszermemória között, amivel kikerül a képletből a memória, a PCI Express és a hálózat késleltetése is. Ezzel a megközelítéssel azonban egy másik probléma keletkezik: a ma és a közeljövő szervereiben használt DDR3 memória távolról sem olyan gyors mint a bővítőkártyákra épített GDDR5, így egy másik szűk keresztmetszet kerül a rendszerbe, amint az Intel a fenti memóriaarchitektúrával, illetve állítólag hatcsatornás DDR4 memóriavezérlővel próbál segíteni.
Xeon Phi külső házban, optikai PCI Express interfésszel
Megváltást a gyorsabb memória (pl. DDR4) bevezetése mellett a jelenleginél gyorsabb kommunikációs interfészek hozhatnak. Az SC13-on az Intel azt is bejelentette, hogy a Fujitsuval együtt dolgozik egy optikai kommunikációs technológián, amely lehetővé teszi a számára, hogy a Xeon Phi lapkák egy különálló dobozban kapjanak helyet, elválasztva a szervertől, mégis úgy működhessenek, mintha közvetlenül az alaplapra csatlakoznának. Az Optical PCI Express (PCIe) technológiát a Fujitsu gyári RX200 szerverekkel tesztelte, ezekhez csatlakozott egy külső házban két Xeon Phi és több SSD, amelyeket a szerver operációs rendszere úgy kezelt, mintha közvetlenül csatlakoztak volna. A módszer segítségével akár 1U kivitelű vékony szerverekbe is "beépíthetők" a Xeon Phi gyorsítók, illetve az eljárás lehetővé teszi a szerverek memória- és diszkkapacitásának növelését is.