Magyarul is megtanítható a Google nyelvi értelmezője
Megnyitotta természetesnyelv-értelmező szoftverének forráskódját a Google, ezzel egy pillanat alatt sokkal feljebb tolta a kereskedelmi szoftverek számára a lécet. A SyntaxNet fejlett megoldás, immár bárki építhet rá.
A következő egy-két év minden bizonnyal a chatbotok, és egyéb, a természetes nyelven alapuló UI terjedéséről fog szólni, legyen az írásban vagy beszédben továbbított szöveg. Ahhoz azonban, hogy ezek a szolgáltatások jól működjenek és pontosan értsék az emberi kifejezéseket, szükség van egy ütős értelmező rétegre, mely a természetes mondatokat képes értelmezni, a backend számára értelmezhető gépi parancsokká szétbontani.
Ezt a réteget nevezzük NLP-nek (natural language processing), ebben kap fontos szerepet a most szabad szoftverré tett SyntaxNet. Ez egy komplex szintaktikai feldolgozó (parser), mely a bemeneti szöveget neurális háló segítségével igyekszik elemeire bontani, az elemeket azonosítani, megkeresni a közöttük lévő kapcsolatot, majd ezt az egész információhalmazt átadni a feldolgozó futószalag következő elemének (például a keresőmotornak vagy a parancsot végrehajtó más backendnek).
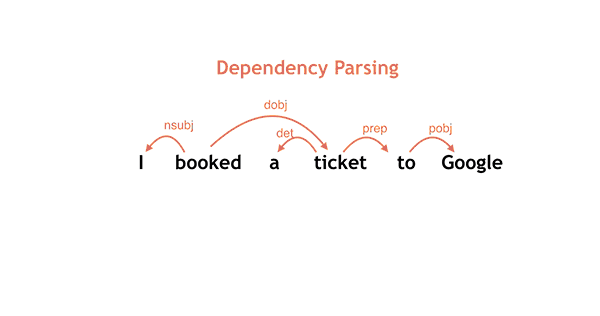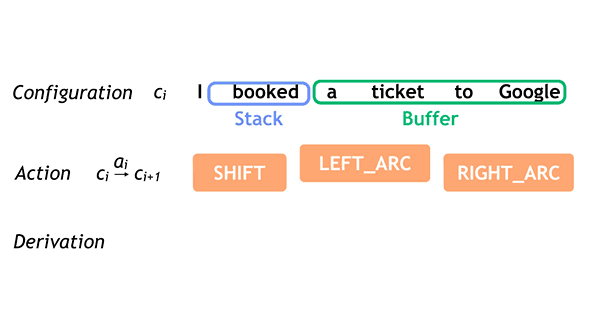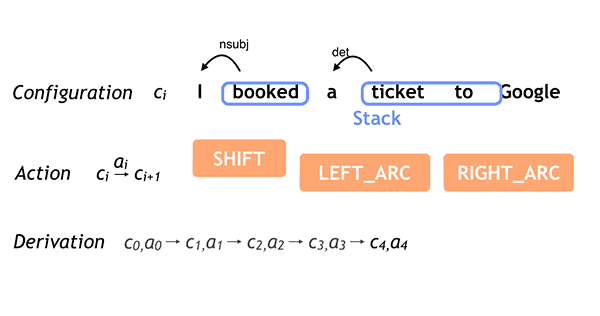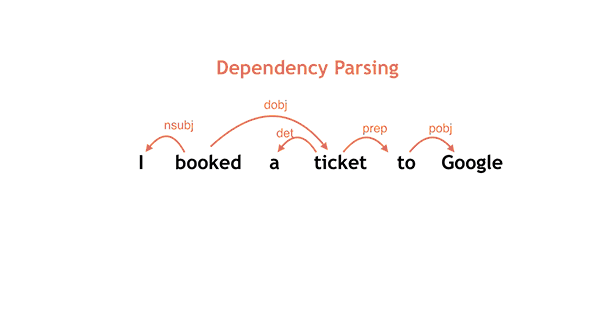
A gyakorlatban ezt úgy kell elképzelni, hogy a feldolgozó fogja a mondatot, megkeresi benne a különböző mondatrészeket (alany, állítmány, stb.), majd relációs rendszerbe helyezi ezeket. Ez roppant egyszerűen hangzik, az emberi nyelv (különösen a beszélt nyelv) azonban rengeteg kétértelműséget tartalmaz, ráadásul a rövidítések, szókihagyások, szófordulatok teljesen fel tudják borítani az algoritmust. Itt jön be a gépi tanulás, esetünkben a neurális háló, amely segít eldönteni, hogy az alábbi példában szardellával ették a pizzát, vagy szardellás pizzát ettek:
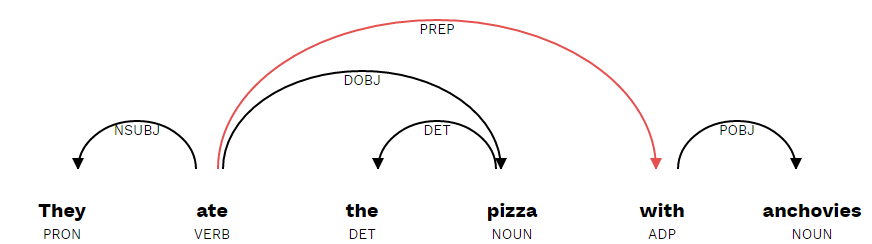
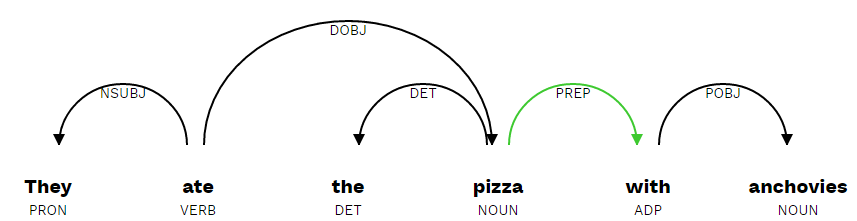
Triviális feladat az embernek, a gépnek viszont problémás (forrás)
Lejjebb került a léc
De miért nyitja meg a Google a szoftver forráskódját és teszi azt szabadon elérhetővé mindenki számára, ha ez a technológia annyira fontos lesz a jövőben? A döntés szépen illeszkedik a cég régóta követett stratégiájába, az "előző generációs" technológiákat hagyományosan szabad szoftverré teszi, így segítve annak terjedését, másrészt meggátolva, hogy a versenytársak bevételt szerezhessenek saját hasonló fejlesztéseikből - és egyúttal be is izzítva az innovációt a területen.
Találkozzunk, idén is lesz SYSADMINDAY! Július 17-én lesz a hazai Sysadminday! Standup, üzemeltetői meetup, kvízek, szakmázás, barátok, még több sörcsap.
Erre jó példa korábban a MapReduce "felszabadítása" - ez a technológia korábban a Google keresőmotorjának alapját jelentette, majd miután a cég továbblépett egy következő generációs megoldás felé, a MapReduce-t kiadta szabad szoftver formájában. Ez a lépés valósággal felrobbantotta az adatfeldolgozás és üzleti analitika piacát, amelyet mára jobbára a MapReduce-implementációk (mint a Hadoop) uralnak, a megoldás pedig de facto szabvánnyá vált a területen. A SyntaxNet, és az alatta dolgozó Tensorflow deep learning rendszer megnyitásával is hasonló csapást mért a Google, ezúttal épp a gépi tanulás területére.
Itt a magyar lehetőség?
Van a hírnek egy érdekes más vonatkozása is: a SyntaxNet nyelvfüggetlen, tetszőleges nyelvre megtanítható, ha elegendő nyers adatot etetünk meg vele. A Google ugyan a SyntaxNettel párhuzamosan elérhetővé tette az angol modult, Parsey McParseface néven, de semmi akadálya nincs annak, hogy az algoritmus más nyelveken is megtanuljon. Ez elképesztően fontos, ugyanis éppen most nyílik az új digitális szakadék a kis nyelvek és a nagy nyelvek között - utóbbiak esetében (nyilván) sokkal kifizetődőbb a munkaigényes tanítást elvégezni. Pontosan emiatt nincs például Cortana Magyarországon, és a Microsoft nem is tervezi, hogy elindulna a szolgáltatás magyarul. A SyntaxNet azonban akár közösségi összefogással, akár (kényszerűségből) állami szerepvállalással is megtanulhat magyarul, az így nyert modul pedig minden SyntaxNetre épülő szolgáltatásba bekerülhet.