Ütőképes lett az AMD Shanghai
Hivatalosan is útjára indult az AMD következő generációs szerverprocesszora, az AMD Shanghai. A négymagos Opteron chip bár nem vonultat fel jelentős architekturális újításokat, a gyártástechnológiai ugrásnak köszönhetően drasztikus előrelépést jelent.
Új gyártástechnológia
Ha le kívánjuk egyszerűsíteni, akkor a Shanghai lényegében egy Barcelona, csak minden téren számottevően jobb nála -- olyan, amilyennek a Barcelonának mindig is lennie kellett volna. Az új chip az AMD első, 45 nanométeres csíkszélességű eljárással előállított processzorra, és ebben gyökerezik a jelenlegi 65 nanométeres generációval szembeni minden előnye is. A finomabb geometriájú gyártástechnológia magasabb kapcsolási sebességű, vagy adott sebességen alacsonyabb fogyasztású tranzisztorokat eredményez, aminek köszönhetően energiahatékonyabb chipeket képes előállítani az AMD. A Shanghai-on az AMD sunnyvale-i és bostoni tervezőcsapatai dolgoztak tandemben, a projekt kezdetetétől a szállításokig mintegy két és fél év telt el mindössze -- rendkívül rövid idő egy ilyen komplexitású chip esetében, nem véletlen, hogy az AMD igazi sikertörténetként könyvelte el.
A 65 nanométereshez képest nagyjából fele akkora struktúrákat, és harmadával kisebb áramköröket, gyorsabb kapcsolást és energiahatékonyabb működést lehetővé tévő 45 nanométeres immerziós litográfiájú eljárás egyelőre páratlan a félvezetőiparban. Az IBM-mel karöltve az AMD olyan, tömegtermelésben alkalmazható levilágítási technikát dolgozott ki, amelynél a fényforrás és a szilíciumszelet közötti optikai vezetőközeg nem levegő (száraz litográfia), hanem víz. A rendkívül magas tisztaságú víz litográfiai refraktív indexe 1,4, vagyis ennyivel lassul le a fény a vízben -- mivel lerövidül a hullámhossza, így a terjedési sebessége is mérséklődik. A levegő refraktív indexe lényegében elhanyagolható, 1,0003.
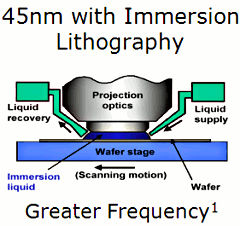 A rövidebb hullámhossz pedig nem jelent mást, mint nagyobb felbontási képességet, vagyis a finomabb struktúrák kialakításának képességét. Az iparágban jelenleg tömegesen alkalmazott 193 nanométeres fényforrásokat vizes immerzióval 138 nanométeres effektív hullámhosszra lehet fókuszálni. Bár az immerzió új és költséges litográfiai berendezések beszerzését követeli meg, és egy levilágítás is költségesebb, a 45 nanométeres generációnál még nincsen szükség egyelőre olyan trükközésekre, mint a többszörös levilágítás eltolt maszkokkal, amit az Intel is alkalmaz saját 45 nanométeres eljárásában -- két menet, kétszeres költség. Emiatt az AMD költségbeli előnyt élvez, véli Rolf Stephan, az AMD technológiai részlegénél a tranzisztorok kialakításáért felelős menedzser.
A rövidebb hullámhossz pedig nem jelent mást, mint nagyobb felbontási képességet, vagyis a finomabb struktúrák kialakításának képességét. Az iparágban jelenleg tömegesen alkalmazott 193 nanométeres fényforrásokat vizes immerzióval 138 nanométeres effektív hullámhosszra lehet fókuszálni. Bár az immerzió új és költséges litográfiai berendezések beszerzését követeli meg, és egy levilágítás is költségesebb, a 45 nanométeres generációnál még nincsen szükség egyelőre olyan trükközésekre, mint a többszörös levilágítás eltolt maszkokkal, amit az Intel is alkalmaz saját 45 nanométeres eljárásában -- két menet, kétszeres költség. Emiatt az AMD költségbeli előnyt élvez, véli Rolf Stephan, az AMD technológiai részlegénél a tranzisztorok kialakításáért felelős menedzser.
A nagyobb felbontás ellenére az AMD ráadásul alacsonyabb (területre vetített) meghibásodási sűrűséget ért el 45 nanométeren, mint a 65 nanométeres technológia életciklusának hasonló szakaszában, állította Stephan, ami a 45 nanométeres technológia optimalizálására fordított hosszabb időnek köszönhető, magyarázta a HWSW kérdésére a szakember. Ez pedig magasabb kihozatalt, vagyis olcsóbb és nagyobb volumenű termelést tesz lehetővé.
A 45 nanométeres, negyedik generációs feszített szilíciumot használó tranzisztorokkal adott fogyasztásból nagyjából 10 százalékos teljesítménynövekedés valósítható meg, míg ugyanaz a teljesítményszint 25 százalékkal alacsonyabb fogyasztással is elérhető az AMD számításai szerint. Mindez lehetővé tette az cég mérnökei számára, hogy olyan nyitófeszültségű tranzisztorokat alkalmazzanak a Shanghai elektronikai implementációjánál, melyekkel a vezetőrétegek vékonyodása ellenére is szinten tartsák, vagy opcionálisan akár töredékére szorítsák le a szivárgási áramot, ami különösen a hatalmas L3 cache esetében kritikus. A Shanghai 6 megabájtra növelte a harmadszintű tár méretét, több mint 250 millióval 750 millió fölé emelve az integrált tranzisztorok számát, amiből csak az L3 cache 400 milliónál is több tranzisztort emészt fel. Shanghai áramköri blokkjait 11 rétegű fémhuzalozás köti össze egymással és a külvilággal.
 Minimális csiszolás
Minimális csiszolás
A miniatürizáció mellett természetesen nem maradt az architektúra sem teljesen érintetlen, bár a változások a magok szintjén lényegében elhanyagolhatóak. Megjelent a támogatás a DDR2-800-as memóriamodulokhoz, valamint ahogyan az előbb említettük, 2 megabájtról 6 megabájtra növekedett az L3 cache mérete, ami egyértelműen a legfontosabb architekturális fejlesztés. A Shanghai koherens HyperTransport 3 szabványú kommunikációra is képes ugyan, ehhez azonban csak 2009 második felére érkezik meg a rendszerszintű tűmogatás.
A Shanghai már képes az egyik mag L1 és L2 tárait kiírni az L3-ba, és lekapcsolni azt (Smart Fetch), energiát takarítva meg, valamint a továbbfejlesztett virtuális memóriaindexelésnek köszönhetően gyorsult a virtuális gépek közötti váltás sebessége (Enhanced Rapid Virtualization Indexing). Az új chip továbbá fel tudja térképezni az L3 cache meghibásodott részeit, amit az operációs rendszernek támogatnia kell, így egyelőre inaktív a képesség (Cache Index Disable).
Az 58 százalékkal több tranzisztor ellenére a fejlettebb félvezetőeljárásnak és az elektronikai optimalizációnak köszönhetően az AMD nyitáskor 2,7 gigahertzes órajelet képes felmutatni, 17,4 százalékkal magasabbat a Barcelonánál, ugyanakkora, 95 wattos energiakeret (TDP) mellett. Sőt, az AMD állítása szerint egy Shanghai-alapú rendszer 10 százalékkal kevesebb energiát fogyaszt teljes terhelésnél, és harmadával kevesebbet üresjáratban, miközben Java szerverfeladatok (SPECjbb2005) alatt például 35 százalékkal magasabb teljesítményt ad le a magasabb órajelnek és megnövelt L3 tárnak köszönhetően -- ez éppen 50 százalékkal hatékonyabb energiafelhasználás.
[oldal:Remek teljesítmény -- de mégsem ez számít?]
Mindez kiválóan mutat papíron, de mint tudjuk, az elmélet és a gyakorlat között csak elméletileg nincs különbség, gyakorlatilag van. Európa második legnagyobb webhoszting cége, a német STRATO egy berlini adatközpontjában tartott demonstrációban a 2,6 gigahertzes Shanghai rendszerek 42 százalékkal magasabb http-kiszolgálási teljesítményt nyújtottak (Linux/Apache/MySQL alatt) az alacsony-feszültségű, 1,9 gigahertzes HE (High Efficiency) Barcelonákkal szemben, miközben csak 5 százalékkal több energiát fogyasztottak. Ez 35 százalékkal magasabb energiahatékonyság, pedig az összevetés ezúttal nem a Shanghainak kedvezett.A számítás- és memóraintenzív HPC/munkaállomás-kódokat felvonultató SPEC CPU2006 tesztcsomagban a Shanghai teljesítménye a megnövekedett órajel és háromszorosára emelt L3 cache miatt jelentősen felülmúlja a Barcelonát. Kétutas rendszerben integer műveletek terén (SPECint_rate_base2006) elődjénél átlagosan 27,6 százalékkal, a lebegőpontos számításokban (SPECfp_rate_base2006) több mint 30 százalékkal ad nagyobb teljesítményt -- minden mérés Novell SUSE Linux Enterprise Server alatt történt 2.6.16.46-0.12-smp kernellel. A HyperTransport 1 linkek telítődése miatt már érezhetően romló skálázódású négyfoglalatos rendszerben ennél moderáltabb, 18-20 százalékos teljesítménynövekedést mutat SPEC CPU2006.
SPECint_rate_base2006, 2 processzoros rendszerek teljesítménye a Barcelonához viszonyítva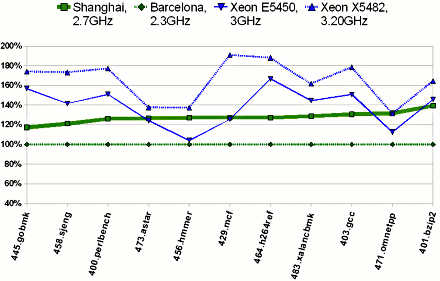
Ennek eredményeként drasztikusan javult versenyképessége a Xeonokkal szemben. A 2,7 gigahertzes Shanghai-jal (Opteron 2384) hasonló árkategóriába és fogyasztási osztályba tartozó 3 GHz-es Xeon E5450-nel szemben a Barcelona kétutas rendszerekben minden integer kód alatt kikapott lényegében, addig a Shanghai tizenegyből ötnél partiba került vagy felülmúlta azt. A lebegőpontos műveleteknél 17 kódból 13-nál már maga mögé utasítja az Intel-féle riválist. A rendszerarchitektúra jobb skálázódásának köszönhetően négyfoglalatos rendszerekben szokás szerint tovább javul a négymagos Opteron versenyképessége, átlagosan rendre több mint 15 és 75 százalékkal múlja felül a Shanghai a Tigertonokat integer és lebegőpontos számításokban. Az Európában eladott szerverek háromnegyede kétfoglalatos gép, a négyutas konfigurációk aránya 5 százalék alatti az IDC számai alapján.
SPECfp_rate_base2006, 2 processzoros rendszerek teljesítménye a Barcelonához viszonyítva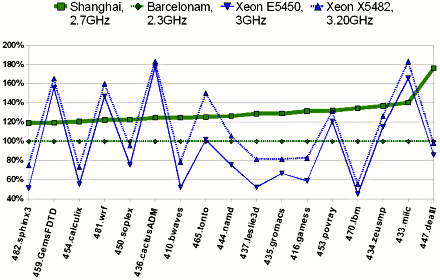
Az órajelnek és masszív gyorsítótárnak hálás Java szerverfeladatok alatt, melyek eddig a Xeonok erősségének számítottak, váratlanul nagy előrelépésnek mutatkozik a Shanghai. A gyorsulás mértéke 50 százalék felett is lehet a JVM finomhangolásával együtt. Az IBM előzetes adatai alapján egy Shanghai-alapú négyfoglalatos szerver eléri egy nyolcfoglalatos Barcelona-rendszer teljesítményét annak skálázódási korlátai miatt, és a korábban a Barcelonát magabiztosan verő Xeonokat is több mint 10 százalékkal képes felülmúlni. Ez az előny tovább fokozódik négyutas konfigurációkban, a szűkös rendszerbuszokon eléhező hatmagos Dunningtont (Xeon 7400-as sorozat) akár 35 százalékos előnnyel hagyja maga mögött Java-szerverfeladatokban a Shanghai, miközben a processzorok 20 százalékkal olcsóbbak.
Látható tehát, hogy a számításintenzív feladatok alatt ütőképessé tornázta magát az AMD, és az integrált memóriavezérlő miatt természetszerűleg alacsonyabb késleltetésű memóriahozzáférései és a megnövelt L3 cache hatására tipikusabb, tranzakcionális jelleget mutató szerverfeladatok alatt méginkább versenyképesnek ígérkezik -- a pontos eredményekre még várni kell a szerverszállítók részéről.
Frisstítés: Az eddigi egyetlen sztenderd virtualizációs benchmark, a VMark alatt a Shanghai 20 százalékkal nagyobb teljesítményt mutat a magasabb fogyasztású és drágább, 3,33 gigahertzes Xeon X5470-nél is, míg négyfoglalatos rendszerben gyakorlatilag lemossa a négymagos Tigertonokat (Xeon X7350, 2,93 GHz, 2x6 MB L2) a pályáról, több mint 40 százalékkal nagyobb virtualizációs teljesítményt mutatva, de maga mögött képes tartani a hatmagos Dunningtont is (X7460 2,66 GHz, 3x3 MB L2, 16 MB L3).
Eközben a Shanghai rendszerek fogyasztása jóval alacsonyabb az FB-DIMM memóriamodulokat használó Xeon konfigurációkénál, a normál DDR2 memóriával szereltekkel pedig lényegében azonos szinten mozog adott teljesítmény mellett-- a pontos összevetéshez azonban eddig nem állnak rendelkezésre megfelelő mérések, az eltérés ugyanakkor nem tűnik szignifikánsnak.
AMD: nem a teljesítmény, hanem a spórolás a lényeg
Ennek ellenére az AMD a Shanghai bejelentésekor egyáltalán nem a teljesítményre helyezte a hangsúlyt, alig beszélt róla, ami elsőre talán furcsának hathat, ugyanakkor egy nagyon is tudatos kommunikációs húzás. Bár a Shanghai jelenleg, és a következő egy negyedévben az újabb modellek megjelenésével kedvező színben tűnne fel nyers teljesítménybeli szempontból, ostobaság volna az AMD részéről megfeledkezni arról, hogy a jelenlegi ismeretek szerint nagyjából március magasságában érkezik az Intel Xeonok következő generációja, a Nehalem-EP. A Nehalem lényegesen erőteljesebb felépítésű, és többszálú végrehajtással (Hpyer-Threading) felvértezett magjai az új, integrált memóriavezérlővel és koherens pont-pont processzor-összeköttetéssel kombinálva bődületes teljesítménybeli ugrást garantálnak a jól párhuzamosított szerverfeladatok többsége alatt.
Az AMD-nek tehát a teljesítmény helyett másra kell helyeznie a hangsúlyt, amihez perverz módon nagyon is kapóra jött a gazdasági válság elmélyülése és globális kiterjedése. Leslie Sobon, az AMD termékeinek globális marketingjéért felelős igazgató a berlini rajton kijelentette, hogy a jelenlegi körülmények közepette nem megfelelő az idő egy teljesen új architektúra bevezetésére, nyilvánvaló utalást téve a tetőtől talpig megújuló, és teljesen új rendszereket és szoftveroptimalizációt is megkövetelő Nehalemre. Az AMD szerint a jelenlegi infrastruktúra életciklusának megnyújtására van szükség.
"Ez nem a megfelelő idő az architekturális váltásra, ami kockázatokkal jár" -- fogalmazott Sobon. "Egy növekedésorientált gazdaságból a megtakarítás felé fordulóba lépünk át. Az ügyfelek magas virtualizációs teljesítményt és a lehető legalacsonyabb áramfogyasztást igénylik üzletileg kritikus alkalmazásaik futtatásához" -- mondta az igazgató. Hangsúlyozta, a Shanghai az egyetlen x86-processzor jelenleg a piacon, mellyel a chipek cseréjével felfejleszthetőek a már üzemben lévő 2-8 utas rendszerek, és ugyanennek köszönhető, hogy még idén hozzáférhetőek lesznek a szerverszállítók gépei az új Opteronokkal.
A jövő: Fiorano, Maranello, Magny-Cours
Hogy ez több legyen hangzatos szavaknál, az AMD a jövő év vége felére időzített hatmagos, Istanbul kódnéven ismert Opteronját is elérhető teszi a jelenlegi Socket F infrastruktúrába, így gyakorlatilag 2010-be nyújtva ki annak életciklusát, miközben megkezdi a Fiorano, majd később a teljesen új, multi-chip tokokat is fogadni képes G34 foglalattal rendelkező Maranello bevezését -- 2010-ben érkezik a tizenkétmagos Magny-Cours, mely két hatmagos chipet egybetokozásával születik.
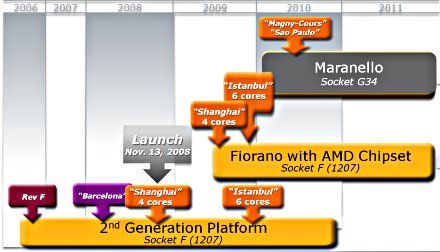
A következő negyedévben az AMD megkezdi a magas energiahatékonyságú HE , és a csúcsteljesítményű SE sorozatok szállításait is a jelenlegi 2,3-2,7 gigahertzes mainstream modellek mellett. A következő két év érdekesnek ígérkezik az x86-szerverpiacon, hiszen az első negyedév végére várhatóak a Nehalem-EP Xeonok, majd néhány hónappal később érkezik az AMD Fiorano, mely már lehetővé teszi a korábbinál alacsonyabb késleltetést és magasabb sávszélességet lehetővé tévő koherens (processzorok összekötését szolgáló) HyperTransport 3 linkek használatát, tovább javítva a 2-8 utas rendszerek teljesítményét.
Az év vége felé az Intel nyolcmagos Xeon MP-k formájában bemutatja a 4- vagy többutas renszerekbe szánt Nehalem-EX-et, más néven Becktont, és nagyjából ezidőtájt jelenik meg a hatmagos AMD Istanbul is. Kérdéses, hogy processzorgyártók tudják-e tartani termékterveiket, de amennyiben igen, úgy lényegében félévente fordulhat a kocka egy-egy szegmensben. Az Intel és az AMD felváltva kerülhet lépéselőnybe a kettő vagy a négyutas szerverek piacain, ahogyan az Intel erőteljesebb mikroarchitektúráját és a Hyper-Threadinget másfélszer több maggal igyekszik ellensúlyozni az AMD -- pont úgy, ahogyan a Dunningtonnal próbálja jelenleg az Intel a Shanghaijal felvenni a harcot, az utolsó cseppet is kisajtolva az erősen korlátolt, buszrendszerű architektúrájából.