Microsoft SQL Server Yukon bemutató
A Yukon kódnéven emlegetett Microsoft SQL Server 2005 hatalmas ugrás az előző verzióhoz képest, gyakorlatilag minden alkalmazási területén jelentős mennyiségű új szolgáltatással bővült, legyen szó akár általános célú adattárolásról, üzleti alkalmazások fejlesztéséről, vagy komplex elemzések készítéséről.
A Yukon hatalmas ugrás az előző verzióhoz képest, gyakorlatilag minden alkalmazási területén jelentős mennyiségű új szolgáltatással bővült, legyen szó akár általános célú adattárolásról, üzleti alkalmazások fejlesztéséről, vagy komplex elemzések készítéséről.
Az SQL Server Workbench kezdőképernyője
Jelenleg a rendszer béta 1-es változata érhető el, ami még nem tartalmaz minden funckiót, és természetesen hibamentessége sem garantálható, viszont jó képet ad arról, hogy mire is számíthatunk a dobozos termék esetében. A tényleges, széles kör bevonásával folytatott tesztelés a béta 2 megjelenésével kezdődik majd el.
A cikk két részben foglalkozik a szoftverrel: első felében átfogó képet nyújt a rendszer új szolgáltatásairól, míg a második felében inkább a fejlesztőket és az adatbázis-karbantartással foglalkozó szakembereket célozza meg a Yukon képességeinek részletes bemutatásával.
[oldal:Felület, alkalmazások]
A Yukon olyan képességekkel rendelkezik, amelyek jelentősen megkönnyítik a fejlesztési és karbantartási feladatok elvégzését, ezenfelül az SQL Server 2000 szinte valamennyi kényelmetlenségére és hiányosságára megoldást kínál.
A felhasználói felületet teljesen átszervezték, a megszokott Enterprise Manager és a Query Analyzer helyett szinte minden egy helyről, az SQL Server Workbenchből érhető el, ami a Visual Studio IDE-re épül. Ez a megoldás a fejlesztők számára nagyon előnyös, mivel a megszokott felületen keresztül programozhatnak és adatbázist is tervezhetnek. Az adatbázisokat karbantartó adminisztrátoroknak azonban kényelmetlen lehet átszokni egy teljesen új GUI-ra.
Az SQL Server Workbench használat közben
Azok a funkciók, amelyek nincsenek szoros kapcsolatban az adatbázis karbantartásával és fejlesztésével, a Business Intelligence Workbenchben érhetőek el; ilyen például az Analysis Services, a Reporting Services és a Data Transformation Services, amik mind adatbázis-orientált üzleti megoldások fejlesztését segítik elő.
Az SQL Profiler ebben a verzióban is külön alkalmazásként található meg, ezzel fedezhetőek fel legegyszerűbben az SQL Server által futtatott kód hibái. Az adatbázis, és a benne található SQL-ek optimalizálására használható a Database Tuning Advisor, ami a táblákhoz megpróbálja a legoptimálisabb indexeket létrehozni, illetve a meglévő trace logok (eseménynaplók) alapján új táblák, és egyéb adatbázis-objektumok létrehozásának, illetve egyes beállítások megváltoztatásának szükségességére hívja fel a figyelmet.
Az SQL Server Workbenchben a leggyakrabban használt funkciók egyetlen gombnyomással elérhetőek, és az adatbázissal kapcsolatos feladatokat, kapcsolatokat, lekérdezéseket egy project létrehozásával egyszerűen össze lehet gyűjteni. A project objektumai a Visual Studióból már ismert Properties ablakon keresztül is módosíthatóak.
A Database Tuning Advisor
A programokban található ikonok és grafikák szinte kivétel nélkül módosultak, sokkal plasztikusabb hatást keltenek, leginkább az Office 2003 és a Windows XP felületét idézik. Minden lekérdezés-ablakhoz külön megadható, hogy az eredményt a képernyőre, adatrácsba, vagy fájlba szeretnénk kapni, és lehetőség van az SQL Execution Plan és az SQL lefutásakor keletkező trace üzenetek kiíratására is -- mindezek nem jelentenek újdonságot, azonban az új verzióban könnyebben, egy helyről elérhetőek az SQL lekérdezésekkel kapcsolatos beállítások.
Minden GUI-ból elérhető funkció végrehajtása, amely az adatbázis objektumainak megváltoztatásával jár, időzíthető későbbi időpontra, és akár az is megoldható, hogy az azonnali lefuttatás helyett, csak a módosításhoz szükséges SQL-t adja vissza a rendszer.
[oldal:Szolgáltatások]
A Yukon többféle szolgáltatást is nyújt kimutatások, elemzések, illetve az adatok különféle formában történő megjelenítésének és elmentésének megvalósítására. Ezek többsége a Business Intelligence Workbenchből érhető el.
A Reporting Services egy hónapja elérhető az SQL Server 2000-hez is, mint önállóan telepíthető kiegészítés, de a Yukonnak már szerves része ez a modul. Ez a szolgáltatás lehetővé teszi kimutatások készítését, azok közös felületről történő biztonságos elérését, terjesztését, és felügyeletét. A Reporting Services többek között képes HTML, XML, Word, Excel, és PDF formátumokban is elmenteni a kívánt adatokat.
A Reporting Services API-n keresztül saját kimutatás-formátumokat is létre lehet hozni, továbbá az adatfeldolgozás és a kimutatás elkészítésének folyamatába is van beleszólási lehetőségünk a programozási nyelvek szintjén. A forrásadatok származhatnak Microsoft SQL Serverből, az Analysis Servicesből, Oracle adatbázisokból, és .Net Data Providereken keresztül elért más adatforrásokból is, például ODBC, vagy OLE DB használatával.
A webre készített kimutatásokat dinamikus tulajdonságokkal, paraméterekkel is fel lehet ruházni, vagyis sokkal egyszerűbben juthatunk a keresett információhoz egyszerű szűkítések, rendezések, és átalakítások segítségével, mint egy statikus, minden esetben változatlan tartalmat mutató dokumentum esetében.
A Business Intelligence Workbench, és egy Reporting Project
A Data Transformation Services szinte teljesen ki lett cserélve a Yukonban. Korábban nagyon limitált eszközök voltak a fejlesztő kezében, hogy az adatok áramlásának, formálódásának menetébe beleszóljon. A Yukonban, az új DTS architektúra részeként megjelent a DTS Designer, rendelkezésre áll számtalan előre definiált adattranszformációs lépés, és egyszerűbbé vált a csomagok kezelése és telepítése. A Yukon DTS-e különválasztja egymástól az adatok áramlását, és a vezérlés menetének irányítását. Az elsőért a DTR (Data Transformation Run-time), míg a másikért a DTP (Data Transformation Pipeline) felel. Ez a szétválasztás átláthatóbbá teszi az adattranszformációs folyamatokat.
A DTS belső működése, felépítése is át lett alakítva, hogy könnyebben testreszabható és korlátlanul továbbfejleszthető legyen. Ennek eszköze az Extensible Object Model, aminek hála bármely .Net keretrendszerben elérhető programozási nyelven írhatunk saját feladatokat és átalakításokat a DTS-ben történő felhasználásra.
Az SQL Server Yukonban megtalálható modulok
Az Analysis Services a Yukonban már képes triggerek és tracek létrehozására, ezáltal értesítést kaphatunk az általunk megadott validációs kritériumok teljesülésekor. A trace megvalósítása aszinkron felületet biztosít a teljesítményadatok, és más, főként problémamegoldással kapcsolatos információk naplózására. Az XML-alapú Object Definition Language (ODL) felhasználásával bármely Analysis Services adatbázis, objektum, vagy tevékenység tetszőlegesen testreszabható, átprogramozható. Az SQL Server Workbenchből elérhetőek az Analysis Services adatbázisok, és annak szinte minden tulajdonsága erről a grafikus felületről is kényelmesen állítható, valamint scriptek is készíthetőek és futtathatóak innen.
Az Analysis Servicest már lehet egy számítógépre több példányban is telepíteni, ezáltal nem probléma többé, ha egy szerveren több alkalmazás is használja az elemzőmotort a saját beállításaival, kiegészítéseivel. Ezzel a megoldással a migráció is egyszerűbben, a hibalehetőségek lecsökkentésével végezhető el.
A rendszerben megoldották, hogy webről érkező, stateless (állapot nélküli) lekérdezések is használhassák az Analysis Servicest. A stateless módszer előnye, hogy kötegelt lekérések lefuttatása esetén sem jelent problémát az Analysis Servicesre nyitott kommunikációs csatorna megszakadása, vagy a szolgáltatás, illetve az annak otthont adó hardver leállása. Hibák esetén a kliensalkalmazás, vagy a böngésző képes onnan folytatni a tevékenységét, ahol a hiba hatására abbahagyta.
Amellett, hogy tökéletesen skálázható, további előnye a stateless megvalósításoknak, hogy a lekérdezésekhez szükséges szálakat, objektumokat a rendszer egy közös poolban, vagy tárhelyen tartja. A korábbi lekérdezések által létrehozott objektumokat nem szabadítja fel rögtön, hanem új lekérdezések esetén újrahasznosítja, ha a két lekérdezés ugyanazt az objektumot használná. Ezzel a lekérdezések sebessége jelentősen növelhető.
Szintén újdonság a tárolt eljárások támogatása az Analysis Servicesben, amelyek bármely .Net programozási nyelven fejleszthetőek. A folyamatok teljesítménye Performance Key Indicatorok segítségével mérhető, így pontosabb képet lehet alkotni arról, hogy a megadott paraméterek, vagy tárolt eljárások közül melyek okoznak sebességproblémákat. Ha ez sem vezet eredményre, használható az SQL Server Profiler is az Analysis Services hibáinak feltárására.
A perspektíva és dimenziókezelés kapcsán elérhető funkciók száma közel a duplájára emelkedett, valamint elérhető a Naive Bayes algoritmus prediktív elemzések elvégzésére.
[oldal:Újdonságok az adatbázisban]
Az adatbázis motorjában is jelentős változtatások történtek. A korábbi rendszertáblák helyett a Yukon rendszernézeteket (catalog views) tartalmaz, amik ugyanazokat az oszlopokat tartalmazzák, mint a korábbi táblák, de sokkal optimálisabb módon lehet belőlük lekérdezni az elemeket. A nevük nem változott, ezért a korábbi verzióban készült adatbázisok ebből a szempontból kompatibilisek lesznek a Yukonnal.
A Yukonban négy új adattípus jelent meg, ebből kettő -- a korábbi datetime típussal ellentétben -- képes külön kezelni a dátumot (date) és az időt (time). Az utcdatetime típus használatával zónához szinkronizált időt lehet elérni, míg a negyedik típus, az XML segítségével az adatbázis motorja által értelmezhető XML adatok tárolása oldható meg. Utóbbi azért nagyon hasznos, mert az SQL lekérdezésekben az XML oszlopokból XQuery segítségével bármely darab kiolvasható, és ezért több sor XML oszlopainak együttes feldolgozásához nincs szükség cursorokra. Ezekben a lekérdezésekben az XQuery szintaktikája megengedi SQL oszlopok felhasználását is, például az sql:column("P.ProductID") beírásával, ami a P-vel elnevezett tábla ProductID oszlopát helyettesíti be az sql:column("P.ProductID") helyére. Ugyanígy megoldható SQL változók XML-ben történő felhasználása is az sql:variable() használatával. Az táblák XML típusú oszlopaira is lehet indexet létrehozni.
A futó folyamatok listája az SQL Server Workbenchben
Apróság ugyan, de kifejezetten szimpatikus, hogy a rendszer saját adatbázisai, táblái és a felhasználók által létrehozottak külön helyről érhetőek el, tehát nem zavarja a fejlesztőket az összes általában fölösleges objektum, tábla.
Jónéhány adatbázisszerverben már lehetőség van saját aggregát függvények létrehozására, és most már a Yukon is képes erre. Ezek a függvények megadott elemhalmazra egy visszatérési értéket határoznak meg, mint például a count, ami egyszerűen a megadott halmaz elemeinek a számát adja vissza. Bizonyos helyzetekben előnyös, ha saját magunk is tervezhetünk ilyen függvényeket, különösen akkor, ha olyan SQL típussal akarunk dolgozni, amelyre nem alkalmazhatóak a meglévő aggregátok.
Szintén nem világraszóló újítás a párhuzamos lekérdezések támogatása, de az SQL Server 2000 erre korábban nem volt képes. A MARS-nak (Multiple Active Result Sets) elnevezett technológia segítségével az egy adatbázis-kapcsolaton keresztül egyszerre futó lekérdezések eredményeit párhuzamosan is fel lehet dolgozni, anélkül, hogy bármelyik lekérdezést végig kellene várnunk a többi elkezdéséhez.
Az adatbázis státusza Emergencyre (vészhelyzet) is állítható. Ilyenkor az adatbázis csak olvasható állapotba kerül, és kizárólag a sysadmin role-ba tartozó felhasználók léphetnek be az adatbázisba, hogy megvizsgálják az esetleges hibákat az adatbázis megrongálásának veszélye nélkül. Amennyiben egy sysadmin user be szeretne lépni egy lezárt adatbázisba, ami amúgy nem engedélyez belépést, az "sqlcmd -a" parancs begépelésével megteheti. Ezt a belépést egy speciális, dedikált adminisztrációs kapcsolaton keresztül lehet elérni, amin keresztül az esetlegesen összeomlott adatbázison karbantartó műveletek is elvégezhetőek.
A korábbi SQL Server verziók képesek voltak a szerver rendelkezésre álló memóriájának méretét szabályozni, de csak a szerveralkalmazás elindulásakor meglévő memória méretének megfelelően. A Yukon futásidőben is képes észlelni a szabad memória méretének változását, és akár azonnal kihasználni azt.
Egy SQL Execution Plan - ez fut le az adatbázisban egy lekérdezéskor
Jelentősen gyorsabban dobhatóak el nagyméretű adattáblák és adatbázisok. A Yukonban bemutatkozik egy új tranzakciós szint is, a Snapshot. Ennek használatakor a tranzakció kezdete után a tranzakción belüli kód az adatbázis valamennyi objektumát változatlan állapotban látja, függetlenül attól, hogy a jelenlegi tranzakción kívüli műveletek írnak-e az adatbázisba. Az adott tranzakció egyedül a saját maga által létrehozott változtatásokat észleli. Ez a megoldás nagyon hatékony abban az esetben, ha a tranzakciónak konzisztens információra van szüksége, de nem akarja blokkolni az adatbázis általa nem módosított részeinek elérhetőségét.
Hasonlóképpen az adatbázis egészéről is készíthetőek view-k, amik az adatbázis egy adott pillanatban lementett állapotát tartalmazzák. Használatával egyszerűbbé válik egyes adatbázis-objektumok visszaállítása anélkül, hogy az egész adatbázist újra kéne építeni egy backupból. Az adatbázis replikációjára is több lehetőség kínálkozik, például a fürtözés helyett akár tükrözést is használhatunk már, amivel rendszeres időközönként egy backup szerverre menthető az adatbázis pillanatnyi állapota, és az eredeti szerver leállása esetén az új szerver elindítható. Ez a megoldás rendkívül olcsó, és mégis jelentősen növeli a rendszer üzembiztonságát. Az adatbázis backupok készítése és visszatöltése is sokkal hibatűrőbbé vált, az automatikus backup-tervek képesek a hardverhibákra rugalmasan reagálni, és alternatív lépéseket tenni, ha szükség van rá.
A Full-text Search szolgáltatással szöveges adatok keresésére alkalmas indexek hozhatóak létre DDL (Data Description Language) parancsokkal. A létrejött indexekről biztonsági másolatok ugyanúgy készíthetőek, mint az adatbázis adatfájljairól. A Yukon még egy szinonima-szótárat is felajánl arra az esetre, ha nem egy az egyben akarunk megkeresni egy kifejezést, hanem az ahhoz jelentésben hasonló szavakkal is megelégszünk.
A táblák, vagy nézetek indexei tartalmazhatnak olyan oszlopokat is, amelyek nem kulcsoszlopai az indexnek, ezáltal gyorsíthatóak azok a lekérdezések, amelyek az indexben mellékelt összes oszlopot vizsgálják, lekérik. Indexek és táblák esetében is megoldható az adatsorok partícionálása, amivel elérhető, hogy egy tábla vagy index tartalma külön fájlrendszeren vagy szerveren legyen tárolva. A Yukonban a használatban lévő objektumok indexei bármikor, bármekkora terheltség mellett módosíthatóak.
A Yukonban bármelyik DDL parancshoz köthetünk triggereket, amelyek az adott DDL parancs meghívódásakor szintén lefutnak, így minden adatbázis-módosulásról lehet értesülni és tetszés szerint reagálni rá. A DDL triggerek nem lehetnek INSTEAD OF triggerek, vagyis minden esetben először a DDL parancs, majd a trigger fut le. Ha a triggerből meg kell akadályozni egy DDL parancs lefutását, a triggeren belül meghívható a ROLLBACK eljárás, ami visszagörgeti a tranzakciót, és ezzel semmissé teszi a DDL parancsot is.
[oldal:Lekérdezések]
Az eredeti ANSI SQL szintakszishoz képest szinte minden adatbázisszerver nyújt egy-két saját kiegészítést, ami könnyebbé teszi az adatbázis fejlesztését, használatát, de pont a szabványtól történő eltérés miatt jelentősen nehezebbé válik a különféle adatbázisszerverek közötti migráció.
Az egyik ilyen új kiegészítés a rekurzív lekérdezések támogatása, amellyel könnyen megvalósíthatóak az amúgy komoly gondot okozó lekérdezések, méghozzá az SQL Server által optimalizált módon, mindenféle ideiglenes tábla és cursor kikerülésével. Ehhez a WITH foglalt szót kell használni, amely után megadható egy ideiglenes tábla oszlopdefiníciója. A WITH-en belül található lekérdezés megtölti a WITH után megadott táblát. A rekurzió eléréséhez csak annyit kell tenni, hogy a WITH-en belüli lekérdezésben hivatkozni kell a temporális tábla nevére. Mivel ezt nem túl egyszerű elképzelni, ezért érdemes a Yukon dokumentációjában is ismertetett példát áttekinteni:
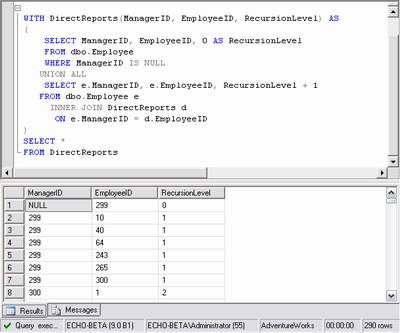
Ez a lekérdezés gyakorlatilag a jelentési láncot építi fel a vállalat adatbázisa alapján. A legelső lekérdezés a WITH-en belül kiválasztja azokat a legfelső szintű alkalmazottakat, akiknek nincs menedzserük, vagyis nincs senki, akinek jelentéseket kéne írniuk. Jelen esetben ilyen csak egy van, ő lehet a vállalat vezetője. A második, UNION ALL-lal hozzákapcsolt lekérdezés az előző lekérdezés alapján kiválasztja a következő szint alkalmazottait, akiknek az első szint felé van jelentési kötelezettsége. A WITH miatt a lekérdezés rekurzív módon addig folytatódik, amíg van olyan alkalmazott, akinek egy másik alkalmazott jelent. Az eredményben található RecursionLevel oszlop megmutatja, hogy a legfelső szinten található menedzserhez képest hány szint távolságra található a kérdéses alkalmazott. A WITH-es blokk utáni SELECT mindössze az ideiglenes, rekurzívan összeállított tábla tartalmát listázza ki.
A másik jelentős újítás a strukturált kivételkezelés megvalósítása az SQL nyelvben, amivel elkerülhető, hogy a hibákat szinte soronként ellenőrizni kelljen, és egyenként le kelljen kezelni a tranzakció visszagörgetését. Ha a BEGIN TRY és az END TRY közötti SQL blokkon belül bárhol hiba történik, a vezérlés átkerül a BEGIN CATCH (kivételtípus) - END CATCH blokkba, amennyiben a BEGIN CATCH után megadott típusba tartozik a kérdéses hiba. A CATCH blokkon belül egyszerűen lekezelhető például a tranzakció visszagörgetése, anélkül, hogy folyamatosan ellenőrizni kellene a tranzakció és a lefutott parancsok állapotát.
Megjelent három új relációs operátor is, az APPLY, a PIVOT és az UNPIVOT, amikkel az SQL lekérdezésekben szereplő FROM blokk utáni táblák kapcsolata határozható meg.
Az SQL-eket íróknak nagy segítség az OUTPUT kulcsszó megjelenése az INSERT, DELETE, és az UPDATE parancsokban, mivel eddig gondot jelentett, ha a ténylegesen beszúrt sorok értékére voltunk kíváncsiak. Ilyenre akkor lehet szükség, ha például egy beszúrás pillanatában még nem tudjuk, milyen azonosítóval fog bekerülni egy rekord, de utána pontosan azt az elemet szeretnénk módosítani, vagy felhasználni. Ekkor az OUTPUT után megadott paraméter automatikusan tartalmazni fogja a művelet által beszúrt sorokat, és ebből már könnyedén megállapítható, milyen értékeket vettek fel a kérdéses oszlopok.
Érdekesség, hogy akár másik SQL Serveren is futtathatóak SQL lekérdezések az EXECUTE használatával, ha utána AT szervernév-vel megadjuk egy regisztrált, linkelt szerver nevét. A szervert az sp_addlinkedserver tárolt eljárással lehet beregisztrálni.
[oldal:Integráció]
Míg az előző oldalakon található újdonságok az adatbázis működésével és fejlesztésével voltak kapcsolatosak, ezen az oldalon azokkal a funkciókkal, technológiákkal foglalkozunk, amelyek az adatbázis felhasználásával, céljával függnek össze. Elvégre mit ér egy adatbázis, ha csak a saját adminisztrációs felületén keresztül lehet használni? Az adattár, és a mögötte rejlő kód legfontosabb feladata, hogy tényleges helyzetekben, szoftvereken keresztül, vagy statisztikák, kimutatások útján tájékoztasson a minket érintő adatokról, változásokról. Ugyancsak lényeges, hogy lehetőség nyíljon az intenzív adatfeldolgozást igénylő üzleti logika adatbázisban történő hatékony programozására.
Az IBM és az Oracle szerverei már régóta támogatják a Java programozási nyelvet adatbázisaikban, ezzel ellentétben a Microsoft SQL Server a kezdetektől fogva inkább az adattárolásra koncentrált, valamint szorgalmazta az üzleti logika és az adattárolás szétválasztását. A Yukon egyesíti a két megközelítés előnyeit, és lehetővé teszi .Net-alapú programrészek felhasználását az adatbázisban, anélkül, hogy ezek a modulok az adatbázis szerves részét képeznék. Mint bármely másik .Net assembly, az adatbázisban használt objektumkönyvtárak is bármikor szabadon módosíthatóak, gyakorlatilag az adatbázis érintése nélkül. Ezáltal az SQL Server Yukon képessé vált negyedik generációs, procedurális, objektum-orientált nyelvek támogatására, amivel egyes feladatok sokkal egyszerűbben, hatékonyabban oldhatóak meg, mint SQL parancsok segítségével.
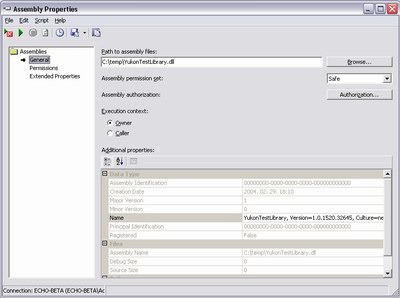
.Net Assembly fájlok karbantartása az adatbázisban
Az SQL Server 2000 másik fontos hiányossága az volt, hogy nem lehetett elegánsan, sem túl egyszerűen megoldani az alkalmazások értesítését, ha az adatbázis egyes részei megváltoztak. A legelterjedtebb stratégia ennek megoldására a minket érintő tábla, vagy objektum pollozása, vagyis folyamatos, adott időközönként történő ellenőrzése volt. A kevésbé elterjedt, de egyértelműen szebb megoldás OLE objektumokon keresztül, vagy Extended Stored Procedure-ökön keresztül kommunikált a külvilággal.
A Yukon többféle megoldást is nyújt erre a problémára. A .Net hostingnak hála, lehetőség van tetszőleges .Net keretrendszerben írt assembly betöltésére az adatbázisba, és az assembly függvényeit SQL tárolt eljárásoknak, triggereknek és függvényeknek megfeleltetni. Ettől kezdve akármelyik SQL-ből szabadon meghívható az általunk írt, külső kód, ami .Net assembly lévén már gond nélkül képes más programokkal, vagy az operációs rendszerrel kommunikálni. .Net-ből különféle context-oszályokon keresztül elérhetjük azokat az adatokat, amiket az SQL-ek megfelelő részein is elérhettünk, például egy insert trigger esetében az [inserted] ideiglenes táblát, amely a táblába beszúrt elemeket tartalmazza.
A .Net-alapú programrészletek felhasználását segíti, hogy az adatbázis képes a .Net-es típusok kezelésére, és akár saját .Net típusainkat is beregisztrálhatjuk az adatbázisba, amit ezután a táblák oszloptípusának is megadhatunk.
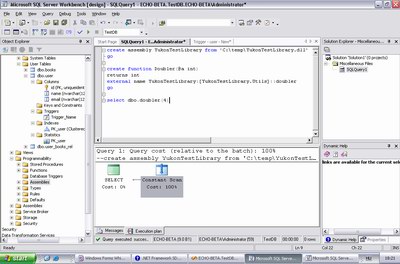
.Net Assemblyben lévő kód regisztrálása és meghívása SQL Server Yukonból
A második megoldás a kommunikáció problémájára a Notification Services használata, ami két éve már az SQL Server 2000-hez is elérhető. Segítségével az adatbázisban tetszőlegesen komplex feltételek teljesülésekor minden csatorna, ami regisztrálta magát a feltétel figyelésére, értesítést kap. Az értesítés előre megadott időközönként is érkezhet, függetlenül attól, hogy a megadott feltétel teljesült-e, valamint az is kivitelezhető, hogy ne érkezzen túl sűrűn értesítés ugyanarról az eseményről. Az értesítés érkezhet egyszerű programüzenet, e-mail, vagy akár HTML oldal formájában is; utóbbi esetben csak a linket küldi át a rendszer. A Notification Services nem alkalmas valósidejű alkalmazásközi kommunikációra, igazi feladata a végfelhasználók számára olvasható, időzíthető jelentéseket, üzeneteket küldeni.
A harmadik lehetőség a Service Broker képességeinek kiaknázása. A Service Broker egy rugalmas, hatékony és hibatűrő architektúra nagyobb méretű, adatbázisfüggő, elosztott programok készítésére. Gyakorlatilag az MSMQ (Microsoft Message Queuing) technológia által használt üzenet alapú kommunikációs modell és az SQL tranzakció-kezelésének összeépítéséből született.
Az MSMQ olyan kommunikációs architektúra, amely üzenetek segítségével kommunikál megadott csatornákon, úgynevezett "queue"-kon keresztül. Egy queue-ba a jogosult alkalmazások küldhetnek üzeneteket, és a queue-ra regisztrált alkalmazások elolvashatják, vagy ki is vehetik az üzenetek a csatornáról. A csatornában az üzenetek a FIFO (First In, first Out) elvnek megfelelően kezelhetőek, azaz az üzenetek sorrendtartóak.
Legnagyobb előnye, hogy az üzenetek nem tűnnek el, akkor sem, ha a küldő, vagy a fogadó alkalmazás hirtelen indíttatásból elhalálozik, mivel az üzeneteket az operációs rendszer felügyeli. Ha a programok magukhoz térnek, a kommunikáció úgy folyik tovább, mintha semmi sem történt volna, nem vész el információ. Az MSMQ képes tranzakciók kezelésére is, csakúgy, mint az SQL Server. Korábban az jelentett problémát, hogy az MSMQ és az SQL Server tranzakcióit nehezen lehetett összekötni, legfeljebb a Microsoft Distributed Transaction Coordinator segítségével lehetett ezt megtenni.
A Service Broker adatbázisszinten tárolja az üzeneteket, így azokat még a biztonsági mentések is tartalmazzák. A Service Brokeren keresztül minden SQL parancsból küldhetünk üzeneteket a külvilágnak, vagy akár saját magunknak, ha éppen arra van szükség. A DDL triggerek is kicserélhetőek DDL Event Notification-ökre, és így közvetlenül a Service Brokeren keresztül kommunikálhatnak. A Service Broker már nem használja a Distributed Transaction Coordinatort és nem is konkrétan MSMQ-ra épül, hanem ezek továbbfejlesztett koncepiójára.
[oldal:Összegzés]
A Microsoft új adatbázisszervere már béta állapotában is meggyőző, habár rengeteg funkció -- különösen a felhasználói felületen -- még nincs kifejlesztve, és emiatt gyakran csak SQL-ek segítségével tesztelhetőek le képességei. Az is előfordul, hogy egyes adatbázissal kapcsolatos feladatokat csak Whidbeyen keresztül lehet elérni, és Yukonból egyáltalán nem, mint például az adatbázis-diagram szerkesztő használatát.
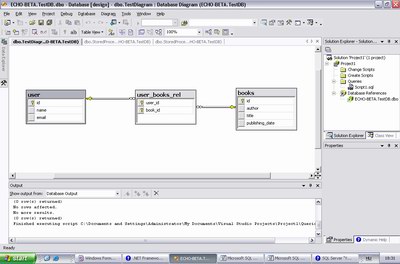
Diagramszerkesztő a Whidbeyben
A Yukon integrációs megoldásai igazi áttörést jelentenek a programozók számára, a legtöbb, korábban nagy nyűgöt okozó feladatot sokkal egyszerűbben, biztonságosabban lehet vele megvalósítani. Az adatbázis-adminisztrátorok is gond nélkül elérhetik megszokott eszközeiket, egyedüli nehézséget a rengeteg új képesség megismerése, és azok minél hatékonyabb kihasználása okozhat.
A .Net keretrendszer használatának lehetősége és a rendelkezésre álló szolgáltatások révén a Yukon képes lesz felvenni a versenyt a piac legjelentősebb adatbázisszoftvereivel, amiben szerepet játszik kedvező ár-érték aránya, és alacsony üzemeltetési költsége is.
A Yukon már a .Net keretrendszer még kiadatlan 1.2-es változatára épül. Ez a változat a Java 1.5-ös -- még szintén béta -- verziójú keretrendszer legfontosabb újdonságait is tartalmazza. A C#.Net és a Visual Basic.Net programozási nyelvek is továbbfejlődtek, hogy megkönnyítsék a fejlesztők munkáját; ebből is látható, hogy a Java és a .Net közötti verseny nem ér véget egyhamar, sem alkalmazások, sem adatbázisok fejlesztése terén.
Érdekes módon az IBM támogatni fogja új DB2 adatbázisszerverében, a Stingerben a .Net keretrendszer használatát. Ezáltal látható, hogy az IBM is komolyan veszi a Yukont, valamint a .Net keretrendszert, és megfelelő alternatívát kíván nyújtani a Windows platformot használó ügyfelei részére. Kérdéses még, hogy lesz-e lehetőség a nyílt forrású .Net keretrenszert fejlesztő project, a Mono adatbázisban történő felhasználására; ebben az esetben akár Linuxon is elérhető lenne a technológia.
A legfrissebb információk alapján a végleges termék megjelenésére még 2005 elejéig várni kell, de az SQL Server 2000-et használó vállalatoknak már ez idő alatt érdemes felkészülniük a mielőbbi átállásra, amihez minden szükséges dokumentum időben elérhető lesz. Addig is a jelenlegi rendszer, és a hozzá megjelent kiegészítő modulok -- mint például a közelmúltban kiadott Reporting Services -- biztosítják, hogy azok a szolgáltatások, amik az SQL Server 2000-ben is megvalósíthatóak, még a Yukon megjelenése előtt elérhetőek legyenek a felhasználók számára.