Nem meglepő, hogy hülyeséget mondhat a ChatGPT
Az elmúlt hónapokban elképesztően gyorsan felfutott ChatGPT jelentőségéről bőszen vitatkoznak a technológia kritikusai és elismerői. Három hazai szakértővel beszélgettünk arról, valóban mérnöki mérföldkőnek számít-e, amit az OpenAI fejlesztői letettek az asztalra, mik a felmerülő technikai problémák és kihívások a generatív nyelvi modellekkel megtámogatott szolgáltatások még szélesebb körű elterjedésében és képességeiben.
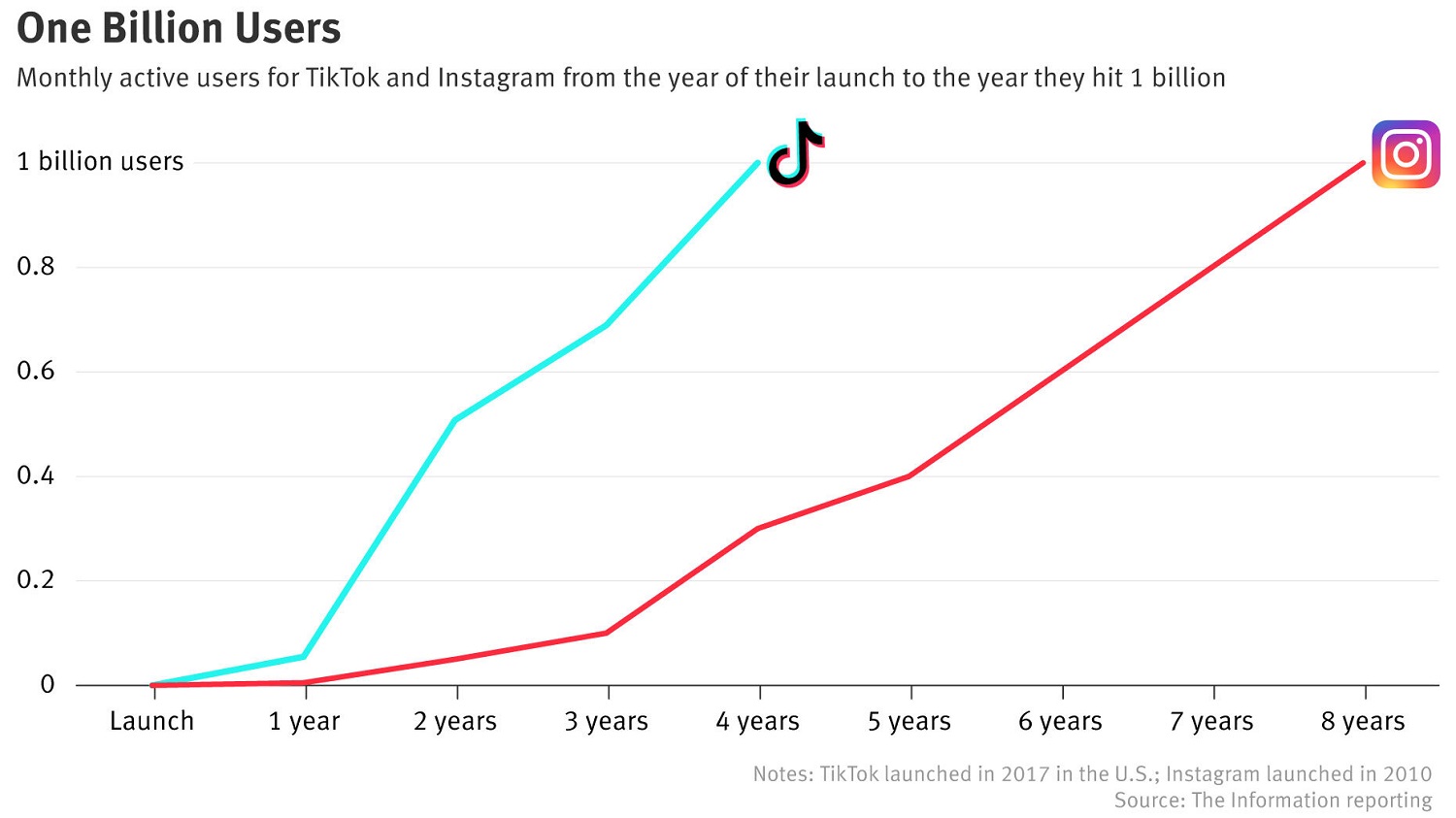
Február elsején jelent meg egy összehasonlítás a 100 millió fős felhasználói számot átlépő ChatGPT-vel kapcsolatban, miszerint a chatbot növekedési tempója az eddigi leggyorsabban felfutó fogyasztói alkalmazásokat is túlszárnyalta. A szélesebb közönség előtt tavaly decemberben megnyitott chatbot az első hónapban 57 millió havi aktív felhasználót szerzett magának, januárban pedig meghaladta a 100 milliós mérföldkövet a UBS befektetési bank kutatása szerint. Ezzel szemben a TikTok videóalkalmazásnak nagyjából kilenc hónapra volt szüksége, hogy ugyanekkora bázist építsen fel, míg az Instagramnak két és és fél év kellett a havi 100 millióhoz. A példák sora folytatódik a hat és fél év alatt ugyanekkora népszerűséget befutó Google Fordítóval.
Az AI ára Fizetnek a befektetők, fizetnek a felhasználók, és nagy árat fizet az IT munkaerőpiac is. Vékony jégen járunk. Itt a 85. kraftie adás.
Az elmúlt hetekben a technológiai szektor meghatározó alakjai is méltatták a GPT-modellre épített szolgáltatást, köztük John Carmack, aki szerint a generatív MI egy évtizeden belül képes lesz úgy gondolkodni, akár az emberek, 2030-ra pedig trillió dolláros iparággá növi ki magát, és a fejlődés következő lépcsőfokaként képes lesz végrehajtani azokat az összetett feladatokat, amikre egyelőre csak mi vagyunk képesek. A Google korábbi vezérigazgatója, Eric Schmidt azzal a merész összehasonlítással él, hogy a mesterséges intelligencia akkora hatással lehet a hadviselésre, mint az atomfegyverek. Az Amazon vezérigazgatója, Andy Jassy ugyanakkor úgy gondolja, hogy az MI legújabb generációja nem feltétlen nagy újdonság: a legtöbb nagy technikai vállalat már régóta dolgozik nagy generatív MI-modelleken, ahogy az e-kereskedelmi óriás is.
 Szabados Levente, a Neuron Solutions vezető tanácsadója, a Frankfurt School of Finance and Management docense nem pártolja a végletekben való gondolkodást, szerinte nem jó az a felfogás, hogy valamit vagy "hájpolunk és a dolog mindenre jó", vagy "baromság, és nem kell vele foglalkozni". Lehetséges, hogy valami valóban nagy áttörés, de ettől függetlenül nem biztos, hogy mindenre használható lesz. Ha pedig valami népszerű, nem jelenti azt, hogy hülyeség - se azt, hogy tökéletes.
Szabados Levente, a Neuron Solutions vezető tanácsadója, a Frankfurt School of Finance and Management docense nem pártolja a végletekben való gondolkodást, szerinte nem jó az a felfogás, hogy valamit vagy "hájpolunk és a dolog mindenre jó", vagy "baromság, és nem kell vele foglalkozni". Lehetséges, hogy valami valóban nagy áttörés, de ettől függetlenül nem biztos, hogy mindenre használható lesz. Ha pedig valami népszerű, nem jelenti azt, hogy hülyeség - se azt, hogy tökéletes.
A technológia világában minden fokozatosan épül fel: 2013 körül a statisztikai nyelvmodelleknél volt egy nagy váltás, aztán 2017-ban jött egy másik, tehát technikai értelemben sok mindent megalapoztak már. De amíg egy technológia nem jut el bizonyos szintre, addig üzleti szempontból nem vigasztaló, hogy "csak" egyre jobban működik. El kell jutni oda, hogy hasznossá váljon. Most sem az a fontos, hogy kialakult a hírverés és hirtelen berobbant a köztudatba, hanem hogy végre reálisan felvethetővé vált a valódi használat.
A szakember szerint a generatív nyelvi modelleket eddig nem mertük igazán használni, mert sok oldalról megtámasztást igényelt, hogy például létre lehessen hozni egy vállalati chatbotot, sok volt a félelem azzal kapcsolatban, hogy egy ilyen eszköz esetleg rosszat mond, nem jól fogalmaz, félreért valamit. A ChatGPT esetében nem arról volt szó, hogy jött egy előzmény nélküli radikális technológia, de érdemes lelkesedni, mert valamit tudunk végre használni.
Kovács Bálint, a Starschema data science szakértője szintén nagy jelentőségűnek tartja a ChatGPT által kínált tudást, szerinte most érnek be az ilyen fejlesztések egy elég hosszú kutatási folyamat eredményeként, a ChatGPT pedig mondhatni az új irány hírnöke.
"A cégen belül többen is vannak, akik kódoláshoz, vagy e-mailek előállításához használnak generatív eszközöket. Figyelni kell rá azonban, hogy az ember ne gondolkodás nélkül hagyatkozzon az eredményekre” - mondja, hangsúlyozva azt is, hogy nyelvi modellekről van szó, tehát nem feltétlenül igazak vagy helyesek az információk, amikkel dolgozik. Ezért egyelőre fontos, hogy a felhasználó mindig értelmezze és felülvizsgálja az eredményt. A generatív eszközök másik veszélye az lehet, hogy ha egy megoldás esetleg túl jól működik, akkor az ember ellustulhat, és nem fejleszti magát tovább, mert a gép „úgyis kódol helyette”.
A ChatGPT olyan, mintha az ember keze alá dolgozna egy komplett csapat, ez nagyon komoly eredmény. Vannak mérföldkövek, amiket nem tartok hype-nak, ezt sem. Már most előnyt lehet abból kovácsolni, hogy valaki használja a generatív eszközöket, valaki meg még nem. Oké, ott a TikTok: le tudja kötni az ember figyelmét, de annak munkában, vagy komolyabb területeken azért nincs olyan nagy haszna
– osztotta meg a HWSW-vel véleményét Takács Gábor, a Széchenyi Egyetem docense, a Cujo AI egykori chief data scientistje. Az adattudós szerint a generatív modellek azokon a területeken válthatnak ki sok feladatot a jövőben, ahol a gördülékeny fogalmazás a lényeg, nem maga az ötlet, például a marketingszöveg-írásban. A felhasználó kérhet a robottól tíz változatot, majd némi finomhangolás után a saját igényeinek megfelelően pontosíthatja az eredményt. Tehát ugyan bizonyos típusú munkákat el tud végezni egy eszköz, de fontos, hogy az ember el tudja magyarázni a chatbotnak, hogy mi nem tetszett neki az első változatban, mit szeretne, szükséges a tiszta fogalmazás.
Hasonló tapasztalatokról számolt be korábban egyébként Bereczki Nóra is, aki egy komplett mesekönyvet állított össze a ChatGPT és a Midjourney képgenerátor segítségével.

Takács meghatározó pontként említést tesz a Google-kutatók 2017-ben megjelent "Attention is all you need" című publikációjáról, ami hatalmas visszhangot kapott tudományos körökben. A keresőcég szakembereinek tanulmánya a gépi fordításról szól, ebben mutatták be a GPT nyelvi modell mozaiknevében T-betűt képviselő transzformer-architektúrát, lényegében ebből a neurálishálózat-architektúrából nőtt ki aztán a ChatGPT, ahogy sok más mai megoldás is.
Az OpenAI-nál egyszerűen rengeteg mérnöki munkát tettek bele ebbe az elképzelésbe: próbáltak minél nagyobb adathalmazon tanítani egy minél nagyobb transzformert. Meglepőnek tartom, hogy eddig a szintig jutottak. Az alapötlet valóban nem most született, de először sikerült úgy összerakni, hogy a nagy nyilvánosság elé lehessen tárni.
Már az elképzelhető mérnöki kihívások is sokszínűek lehettek a modell fejlesztése során: össze kellett gyűjteni a lehető legtöbb adatot, kvázi „kiolvastatni” az internetet, aminek során számolni kellett a jogi kérdésekkel is, mi használható fel és mi nem, az adatmennyiség kezelése pedig további informatikai probléma a tárolástól kezdve a modell kiképzéséig, felmerülhetett száz mérnök kérdés, ami a méretkezelésből fakadt.
Szabados a programozás példáján keresztül szemlélteti, hogy az eszköz valóban sok esetben segítheti a produktivitást, de a hozzáértés és a felügyelet továbbra is kulcsfontosságú marad. Ahogy mi is írtuk korábban: már futnak be az első fejlesztői tapasztalatok a GitHubba épített Copilot kódkiegészítővel kapcsolatban, a jelenlegi becslések szerint a senior fejlesztők kódjának körülbelül 40 százaléka akár automatán generálható is lehet, ami komoly érték. Ezek főleg azok a részek, amelyek sematikusak, és fejlesztői szempontból unalmasak, de muszáj megírni őket. Ám mint kiderült, pont a juniorok számára nem ajánlott, mivel őket megkísértheti a gondolat, hogy a létrehozott szép kód biztos jó.
Ha egy senior ránéz a kódra, kapásból tudja, hol hibás, vagy hol nyúlna bele, ezért pont ők lehetnek hatékonyabbak. A Copilot nem fogja elvenni a juniorok munkáját, inkább hatékonyabbá teszi azokét, akik már alapból tapasztaltabbak és tudják, hogyan integrálhatják a munkájukhoz az eszközt."
A sztohasztikus papagáj mindig hibázhat
Minden technikai újítás esetében számolni kell egy korai fázissal, amikor még finomhangolásra szorulnak az eszközök. A Microsoft is hangsúlyozza a Bing esetében, hogy még bétafázisnál tart a keresőbe épített chatrobot. A most zajló, széleskörű finomhangolás során a fejlesztők valójában a kereteket kereshetik, amiben a felhasználók segítenek nekik, ez azon is tükröződik, hogy a redmondiak elkezdték korlátozni, hogy egy munkamenet során hány kérdést lehet feltenni az eszköznek. A Google megközelítése különbözik: a nem túl fényes bemutatóban demózott Bardot egyelőre csak zárt körben, megbízható tesztelőkkel finomítják, és bár valóban vannak veszélyei a szélesebb elérhetőségnek, a több felhasználó több adatot tud generálni.
Ezzel párhuzamosan a hétköznapi felhasználók egyfajta kíváncsiságból tesztelik a technológia határait, és próbálnak olyan promptokat, kéréseket beadni a chatbotnak, ami arra veszi rá, hogy megkerülje a saját előírásait és belső szabályait.
Szerintem vágyálom, hogy egy ilyen rendszer tökéletesen működjön, hiszen mivel maga a tanítóadat már az internetről származik, szinte determinált, hogy az előállított szövegekben is előfordulhatnak hibák, vagy nem naprakész visszatérő adatok.
Ebből is következik az, hogy amennyiben a nyelvi modellnek nincs információja valamiről, akkor is próbál válaszolni, méghozzá elég terjedelmesen. Az eredmények minőségét adott témákhoz kapcsolódó, megbízható forrásból összeállított szakmai tudásbázisok felépítésével lehetne javítani, vagy akár egy felügyelőmodellt mellérakni, ami képes lenne meghatározni, mekkora a valószínűsége egy adott állítás igazságtartalmának. Tehát: hogy egy mindig csak igazat állító modell készüljön, nem hiszem, hogy megtörténhet” – véli a Starschema adattudósa.
Takács szerint is egy teljesen érthető helyzetről van szó, lévén a hallucinálás a generatív nyelvi modellek alapvető tulajdonsága, ami teljes mértékben nem kiküszöbölhető, legalábbis jelenlegi tudásunk szerint. Említi a kritikusok által használt „sztohasztikus papagáj” kifejezést azzal kapcsolatban, hogy a nyelvi modell valójában csak egymás mellé rakja a szavakat, amiket máshonnan tanult el. Ezen persze még lehet finomhangolni, de a felhasználóknak meg kell érteniük, mire való elsődlegesen az eszköz, és figyelembe venni, hogy ha a Google-ön, vagy az interneten keresünk, akkor is belebotlunk valótlan, vagy irreleváns információkba.
A robot lényegében Chuck Norrisként kiolvasta az internetet, és így böfög vissza mondatokat valamilyen formában, néha véletlenszerű, mi jön elő belőle. Erről is szól a jailbreaking nevű sport, azaz hogy sokan megpróbálják ilyen-olyan lekérdezésekkel előhozni a technológia rossz oldalát. Az embereket mindig az izgatja, milyen szélsőséges dolgokat lehet előhozni, de ilyen a természetünk.
Szabados optimista azzal kapcsolatban, hogy már hónapokon belül sikerül majd jobb eredményeket elérni, illetve bízik abban, hogy a technológia kapcsán megindulhat egy komolyabb diskurzus arról, mit is kezelünk tényként, és honnan szedjük az információkat, ezáltal elkezdünk reflektálni magunkra is.
Ha fogunk egy papagájt, aminek azt a hülyeséget tanítjuk, amit mi írtunk az internetre, akkor mit lepődünk meg, hogy visszamondja azokat? Mondogatják, hogy nem tényszerű a ChatGPT, de az internetre írt emberi szövegek mikor azok?
Az elkövetők részben magunk vagyunk. Igen, nem beszél tökéletesen, de még mi magunk sem: mindenféle homályos utalásokat teszünk, néha azt hisszük, hogy érthető a másik számára, amit mondunk, de közben meg nem" - fogalmazza meg a szakember a markáns véleményt.
Az eredmény magával hozza az optimalizálást
A gyorsan növekvő bázis magával hozta a saját felületen elérhető ChatGPT szervereinek leterheltségét is, az OpenAI számára pedig elkerülhetetlenné vált a chatprogram monetizációja és a fenntartási költségek egy részének fedezése, ami előfizetős szolgáltatás formájában valósul meg. Érdekes kérdés az is, hogy a későbbiekben merre indulhat el a szolgáltatás, és a nyelvi modell optimalizálása, fejlesztése, és miként oldják meg az óriáscégek a költséges üzemeltetés problémáját.
"A tudomány nem egy egyenletes úton halad, hanem időnként áttöréseket ér el. Most arra sikerült rájönni, hogy ha elég nagy modelleket csinálunk nagy adatokkal, akkor nagy eredményeket érünk el. De nem tudjuk, hogy ennek az eredménynek mennyire esszenciális része, hogy nagy volt a modell, vagy hogy nagy volt az adat, és hogy a végeredményhez mindkettő szükséges-e. Vagy hogy esetleg más tanítási módszerrel, de mondjuk tizedakkora, vagy feleakkora modellel is lehet-e hasonlót elérni.
Az őrült keresés most afelé indult el, hogy mi volt az áttörés lényeges eleme, amitől működni kezdett minden. Hogy ha ez kiderül, akkor derül ki az is, hogy mit csinálunk pazarló módon" - mondja Szabados.
A Starschema szakértője szerint a mérnökök a jövőben jobban ráfókuszálhatnak a nagy hálók méretének lecsökkentésére, ezt az irányt lehet látni például az autók önvezető szoftvereinek esetében is. Ha elkészül egy neurális háló, a fejlesztők megpróbálják egy nagyon hasonló eredményt produkáló kisebb hálóvá szervezni. A nagy nyelvi modellek területén is elképzelhető ezért, hogy megpróbálják minél kisebb számítási kapacitással működővé optimalizálni.
Takács úgy véli, az eredmények már magukban katalizálják az optimalizálási folyamatokat, személyes meglátása szerint a jövőben három irányban indulhatnak fejlesztések. Szóba jöhet a még több adattal való további tanítás, ami abból kifolyólag nem egyszerű, hogy még mélyebbre kell ásni az értelmes adathalmazokért, felkutatni, hogy egyáltalán milyen források léteznek még. A következő a modell méretének optimalizálása: minél nagyobb, annál használhatóbb, de ez kétélű fegyver, mivel bár pontosabbá válhat, de egyben drágábbá és a tanítása is lassabbá válik. Ezen felül szóba jöhet a modell egyszerűsítése, és abból kiindulva, hogy az alapot adó eredeti transzformer-architektúrán is többször módosítottak, a GPT újabb verzióban is szóba jöhet. A nagyobb modellhez több hardver kell, az egyszerűsítéshez pedig ötlet, amelyek mind-mind megoldandó mérnöki problémák.
Sokakat izgat az is, hogy a keresőpiacon milyen változások indulhatnak meg, de ez egy fokkal összetettebb kérdés. Aktuálissá az teszi a kérdéskört, hogy a Microsoft beépítette a ChatGPT alatt dolgozó megoldást a Bing keresőbe, de ehhez egyelőre csak a felhasználók szűk köre férhet hozzá. Az évek óta stagnáló kereső népszerűségét láthatóan megdobta a fejlesztés, a Bing átlépte a napi 100 millió aktív felhasználós mérföldkövet. A tesztelésben résztvevő felhasználók közel harmada mindennap használja a chatelési funkciót a lekérdezésekhez, munkamenetenként átlagosan három csevegést folytatnak vele. Erre azonban korlátot vezetett be a Microsoft, miután a netezők elkezdték feszegetni a határokat. Takács szerint is lehetnek költségmegfontolási szempontok amögött, hogy nem lehet lecserélni egyszerre az összes keresést.
A chatboton keresztüli keresés kezelésére szolgáló infrastruktúra kiépítése még folyamatban van, és ezzel kapcsolatban sok feladata lesz még a Microsoftnak és a Google-nek Bob O’Donnell, a Technalysis Research vezető elemzője szerint. És hozzá kell tenni, hogy a Microsoft Bing keresőpiaci részesedése továbbra is még csak meg sem közelíti a Google dominanciáját, ami a Statcounter friss adatai szerint jelenleg egész pontosan 93 százalék. Hogy a Google és a Microsoft felhasználók ezreihez tudja eljuttatni a technológiát, abban kulcsfontosságú szerepe lesz annak, hogyan fejlesztik a hardveres- és adatközponti infrastruktúrájukat. A SemiAnalysis alapítója, Dylan Patel egy hírlevélben elemzi, hogy a Google számára több milliárd dollárba kerülne, hogy nagy nyelvi modellt építsen a keresőbe, idő kell a költségcsökkentéshez, mire a méreteket és a modelleket a hardverhez optimalizálják.
Túl sok technikai részletet egyelőre egyik cég sem osztott meg. Dena Saunders, a Microsoft Bing termékvezetője annyit árult el, hogy világszerte erősítik adatközpontjaik felszereltségét, konfigurálják az elosztott erőforrásokat, új platformelemeket építettek a terhelés egyensúlyozására, a teljesítmény és a skálázás optimalizálására. Prabhakar Raghavan, a Google keresési üzletágért felelős alelnökének elmondása szerint az ő technológiájuk a GPT-nél sokkal kisebb modell, aminek lényegesen kevesebb számítási teljesítményre van szüksége, így több felhasználóra méretezhető. Patel szerint saját chipjei lévén a Google jelentős infrastrukturális előnyökkel rendelkezik az Nvidia-alapú HGX A100-at használó Microsofttal/OpenAI-jal szemben.
A Google Bardját TPU (Tensor Processing Unit) chipek hajtják a felhőszolgáltatásában, amit a cég terveit ismerő forrás is megerősített, a 2016-ban bemutatott TPU-k pedig kulcsfontosságú elemei a vállalat MI-stratégiájának, többek közt ezek segítségével dolgozott az AlphaGo rendszer, ami 2016-ban legyőzte a Go-bajnok Li Szedolt. A vállalat saját nagy nyelvi modelljét szintén TPU-kon való futtatásra fejlesztették ki, emellett a Google testvérszervezete, a DeepMind szintén TPU chipeket használ a kutatásaihoz.
A cégek rendkívül eltérő mesterségesintelligencia-infrastruktúrával rendelkeznek, és a válaszok sebessége és az eredmények pontossága egyben az újgenerációs keresőmotorok életképességének próbája is lesz. Összességben elmondható, hogy bár nem egy előzmények nélküli technológiát látunk kibontakozni a szemünk előtt, valóban nagy áttörésnek tekinthető, hogy már a széles közönség előtt használható megoldást lehetett bevezetni, a versenyfutás pedig csak most kezdődik igazán.