Konténerek a felhőben – tippek Dev-től Productionig
Manapság a konténerek, illetve konténerizáció a többségnek ismerősen csenghet az IT szakmában. Bár a technológia régen lehetővé teszi a konténerizációt – már a 2000-es években is léteztek, valamint máig léteznek megoldások (pl. OpenVZ, LXC, LXD) – , de igazán széles körben 2013-ban, a Docker megjelenésével vált elterjedté.
A Docker béta verziója egyből a fejlesztők kezében landolt, mivel egyszerű módon biztosította a Linux alapú fejlesztői környezetek hordozhatóságát, reprodukálhatóságát, így az alkalmazások egyszerű hosztolását is. Akkoriban a gyorsan növekvő user groupok mellett sokan voltak a szkeptikusok is, akik biztonsági szempontból kritizálták, és csak egy új, gyorsan lecsengő hype-nak hitték a konténerizációt. Mostanra, a Docker első stabil verziója óta 4 év eltelt, kinőtte gyermekbetegségeit, és az is megdőlt, hogy ez csak egy felkapott hype lenne. A konténerizáció tehát itt van, mára a startupok mellett sok enterprise IT stratégiának is része lett, és egyre több éles rendszer fut konténereken.
Miért jó alkalmazásokat konténerizálni?
Vegyük a klasszikus példát! A feladat több alkalmazás hosztolása on-premise vagy felhős infrastruktúrán. Mára a virtuális gépek (VM) használata rutinnak számít ilyen feladatokra, tehát viszonylag egyszerűen indíthatunk akár 3-4 virtuális gépet az alkalmazásainknak. Ez esetben minden virtuális gép saját operációs rendszert (OS) futtat, jelentős erőforrásokat lekötve, és éppen a VM-en futó operációs rendszer nehézkessége miatt az elindulás minimum pár percet igénybe vesz. A virtuális gépek kapacitásának becslése sem egyszerű a megfelelő CPU, RAM méretezésre nézve, ha átlagos 50%-os kihasználtságot elérünk, már elégedettek lehetünk, nem beszélve a VM I/O overhead-ről, amely ugyancsak fontos paraméter és számolnunk illik vele.
Ezzel szemben nézzük meg a konténerek erőforrás igényeit: egy közös OS kernelen futnak (ez lehet egy VM operációs rendszere is), és a Docker engine ez alatt futtatja a konténereket, amik adott esetben meg tudják osztani a library-ket egymással, azonban a processzek, memória területek teljesen szeparáltak egymástól. Ez a gyakorlatban azt jelenti, hogy egy üres konténer jellemzően 1 másodperc alatt elindul, szemben egy üres operációs rendszer 2-5 percével. A szerveren belül az erőforrásokat is hatékonyabban lehet kihasználni, hiszen könnyen lehet, hogy egy erőforrás igényesebb "App A" mellé egy kis igényű "App B" instancia is megférne, amíg a kapacitás rendelkezésre áll, majd mozgathatóak tovább más felhasználatlan szerver kapacitásokhoz.
Itt érdemes megjegyezni, hogy a fenti megállapítások, értékek jellemzően Linux-on futó konténerekre vonatkoznak, mivel a Windows-on a Docker a Hyper-V virtualizációs réteget használja - szemben a Linux cgroups és namespace kernel szintű megvalósításával.
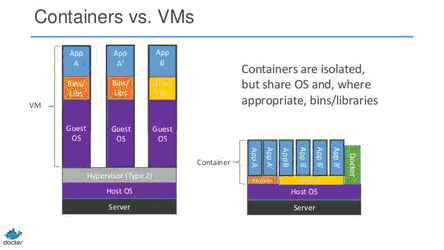
(forrás: https://www.sdxcentral.com/cloud/containers/definitions/containers-vs-vms/)
Egy másik nyomós érv a konténerek mellett a hordozhatóság. Számtalan olyan hibát látni hagyományos környezetekben, amikor egy új production release előállítása nem sikerül a futtató környezetek különbözősége miatt. Más lesz az operációs rendszer verzió, más library-k, engedélyezett dependency-k, stb. az éles rendszerben, mint teszten, és rendszerint mindig más, mint a fejlesztői rendszereken. Ezt a problémát a konténerek nagyon egyszerű módon orvosolják: mivel a konténerek teljesen izoláltan futnak az OS-től, előre definiált, hogy milyen lib-ek, dependency-ket használjon a konténer futtató környezet, magyarul minden olyasmit, ami az alkalmazásunk futtatásához szükséges. Ezek a definíciók szkriptekként vagy leíró fájlokban vannak meghatározva, tehát verziózhatók és automatikusan telepítenek minden szükséges komponenst. Ezzel a megoldással a környezetek különbözőségének ki is húzták a méregfogát, a konténer képet (Image) egyszer kell összeállítani (Build), majd a fejlesztők, a tesztelők és az éles rendszer is ugyanazt a környezetet használhatja.
További adalék a verziózáshoz, hogy nem csupán a konténerek készítéséhez szükséges leíró file-ok, de maguk a konténerek image-k is verziózottak. Minden változtatás nyilvántartott és visszavonható, ha szükséges.
(forrás: http://blog.daocloud.io/build-dockerfile-campaign/)
Hogyan kezdjünk kialakítani a saját konténer "stratégiánkat": milyen technológiákat érdemes választani?
A konténereket támogató eszközök azonnal elterjedtek a népszerűség megugrásával. Mára még mindig sok opció közül választhatunk, viszont jóval letisztultabb a kép, ha megnézzük melyik támogató technológia, milyen területet fed le.
Találkozzunk, idén is lesz SYSADMINDAY! Július 17-én lesz a hazai Sysadminday! Standup, üzemeltetői meetup, kvízek, szakmázás, barátok, még több sörcsap.
Ma, és vélhetőleg a későbbiekben is a legnépszerűbb technológia a Docker lesz, hiszen a neve sokak számára egybeforrt a konténerizációval a töretlen népszerűség révén. Napjainkban 10 konténeres projektből 9 Docker technológiával indul. A széles felhasználói tábor csak tovább erősíti ezt a trendet, hiszen a Docker-rel, és azzal kapcsolatos technológiákkal van kitömve az összes fórum, youtube videó és más internetes technikai portál, így nagyon könnyű fejlesztési és üzemeltetési tippeket kapni. A Docker, mint brand további eszközöket, framework-öket adott ki, amik már fizetős formában nyújtanak segítséget production workload-ok futtatásához (például Docker Datacenter), hasonlóan a felhő szolgáltatók konténeres menedzselt szolgáltatásaihoz.A Docker legkomolyabb kihívója a CoreOS által indított Rkt projekt (ejtsd: rock-it). A Rkt egy évvel a Docker után indult, mivel kifogásolták a Docker üzlet-orientált termékfejlesztését - ezzel szemben a Rkt a konténeres technológia minél inkább sztenderdizált, átlátható és bővíthető fejlesztését célozza meg. Ennek megfelelően a Rkt is open source (a Docker kód is open source: https://github.com/docker ), de egy biztonságosabb konténer futtatást igyekszik biztosítani a Docker-hez képest. Például, a Rkt-ben nincs konténereket futtató daemon, hanem azok közvetlenül indulnak a host gépen, míg a Docker konténereket futtató dameon a host gépen mindig root user-ként kell, hogy fusson (vagy azonos jogosultságokkal ellátva), ez a Docker esetén az IT biztonsági részlegen gyakran kiveri a biztosítékot. Az Rkt az átláthatóság jegyében nyílt konténer image és runtime specifikációkkal rendelkezik (szemben a Docker nem publikus image specifikációjával). Szerencsénkre léteznek szabvány formátumok a konténerek számára, például az Open Container Initiative (OCI), amit egységesen a Docker és a Rkt is követ. Ez a gyakorlatban azt jelenti, hogy a Rkt tud Docker image-eket futtatni, ami a felhasználhatóságát rendkívüli módon kiterjeszti. Ugyan a Rkt a Docker-hez képest egy még kevésbé kiforrott technológia, de valós alternatívát kínál.
A további konténeres technológiák egy része a Docker és Rkt elődei, mások (pl. LXD) inkább könnyű Linux virtuális gépként, mint alkalmazás konténerként funkcionálnak, így inkább kiegészítik, mint versenytársai a Docker-t és Rkt-t. Cikkünkben ezekre a technológiákra nem térünk ki részletesen.
Orchestration engine
Az orchestration-ről eddig nem sok szót ejtettünk, pedig azonnal adja magát a probléma, amint háromnál több microservice-t próbálunk futtatni egy container clusterben. Egy microservice hány konténerben fusson, meddig skálázódhat fel és hogyan tud kommunikálni a többi microservice-szel? Ilyen jellegű - clusteren belüli - konténer műveletekkel, belső network routing-gal, erőforrás menedzsmenttel (pl. publikus felhőben automatikus cluster bővítés) foglalkoznak az orchestration eszközök. Kezdetben ez egy sűrű, és szoros verseny volt, mára azonban a népszerűség eldöntötte, melyek a legjobb framework-ök és letisztult a kép.
A Docker Swarm a Docker Compose-zal kiegészülve a Docker saját fejlesztésű orchestration tool-ja, ami az 1.12-es verziótól már beépítve része a Docker engine-nek. Ennek megfelelően elég népszerű, mivel natívan integrált a Docker-es funkciókkal, futtató parancsokkal.
Annak ellenére, hogy van saját beépített eszköze a Docker-nek a skálázódásra, a Kubernetes(K8s) látszik az orchestration verseny befutójának. A Kubernetes projekt alapjait a Google kezdte - a Google szervezeten belüli több, mint egy évtizedes konténer menedzsment tapasztalat felbecsülhetetlen előnyt jelentett ennek a projektnek - majd open source-ként a Cloud Native Computing Foundation (CNCF) részeként került további fejlesztésekre (hasonlóan a Rkt-hez). Mára a verseny végét is látni lehet a konténer orchestration eszközök futamában - a Kubernetes lett a legnépszerűbb eszköz, amit mi sem mutat jobban, mint hogy maga a Docker is integrálódott a Kubernetes-szel a konténerek futtatásához. Emellett számos más termék, ami részben vagy teljesen a Kubernetes versenytársa volt az elmúlt években, mára a Kubernetes-en fut, ahhoz ad menedzselt szolgáltatásokat, kiegészítve azt a korábban fejlesztett saját szoftver funkcióival, például Rancher, Openshift, Pivotal Kubernetes Service. A mai publikus felhő szolgáltatók "nagyjai" (AWS, MS Azure és Google) is rendelkeznek, vagy a közeljövőben fognak kiadni Kubernetes as a Service szolgáltatást, annak ellenére, hogy néhányan már rendelkeztek saját konténer orchestration szolgáltatással is.
Más termékek, például a Hashicorp Nomad vagy az Apache Mesos ugyan tudnak konténereket is skálázni és kezelni, azonban felhasználhatóságuk nincs erre a területre korlátozva, az jóval tágabb. Ezeket az eszközöket "Scheduler" vagy "Resource manager"-nek hívják, és például egész adatközpont és felhő account-okat tudnak egybefogva kezelni, ezen belül virtuális gépeket, alkalmazásokat és konténereket nyilvántartani, menedzselni. Értelemszerűen a konténer specifikus funkcióik is magasabb szintűek, emiatt részben korlátozottabbak lehetnek.
Tippek és alap követelmények a konténerek sikeres használatához
Sok helyen tapasztalom, rengeteg csapat dolgozik konténerekkel - sokan egyelőre csak fejlesztői környezetben. Azonban mekkora technikai ugrást jelent - biztonságosan - éles konténerizált rendszereket üzemeltetni a fejlesztési fázishoz képest? Az alábbiak a véleményem szerint legfontosabb általános szabályokat és konténeres filozófiát foglalják össze. Ez a gyűjtemény részben a 12 factor app ajánlásokból származik, egy rendkívül hasznos anyag felhős és konténeres éles rendszerek építéséhez.
"Cattle vs. pets"
Kezdjük a legfurábbnak tűnő analógiával! Ezt még a 2010-es évek elején alkották és kapták fel jó párszor azóta, ha felhős vagy konténeres skálázódást és operations-t kellett elmagyarázni. Tehát miről is szól? A régi szemléletű rendszerek futtatása, ahol tipikusan 1-1 node, vagy node pár (fizikai szerver vagy virtuális gép) egy speciális funkciót lát el, aminek mindig futni kell. Számtalan helyen láttam, hogy az egyszerűsítés kedvéért neveket adtak ezeknek a szervereknek, például kereszt, állat vagy étel neveket. "Cirmi, az email szerver" leállt, és minden email alapú kommunikáció állni fog a cégnél, amíg azt az egy szervert vissza nem "gyógyították" működőképesre. Az email szerver konfigurációja ebben az esetben egyedi, a tartalmak nem, vagy csak nehezen állíthatók vissza másik hardware-en, így minden erőfeszítés a nem funkcionáló szerver megjavítására összpontosul. Innen az analógia Pets része, a szervereket mint szeretett háziállatokat elnevezzük, ha lebetegednek, azonnal orvosoljuk őket.
Ezzel szembe állítja a példa az újfajta operations management módot, a "Cattle" azaz "csorda" szemléletet. A csordát egy egységként kezeli, az állatok száma nőhet és csökkenhet, számszerűen vannak nyilvántartva, azonban az egyes állatokat nem különböztetjük meg, azok számunkra egyformák. Ha az email küldés példájánál maradunk, a csorda esetén gondoljunk az email küldésre ezúttal mint szolgáltatásra, és nem mint kiszolgáló szerver(ek)en futó alkalmazásra. Hiszen egy szolgáltatásnál a mérőfaktor az üzemképesség, gyorsaság és megbízhatóság, az, hogy milyen szervereken fut, irreleváns a végfelhasználó számára.

A szolgáltatás tipikusan a cattle modellben elosztottan, több node-on fut párhuzamosan (VM-en vagy konténeren), a node-ok pedig kiesés esetén automatikusan pótlódnak, újak állnak be a forgalom kiszolgálásához, a szolgáltatásban való bármiféle leállás nélkül. Ez a fajta automatikus "öngyógyulása" egy szolgáltatásnak természetesen egy magasabb szintű automatizáltságot feltételez a futtató platformról (rendszerint virtualizált vagy konténerizált környezetet), ami nem lehetséges a tradicionális IT környezetekben, ahol előre fixált, statikus erőforrásokkal számolhatunk. A Cattle vs. Pets példán keresztül látható, hogy az új technológiai platformokra helyezett alkalmazások menedzseléséhez új operating model-re van szükség, hogy a konténerek (vagy felhő) adta előnyöket maximálisan kihasználhassuk.
Stateless vs. stateful
Általában ez a legsarkalatosabb pont egy alkalmazás vizsgálatánál, hogy képes-e optimálisan konténerizált környezetben futni. A kérdés az, hogy a "statefullness", azaz állapotok kezelése az egy node-on futó alkalmazásnak hogyan oldaható meg? Tipikusan az állapot alatt user session-t, lokálisan tárolt média fájlokat vagy dokumentumokat, logokat értünk.
Mi is a probléma a lokálisan tárolt adatokkal? Ebben az esetben az elosztott működés, tehát a forgalom kiszolgálása több node egyidejű működésével (párhuzamosítással - load balancing), sokkal bonyolultabbá válik, hiszen minden node-unk egyedi állapotot tárol. Amennyiben nagyobb erőforrásra van szükség, ez a fajta hosting model a vertikális skálázódás felé mutat, azaz több CPU-val és memóriával ellátni a kiszolgáló node-jainkat, például konténereket. Amennyiben így skálázódunk, értelemszerűen a konténerek egy idő után "kinövik" a kiszolgáló fizikai szervert, így egyre drágább és nagyobb (enterprise) hardware-be szükséges beruházni.
Amennyiben az állapotokat külső tárolókra mozgatjuk, (session-t cache tárolóra, média fájlokat object storage-ba, a logokat pedig log menedzserbe), az alkalmazásunk skálázhatósága optimálissá válhat. Képzeljük el, amennyiben növelni kell az alkalmazásunk részére a kiszolgáló kapacitást, egyszerűen csak több node-ot állítunk be a forgalom kiszolgálására (horizontális skálázódás), hiszen minden node külső tárolóból olvas és ment adatokat, tulajdonképpen mindegyik egyforma (cattle), így az is mindegy melyik node szolgál ki egy kérést. Ennek eredményeképpen konténer cluster-ek építhetők, ami több, általános (commodity) hardware-en futva tud párhuzamosan kiszolgálni egyre nagyobb forgalmat.
Graceful shutdown
Egy újabb különbség a konténerek elvárt életciklusa, a hagyományos szervereken hosztolt alkalmazásokhoz viszonyítva. Hiszen amíg egy hagyományos alkalmazást futtató szerver minimum hónapokra, de inkább évekre tervezett futásidővel rendelkezik, addig a konténerek, a horizontális skálázódás miatt várhatóan jóval kevesebb ideig futnak. A gyors elindulásnak (~másodpercek) és így fel és le skálázódásnak köszönhetően a konténerek jönnek-mennek, sokszor egy percig sem futnak, kiszolgálnak kéréseket majd terminálódnak. Ebben az esetben az alkalmazásunktól alapvető elvárás kell hogy legyen, hogy tervezett, vagy váratlan konténer leállás esetén minden állapotot konzisztensen hagyva terminálódjon, amit egy következő kiszolgáló konténer gond nélkül tud folytatni.
Kód vezérelt processzek, konfigurálhatóság
A fenti pontok után talán magától értetődő, hogy a konténerizált alkalmazásaink teljesen automatikusan, emberi közbeavatkozás nélkül tudnak elindulni, és a megfelelő node csoportba "beállni", forgalmat kiszolgálni. Ez sokszor más szolgáltatások felismerését és használatát (discovery) is magába foglalja. Egy másik fontos szempont a konfiguráció kiemelése a szoftver kódból, azaz például az adatbázis hosztnév változása esetén ne kelljen szoftver kódot változtatni, hanem azt környezeti változókkal tudjuk definiálni és változtatni.
Microservices vs. monolithic
Ezen a ponton talán egyértelmű, mi a probléma a monolitikus alkalmazásokkal. Ezek az alkalmazások nehézkes, egy egységként futtatható (ezért monolitikus), rendszerint stateful és vertikálisan skálázható rendszerek. Egy ilyen alkalmazás végül is futtatható konténerben, azonban annak előnyeit nem tudja kihasználni: a gyors konténer indulás lassú alkalmazás indítással párosul, egy futó konténerrel lehet csak operálni, mivel rendszerint nem párhuzamosítható az alkalmazás futtatása, és egyre nagyobb erőforrású konténereket és hardvert igényel a skálázódása során.
Ezzel szemben a microservices architektúra pontosan a fent felsorolt konténerizált rendszerek előnyeit erősíti. Ebben az esetben az alkalmazást alkotó service-ek külön futtathatók konténer csoportok együtteseiként, ami sokkal hatékonyabb (horizontális) skálázódást tesz lehetővé. Gondoljuk csak el, ha van egy konténerizált webshopunk, aminek például a termékeket megjelenítő része egy microservice, a fizetési modul pedig egy másik. Amennyiben több ezren nézik a termékeinket egyszerre, azonban egy termék megvásárlásáig csak sokkal kevesebben jutnak el, értelemszerűen csak a termékek megjelenítésére kell nagy kapacitásokat fordítani.

Konténerek és a publikus felhő
A konténerek nagyban segítik a skálázhatóságát és az erőforrás kihasználtságot optimalizálni, azonban ha saját szervereken, esetleg privát felhőben futtatjuk a rendszereinket, az még konténerek használatával is egy fix hardveres kapacitást jelent - nagyobb forgalmú, szezonális időszakban (pl. Black Friday, karácsonyi akciók) kifuthatunk az erőforrásokból. Többek között ezért tartják a publikus felhőt és a konténereket ideális párosításnak, hiszen még egy nagyvállalat számára is korlátlan számítási kapacitás érhető el percek alatt a publikus felhőben, szemben a hónapokig tartó hardware beszerzéssel, üzemeltetéssel egy privát felhőben.
Természetesen a startup-ok körében is népszerű a konténerizált, microservices alapú alkalmazás fejlesztés a felhőben. Ez egyrészt praktikus az extrém skálázhatóság biztosítására (ami minden startup álma, hogy exponenciálisan nő a forgalmuk), másrészt a konténerek portabilitása lehetőséget ad akár publikus felhő szolgáltatók közötti egyszerű költözésre is. Találkoztam már nem egy olyan csapattal, akik a szolgáltatók egy éves vagy pár száz dolláros free trial-re vagy tier-re alapozták az infrastruktúrájuk (ingyenes) futtatását az első pár évben - amint kifogytak a kreditekből, költöztek át más szolgáltatóhoz.
A nagyvállalatoknál is van relevanciája a publikus felhő és konténer párosításnak, de ott inkább a hibrid vonal jellemzőbb - a már létező saját infrastruktúra kiegészítéseként publikus felhőt használni, amit lassan (a saját hardware-ek csereidejével) a publikus felhő irányába súlyoznak. Fontos szempont lehet még a Vendor lock-in elkerülése és hogy legyen valóságos exit plan, azaz a felhő szolgáltatótól való leköltözés megvalósítható, és lehetőleg egyszerű, olcsó legyen. Ezeket a szempontokat a konténerek könnyű, egyszerű mozgathatósága szintén nagyban segíti.
Összegezve tehát: Akinek ma konténerizációs tervei vannak, valószínűleg a Docker és Kubernetes technológia párost találja a legoptimálisabb, hosszú távon továbbfejleszthető és fenntartható alternatívának, amit további termékek vagy felhő szolgáltatások hozzáadásával tehet még hatékonyabbá, automatizáltabbá. Fontos azonban az alkalmazás architektúráját és működését konténeres környezetben kipróbálni, validálni, mivel ez alapvetően befolyásolhatja a hatékonyságot, ezért ez mindig a tervezés korai szakaszában javasolt.
A cikk szerzője Sepsy Károly, a TC2 Lead Cloud Architectje.