Látványos gyorsulást hozhat az optimalizált memóriaelérés
Új alapkutatás segítheti a masszív adathalmazokon dolgozó szoftverek teljesítményét. Az adatok okos bekészítésével a rendszermemória késleltetése hatékonyan elrejthető, sokszorosára növelve a teljesítményt.
Új előtöltő algoritmussal több, mint négyszeresére gyorsítható a feldolgozás sebessége - találták az MIT kutatói. A kísérleti algoritmus egy új logikával dolgozik, ami a korábbi, közelségen alapuló előtöltéshez képest jelentős gyorsulást tud hozni az adatbázisok és a nagy adatmennyiségek feldolgozásában. A gyorsulás látványos lehet, alkalmazástól függően 50-300 százalékos teljesítménynövekedés is elérhető - találták az MIT CSAIL kutatói, Vladimir Kiriansky, Yunming Zhang és Saman Amarasinghe .
Késleltetés a CPU halála
A modern számítógépes architektúrák legnagyobb kihívása mára a feldolgozó egységek folyamatos etetése adatokkal. Az operatív tár sávszélessége ugyan elegendő lehet ehhez, a késleltetés azonban komoly korlátja a teljesítménynek - a processzor rengeteget áll arra várva, hogy a DRAM-ból bekért adat végre megérkezzen. A probléma különösen az in-memory adatbázisok, gráfelemzés és gépi tanulás alatt jelentős - az ilyen szoftverek memóriaelérési mintázatát ugyanis a jelenleg elérhető optimalizációk képtelenek hatékonyan előre jelezni, így az előtöltés sem segít.
Találkozzunk, idén is lesz SYSADMINDAY! Július 17-én lesz a hazai Sysadminday! Standup, üzemeltetői meetup, kvízek, szakmázás, barátok, még több sörcsap.
A modern fordítók ugyanis rendelkeznek beépített memóriakezelővel, amely igyekszik az elérés mintázata alapján előrejelezni, hogy melyik adatszeletre lesz szüksége a processzornak a közeljövőben és elindítja annak betöltését a gyorsítótárba - jóval azelőtt, hogy ezt a CPU megtenné. Az alkalmazás által használt adatmennyiség növekedésével azonban ezek az eljárások sokat veszítenek a hatékonyságukból - itt az ideje egy új megközelítésnek, találták az MIT kutatói.
Oszd meg és uralkodj!
Az új megközelítés referenciaimplementációja a Milk, egy C/C++ nyelvi kiterjesztés és fordító kombinációja, lényege pedig, hogy az eléréseket és a memóriakezelést is igyekszik strukturálni, előrejelezhetőbbé tenni és párhuzamosítani. A Milk abban különleges, hogy a hardver és az adattömeg tulajdonságait is maximálisan igyekszik szem előtt tartani. Az alapgondolat: a memóriát olyan partíciókra osztani, amelyek beleférnek a processzoron található gyorsítótárba, és olyan programszálakat létrehozni, amelyek egyszerre csak egy partíción dolgoznak. Emiatt a Milk ott képes maximális hatékonyságot elérni, ahol a feldolgozás ilyen független szálakra bontható - a fent említett területek (in-memory adatbázis, gráfelemzés) azonban pont ilyennek számítanak.
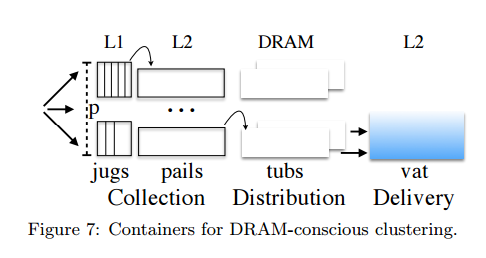
A Milk-féle "DRAM-conscious Clustering" eljárás a szoftverben található hurkokat (loop) három logikai fázisra osztja: adatgyűjtés, kiosztás, átadás (collection, distribution, delivery). Ebben az algoritmus előbb összegyűjti az együvé tartozó adatokat, és ezeket hatékony szekvenciális írással kiírja a memória egy logikai partíciójába, végül az utolsó fázisban a partícióhoz tartozó összes adatát egyszerre, a feldolgozásra váró parancsokkal együtt beolvassa és átadja a CPU-nak. A csavar a dologban, hogy a Milk (a szálak függetlenségére vonatkozó alapállásból kiindulva) nem szinkronizál adatokat a threadek között, így nagyon hatékonyan tudja megvalósítani a fenti folyamatot.
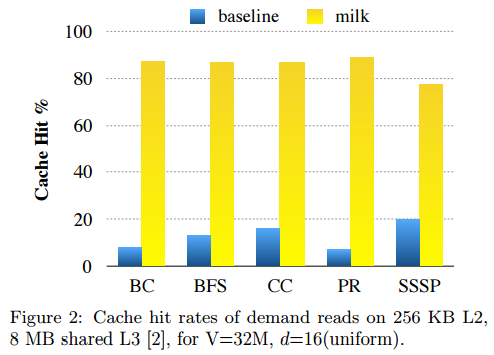
A megközelítés előnye nagyon látványos, a kutatók adatai szerint a cache hit rate (vagyis annak az aránya, hogy a CPU által bekért adat már a gyorsítótárban hever) 8-20 százalékról 75-90 százalék környékére emelhető. Mindez annak fényében különösen nagy szó, hogy a Milk használatához nem kell teljesen átdolgozni a programozási modelleket, sem a szintaxis, sem a szemantika nem változik a szokásos C/C++ illetve OpenMP kódhoz képest - a fenti megoldást a fordító (többé-kevésbé) saját hatáskörben implementálja, így a programozónak nem kell ahhoz alkalmazkodnia.
A Milk részletes leírása és a kutatás egyéb adatai a publikált beszámolóban olvashatóak - érdemes fellapozni. A kutatók munkája természetesen csak az alapokat teszi le, de a hasonló megközelítések várhatóan hamarosan beépülnek a nagy adathalmazzal dolgozó szoftverekbe, az elérhető gyorsulás ugyanis túl látványos ahhoz, hogy a fejlesztők teljesen figyelmen kívül hagyják azt.