Új magokkal és 16 GB memóriával jön a Knights Landing
A lipcsei International Supercomputing Conference-en nem csak a frissített Top500 lista mutatkozott be, ezt az eseményt használta fel az Intel arra, hogy a következő generációs gyorsítóchipjéről beszéljen.
A Xeon Phi következő generációja, a 14 nanométeres eljárással készített Knights Landing a jelenlegi tervek szerint 2015-ben már szuperszámítógépekben működik. A lapka vadonatúj magokat, hatalmas kapacitású integrált memóriát és egy teljesen új hálózati interfészt vonultat fel a legnagyobb teljesítmény elérése érdekében, jelentette be az Intel tegnap.
Nagy piac lesz
Az Intel már évek óta dolgozik x86-alapú mérnöki-tudományos gyorsítóin, amelyek az eredetileg GPU-ként indult Larrabee projektből táplálkoznak. A Many Integrated Core (MIC) projekt nemrégiben kereskedelmi termékig is eljutott, így született a Xeon Phi gyorsítókártyák sorozata, rajtuk pofonegyszerű x86 magokat integráló Knigths Corner kódnevű lapkákkal. A vállalat már a következő generáció érkezését készíti elő, amellyel a célja ütős alternatívát nyújtatni a GPGPU-k ellen a mérnöki-tudományos számítástechnika világában.
A vállalat előrejelzése szerint a mérnöki-tudományos feladatokra használt rendszerek számítanak az egyik legnagyobb növekedéssel kecsegtető szegmensnek a szerverpiacon belül - a következő négy évben évi átlagban 20 százalékos bővülés várható itt, az IDC szerint a HPC szerverek forgalma 2016-ra évi 15 milliárd dollár körül alakul. Ennek legfőbb mozgatórugója a HPC "demokratizálódása", amit eddig a GPGPU-k vezettek, az NVIDIA (és az ATI) korán felismerte, hogy a grafikus chipeket jól lehet alkalmazni tudományos számítások gyorsítására is, egy GPU beépítésével egy a számítási teljesítmény sokszorosára növelhető, amely a felhasználó "termelékenységét" is megdobja.
Az Intel sem vonja kétségbe persze a GPGPU jelentőségét vagy hasznosságát, ám a vállalat érvelése szerint az ilyen "hibrid" (x86+GPGPU) rendszerek hatékony programozásához új módszereket, új nyelveket és új fejlesztői eszközöket kell megismerni, ezzel szemben az x86-alapú "Knights" kártyákra a már évek óta jól bevált Intel fejlesztői eszközökkel (fordítókkal, debuggerekkel) lehet dolgozni, ami olcsóbbá teszi a folyamatot és egyszerűbbé a meglevő kódok adaptálását. Lényegében elég a kódban néhány extra sort elhelyezni ahhoz, hogy az általános célú x86 processzorokon futtatott feladatok a Knights chipeken fussanak, jóval nagyobb sebességgel, állítja a cég.

Silvermont magok
Korábban már írtunk róla, nem hivatalos források alapján, hogy a Knights Landingben lecseréli a processzormagokat az Intel, a korábbi P54C-leszármazott (eredeti, MMX nélküli Pentium) x64 magokat Silvermont-generációs CPU-magok váltják. Ezt az információt a tegnapi bejelentésében az Intel megerősítette, illetve azt is közölte, a lapkán több mint 60 ilyen mag kap helyet - úgy tudjuk, összesen 72 darab Silvermont kerül a Knights Landingre, out of order lebegőpontos egységgel és 512 bites AVX kiterjesztéssel. A vállalat által nyilvánosságra hozott dia alapján a Knights Landing teljesítménye DP (dupla pontosságú) lebegőpontos műveletek alatt 3 teraflops feletti - összehasonlításképp a Knights Corner 1,2 teraflopsra képes, egy NVIDIA Tesla K20X sebessége pedig 1,31 teraflops.
A Knights Landingről már a tavaly őszi denveri Supercomputing konferencián is árult el részleteket az Intel. Akkor azt az információt osztotta meg a világgal a chipgyártó, hogy a chip az eddig elterjedt bővítőkártyák mellett közvetlenül a processzorfoglalatba építhető tokozásban is elérhető lesz. Így nem lesz szükség külön általános célú processzorokra és gyorsítókra, egyszerűbb lehet a rendszerarchitektúra - mivel a Knights Landing x86 magokat használ, maga képes futtatni a legtöbb operációs rendszert, amelyet a mérnöki-tudományos számítástechnika világában egyébként is alkalmaznak.
Revolutionary Advancements in Memory Performance
Még több videó16 gigabájt memória a tokban
A processzorfoglalatba illeszkedő lapkának közvetlen hozzáférése lesz a rendszermemóriához, így elvileg tovább nőhet a teljesítménye, nem lesz szükség az adatok másolgatására a kártya és a rendszermemória között, amivel kikerül a képletből a memória, a PCI Express és a hálózat késleltetése is. Ezzel a megközelítéssel azonban egy másik probléma keletkezik: a ma és a közeljövő szervereiben használt DDR3 memória távolról sem olyan gyors mint a bővítőkártyákra épített GDDR5, így egy másik szűk keresztmetszet kerül a rendszerbe.
Ezt a problémát a lapkára integrált memóriával próbálja meg feloldani az Intel. Az ISC-n elhangzottak alapján a Knighs Landing nem kevesebb mint 16 gigabájt DDR4 stackelt memóriát tartalmaz Ehhez a Micronnal állt össze az Intel és az amerikai memóriagyártó Hybrid Memory Cube technológiáját használja. A stackelés, más szóval rétegezés egyik problémája a lapkák közötti kommunikáció biztosítása: a megszokott módszer erre a lapkák élén végigfutó vezetékezés, ez azonban növeli a tok méretét és a lapkák közé tett elválasztóréteg a vastagságot is.
Az AI ára Fizetnek a befektetők, fizetnek a felhasználók, és nagy árat fizet az IT munkaerőpiac is. Vékony jégen járunk. Itt a 85. kraftie adás.
A Hybrid Memory Cube olyan stackelt memórialapkákat jelent, amelyek TSV (thru silicon via) összeköttetésen keresztül kommunikálnak, ez az egymásra rétegezett lapkák belsején végigfutó vezetékeket jelenti, a korábban említett problémák nélkül. A megközelítés hátránya a bonyolult gyártás, de a Micron állítja, több mint tíz év kísérletezés és fejlesztés után megtalálta erre a megfelelő eljárásokat. Az Intel ígérete szerint a Hybrid Memory Cube alkalmazása nem növeli meg számottevően a Knights Landing árát, a teljesítményét viszont igen.
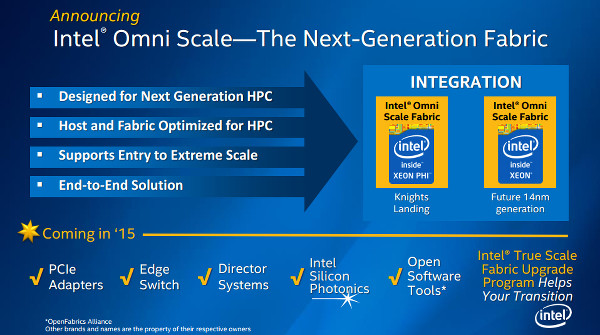
Új interconnect
Az új processzormagok és a stackelt memória mellett a Knights Landing harmadik újdonsága az OmniScale-nek nevezett új interconnect, amelyről az Intel gyakorlatilag semmilyen részletet nem hozott nyilvánosságra egyelőre. A vállalat mindössze annyit árult el az OmniScale-ről, hogy egy teljesen új technológia, amely az InfiniBandnél gyorsabb és jobban is skálázódik. Az Intel 2012-ben tokkal-vonóval megvette a Cray ilyen interconnecteket fejlesztő részlegét, feltehetően az itt megszerzett szakértelem is benne van már az OmniScale-ben. A technológiát az Intel nem kívánja a Xeon Phik területére korlátozni, a vállalat már arról beszél, a egy-két éven belül a kereskedelmi feladatok futtatására szánt "mezei" Xeonokba is bekerülhet az OmniScale.