Saját GPU-val tarolna az adatközpontokban az Intel
A következő évtized elejére datált fontos fejlesztéseinek egy részéről beszélt az Intel. A bemutató alapján a chipgyártó mindent belead a Ponte Vecchio kódnevű GPU fejlesztésébe, amely új mikroarchitektúra mellett chipletes felépítést, illetve fejlett tokozási technológiákat is felvonultat.
Az Aurora szuperszámítógépben debütáló gyorsítót egyszerűen csak az első exascale grafikuskártyájaként emlegeti az Intel, amelyhez az ugyancsak új alapokra helyezett Sapphire Rapids processzor társul majd. A chipgyártó állítja, élvonalbeli technológiáinak megfelelő ötvözésével két nagyságrendnyi gyorsulást mutat majd az új rendszer a jelenlegi megoldásokhoz mérten.
Az AI ára Fizetnek a befektetők, fizetnek a felhasználók, és nagy árat fizet az IT munkaerőpiac is. Vékony jégen járunk. Itt a 85. kraftie adás.
Az előrelépés oroszlánrésze a Ponte Vecchio kódnevű fejlesztés hozza, amely az Intel első 7 nanométeres terméke lesz, habár a GPU nem a gyártástechnológia miatt érdekes. A Ponte Vecchio ugyanis az iparágban elsőként alkalmazhatja az évek óta rebesgetett MCM (Multi-Chip Module) felépítést, vagyis egyetlen grafikus processzor több különálló lapkából épül majd fel. Ezt elsősorban a termelés gazdaságossági szempontjai mozgatják, másodlagosan pedig a felépítés biztosította rugalmasság és a tervezési ciklus alacsonyabb kockázata. Ezzel minimalizálható a selejt hányad, amely optimális esetben a termelés gyorsabb felfuttatását eredményezi. Ehhez hozzájárul a GPU-kra jellemző homogén, a gyártási problémákat jobban tűrő struktúra, melynek hála a mérsékelten hibás lapkákat is viszonylag könnyű felhasználni.

A többlapkás, multi-chip felépítésnek természetesen hátránya is van. A hosszabb vezetékek miatti megnő késleltetés, ám ez a jellemzően sokkal inkább sávszélesség-igényes GPU-k esetében vélhetően nem jelent majd számottevő hátrányt. Nagyobb problémát jelenthet MCM miatti költségesebb tokozás, hisz az egyes lapkákat a nyomtatott áramkörbe ágyazott technológiával kell megfelelően összekötni. Az Intel ugyanakkor régóta aktívan készül az MCM korszak (ismételt) eljövetelére. A chipgyártó az elmúlt években számos fejlett tokozási eljárással állt elő, amelyet a Ponte Vecchiónál fel is használ. A főszerepet a Foveros, vagyis a cég 3D tokozási eljárása kapja. Az iparági körökben jól ismert technológia lényege, hogy a fix interpózert alkalmazó, úgynevezett 2.5D-s megoldásokkal ellentétben egymásra építik a lapkákat, hasonlóan, mint a rétegzett, HBM memóriáknál. Ennek előnye, hogy ilyen módon lényegesen kisebb lehet a komplett processzor tokozása, amely területérzékeny termékek esetében fontos szempont. A 3D tokozásnak hála a funkcionalitás alapján külön lapkákra felosztott, heterogén koncepció előnyéről sem kell lemondani.
Az egyelőre nem teljesen világos, hogy az Intel pontosan miként alkalmazza majd a Ponte Vecchiónál a Foverost. A technológia lényegét tekintve azonban elképzelhető, hogy a kevésbé igényes, rengeteg huzalozást tartalmazó áramköröket (pl. memória- és egyéb I/O-vezérlők) 14 nanométeres technológiával készíti majd a cég, a végrehajtóegységeket (magokat) pedig 7 nanométeren, vagyis a csúcsot képviselő eljárást kizárólag a műszakilag és üzletileg legértékesebb áramkörök kapják meg. A Foveros mellett az EMIB-et is beveti az Intel, vagyis a Ponte Vecchio egyidőben alkalmazza majd a 3D-s és 2.5D-s tokozási technológiákat. Az utóbbira megoldást kínáló EMIB-bel kihagyható az egyes komplex összeköttetést kívánó lapkák (pl. HBM2) beépítéséhez szükséges, az interpózer szerepét betöltő hatalmas, drága szilíciumlapka. Az Intel fejlesztése ugyanis a tokozásba beágyazott apró szilícium szeletekkel (hidakkal) oldja meg a kapcsolat kiépítését, amely mind a komplett chip területére, mind pedig annak gyártási költségeire kedvező hatással lehet.

A termék megjelenési időpontjának távolságát tekintve nem csoda, hogy az Intel egyelőre mélyen hallgat arról, hogy egyetlen lapka (vagyis chiplet) pontosan milyen elemeket tartalmaz majd, mint ahogy a szilíciumdarab méretéről sincs még semmilyen információ. A prezentációban szereplő diákon egyébként kétszer 8 chiplet volt látható. A gyártó e mellett csupán annyit közölt, hogy a chipletes felépítésnek hála akár több 1000 EU-ig (Execution Unit) is skálázódhat majd egyetlen gyorsítókártya, miközben egyetlen EU a jelenlegi Gen11-es fejlesztés teljesítményének nagyjából negyvenszeresére lesz képes duplapontosságú lebegőpontos műveletvégrehajtás mellett.
Rambo gyorsítótár
Az egyes chipleteket az Xe Link köti össze, a HBM2 memóriával való kapcsolatot pedig az XEMF (Xe Memory Fabric) biztosítja majd, amelyekhez bemutató alapján apró inter-node lapkákra is szükség lesz, páronként egy darabra. Érdekes fejlesztésnek hangzik a Rambo cache, amely egy, a Foveros eljárással a GPU-ba ágyazott egységes gyorsítótár, vélhetően DRAM alapokon . Ennek kapacitásáról sincs még információ, ám az elhangzottak alapján kifejezetten nagy, akár gigabájtos tárra lehet számítani, amelyhez a GPU-k és a CPU-k egyaránt hozzáférhetnek majd, magas sávszélesség mellett.
A Ponte Vecchio adatpárhuzamos vektor-mátrix motorja SIMT (Single Instruction, Multiple Thread) és SIMD (Single Instruction, Multiple Data) műveletek végrehajtására egyaránt képes lesz, akár egyidőben. Ebből utóbbi az érdekes, ez ugyanis egy CPU-kra jellemző képesség. Az Intel azonban számos ilyen irányú fejlesztéssel rendelkezik, amelyek leginkább közismert tagja az AVX utasításkészlet család. A chipgyártó ezt a lehetőséget Xeon Phi gyorsítókártyáknál már alkalmazta, az x86-alapú Knights Landing ugyanis képes volt AVX-512 műveletek végrehajtására. Mindez azonban nem hatotta meg a piacot, amely kvázi teljes érdektelenséget mutatott a Xeon Phi termékek iránt, melyet látva az Intel korábban kukázta is a komplett termékcsaládot. Ennek ellenére a vállalat továbbra is indokoltnak látja a SIMD képességek megtartását.
Az egyes GPU-kat, illetve a node-okban lévő CPU-kat a CXL-re (Compute Express Link) alapozó Xe Link köti össze, a kor követelményeinek megfelelően természetesen memóriakoherens módon. Az egyelőre nem világos, hogy a Ponte Vecchio a CXL-lel kvázi csereszabatos PCI Express 5.0-t is támogatja-e majd, az Intel egyik korábban kiszivárgott diája alapján azonban a népszerű busz is jelen lesz a kínálatban.
Szuperszámítógépekhez
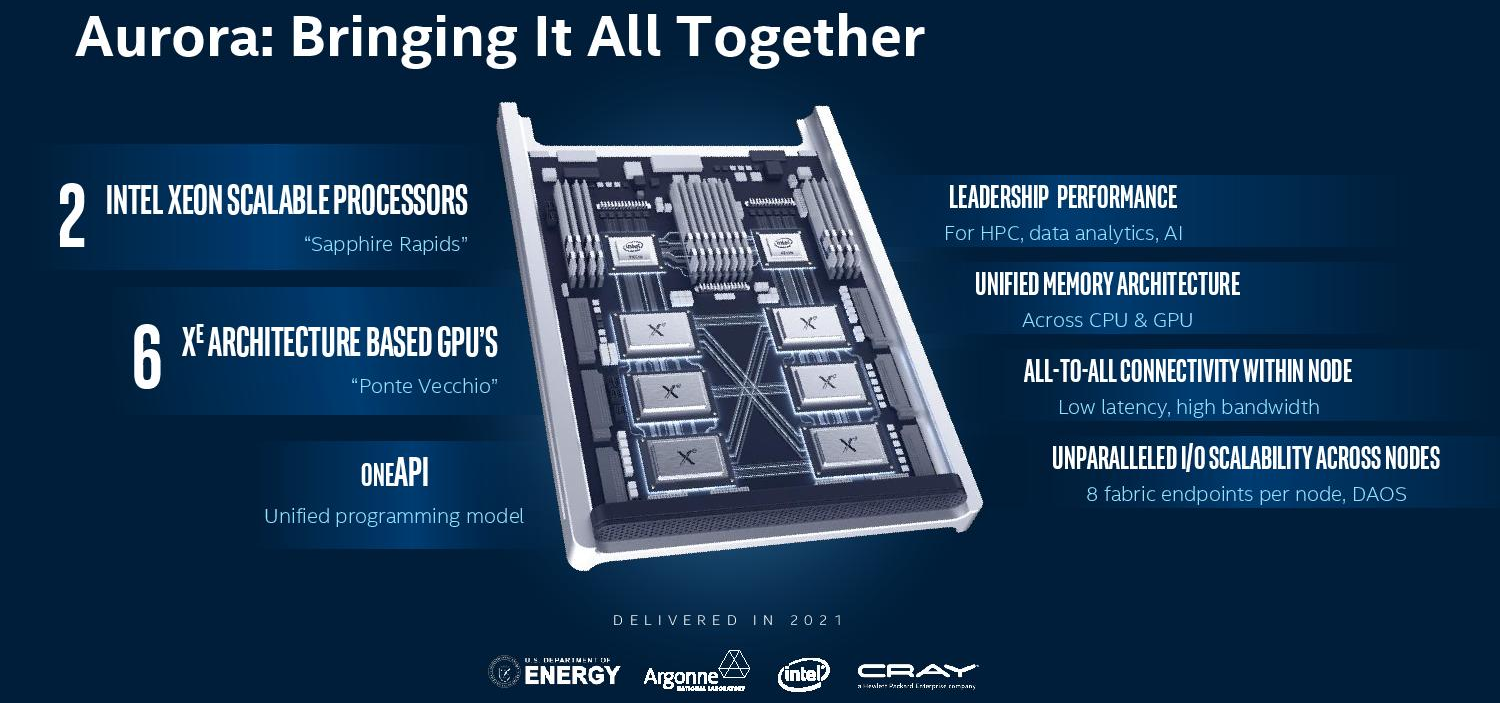
A Ponte Vecchio az Aurora nevű, az amerikai "energiaügyi" (valójában inkább atomügyi) minisztérium (Department of Energy, DoE) által rendelt, 1 exaflops kapacitású rendszerben mutatkozik majd be. Egyetlen node két darab "Sapphire Rapids" Xeon processzort, illetve hat darab Ponte Vecchio gyorsítót tartalmaz majd DDR5 és Optane DC memóriákkal megspékelve a nagyjából 10 petabájtos összkapacitáshoz. Az Aurora több mint 200 rackből épül majd fel, a tárolórendszer kapacitása pedig 230 petabájt lesz.
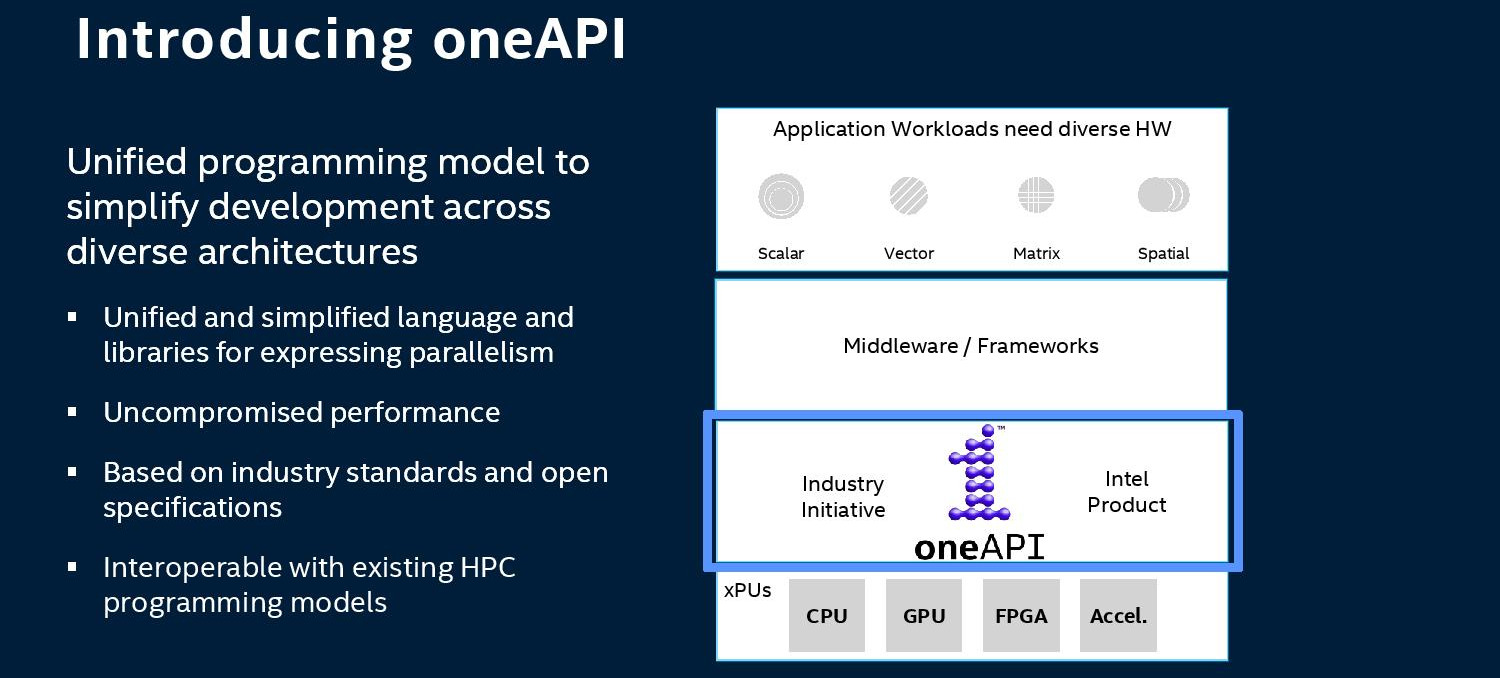
A hardveres felépítés mellett a szoftveres oldalhoz is jelentősen hozzányúlt az Intel, amely DoE-vel közösen beveti a oneAPI-t. A vállalat ígéri, új programozási interfészével egyszerűbben és hatékonyabban aknázható ki a rendszerben lévő összes erőforrás, legyen szó CPU-ról, GPU-ról, FPGA-ról, vagy éppen dedikált AI gyorsítóról. Ehhez ráadásul nem is feltétlenül szükséges Intel hardver, a készítők széles körű kompatibilitás ígérnek, amely irányváltást mutat az évek óta látványosan zárkózott chipgyártó oldaláról. A már publikus béta formában lévő oneAPI-hoz migrációs eszközt is kínál az Intel, amely segít az Nvidia CUDA-ra írt kódok átkonvertálásában.