Így turbózza fel gépi tanulással fotóarchívumát az MTI
Az Azure-re építő arcfelismerő megoldás háttere a Microsoft Tech Summit 2019-en mutatkozott be.
Ha gépi tanulásról és arcfelismerésről van szó, a legtöbbeknek vélhetően valamelyik online képrendszerező szolgáltatás, netán közösségi oldal ugrik be először, amelyek mára kifejezetten látványos eredményeket produkálnak a felhasználók és ismerőseik beazonosításában a feltöltött fotókon. A hasonló technológiák ugyanakkor már egyáltalán nincsenek beszorítva a hasonló szolgáltatások korlátai közé, az intelligens képfeldolgozás mára minden érdeklődő fejlesztő számára elérhető - például a Microsoft Azure Cognitive Services ernyője alatt elérhető Face API-n keresztül.
A megoldásról, illetve annak gyakorlati felhasználásáról Répászky Lipót a vállalat idei fejlesztői konferenciáján, Microsof Tech Summit 2019-en tartott előadásában részletesen is beszámolt. Az MTVA gondozásában működő Nemzeti Audiovizuális Archívum, röviden NAVA fejlesztője és csapata ugyanis az MTI archívumának digitalizálásához vetette be az Azure szolgáltatást. Egy igen masszív dokumentumtárról van szó: az archívum mintegy 20 millió nyomtatott híre mellett többek között 13 millió fotónegatívot, 8 millió rádió mágnesszalagot is tartalmaz. Nem csoda tehát, hogy az MTVA a Microsoft gépi tanulásos megoldásához nyúlt, hiszen ahogy előadásában Répászky is kitért rá, a 13 millió negatív feldolgozása emberi erőforrásokkal, illetve azok felcímkézése a megfelelő metaadatokkal egy kereshető adatbázis kialakításához mintegy húsz év lenne.

Mennyiségi és minőségi ugrás
De nem csak munka mennyiségét segít a technológia leküzdeni, annak minőségét is nagyban javítja. Bár hajlamosak vagyunk azt hinni, hogy arcfelismerésben azért még jobbak vagyunk a hasonló megoldásoknál, az igazság az, hogy az emberi figyelmetlenség gyakran még látványos hasonlóság vagy épp különbség mellett is téves eredményhez vezet két arc összevetésekor. Erre kiváló példa Derren Brown illuzionista kísérlete, melynek során az utcán kért útbaigazítást járókelőktől. A kísérletben Brown helyét egy alkalmas pillanatban észrevétlenül színészek vették át - a járókelőknek pedig az esetek jelentős részében nem tűnt fel, hogy már nem az őket eredetileg megállító férfinak magyaráznak, még akkor sem, mikor Brownt egy női színész váltotta.
Derren Brown - Person Swap
Lorem ipsum dolor sit amet, consectetur adipisicing elit. Doloribus consectetur eaque tempore natus obcaecati ratione ipsum.
Még több videóEnnek megfelelően az MTI archívumaiban lévő ezernyi arc kategorizálásában is jól jöhet a gépi odafigyelés a képek felcímkézése során. A folyamat során az Azure Face API-ja fentről lefelé haladva csoportosítja a talált embereket a fotókon, akiket az arcok alapján számol össze - teljes értékű arcnak, a legalább 200x200 képpontot kitöltő fizimiskák számítanak. A rendszer a nagyobb kategóriákból indulva kezdi szűkíteni a képekhez rendelhető tulajdonságokat: először is azt állapítja meg, erőszak vagy szexuális tartalom látható-e a képen - vagyis az egyáltalán közzétehető-e. Amennyiben az első teszten a fotó átment, a következő lépés az emberek megkeresése, hogy van-e kinek az arcát felismerni - amennyiben igen, a nemek és az életkor meghatározása következik. Ezután jönnek az olyan címkék, mint a jellemző színek, hogy színes, netán szürkeárnyalatos fotóról van szó, illetve a helyszín, kezdve azzal hogy beltéri vagy kültéri beállítást látunk a képen.
Találkozzunk, idén is lesz SYSADMINDAY! Július 17-én lesz a hazai Sysadminday! Standup, üzemeltetői meetup, kvízek, szakmázás, barátok, még több sörcsap.
Egy emberi archivátor jellemzően precíz címkékkel látja el, mint a pontos helyszín és időpont, illetve jellemzően a "kevesebb több" elve mentén dolgozik, ez azonban a szabad szavas kereséseket végző felhasználónál nem a legjobb taktika, hiszen azok sokszor jóval tágabb keresési kategóriákban gondolkodnak, amelyek jó eséllyel nem egyeznek majd az archivátor pontos kifejezéseivel. Az Azure-on működő gépi tanulásos rendszer ezzel szemben már jóval több lehetséges címkét kapcsol az adott képhez, ami a sikeres keresési találatok esélyét is növeli.
Mindenki a PUB-ban köt ki
A címkézéshez, illetve a tágabb-szűkebb kategóriák létrehozásához az MTVA csapata egyedi megoldást alkalmaz: a fotókat, pontosabban a rajtuk található személyeket az Azure felhőjében úgynevezett PUB-okba, csoportokba rendezi. Ezek a valamilyen hasonló tulajdonsággal rendelkező halmazok, amelyeken belül kisebb részhalmazok kialakítására is lehetőség van. Jellemzően méretes csoportok a fotóarchívumban férfiakat, vagy a nőket tömörítő halmazok, de a szemüveges férfiak vagy épp a rövid hajú nők is saját PUB-ot kapnak.
Ezeken belül aztán a hasonló arcokat elkezdi összekötni a rendszer, 80 százalékos hasonlóságnál nevezi azokat azonos személyeknek - ilyenkor egy "person" alcsoporthoz köti őket. A folyamat során szépen elkezdenek csomókba rendeződni a személyek, vagy personokl, közben pedig a rendszer a többi lehetséges csoportban is ellenőrzi, hogy megjelenik-e ugyanaz az arc, ha pedig igen, azt is hozzácsapja a kialakított personhoz. Értelemszerűen minél több fénykép áll rendelkezésre egy adott személyről, a folyamat annál nagyobb összehasonlítási alapból dolgozik és annál pontosabb is lesz.
Persze a rendszer csak azt tudja nagy pontossággal megállapítani, hogy mely képeken található ugyanaz az ember, hogy az a személy pontosan kicsoda, azt már az emberi archivátornak kell megadnia. Az erre vonatkozó információk jellemzően az adott negatívhoz tartozó kézzel írott leírásokban találhatók meg, így előbogarászásuk hosszú időt, egy-egy fotó esetében akár másfél órát is igénybe vehet - komoly segítséget jelent, hogy ezt nem kell szinte minden fotónál megtenni, elég az adott személyt ábrázoló egyetlen képnél.
Nem mindenhol akadálymentes a folyamat
Természetesen a Face API számára is akadnak izmos kihívások - a fotókon éppen szerepet játszó színészek például ilyenek, ahol az algoritmus több esetben nem a színészt, hanem az általa játszott fiktív szereplőt azonosítja, főként ha ahhoz valamilyen jellemző maszk, szakáll vagy egyéb megkülönböztető jegy is tartozik. Ezeknek a szereplőknek a fejlesztők külön kocsmát hoztak létre - az algoritmus betanítása ugyanis az elmaszkírozott színészek valós személyazonosságára ugyanis végeredményben csak butítaná azt, hiszen a személyekre valójában nem jellemező külső tulajdonságokat is tanulna azokhoz.
Ugyancsak kihívást jelent, mikor a rendszer nem élő személyeket ismer fel az egyes fényképeken, hanem például a háttérben a falra akasztott képen csíp el egy arcot. A hasonló fals pozitívok kiszűrése is emberi felülvizsgálattal lehetséges, árulkodó jel lehet például, ha egy személy a halála után készült fotón tűnik fel. A fotók mellett a szobrok is megkavarhatják a rendszert: Kodály Zoltán bronzszobrát például az gond nélkül felismerte, ugyanakkor a népdalkutatót eredetileg tartalmazó, fehér bőrszínű emberek Azure-kocsmájába már nem tudta besorolni, így ismét emberi közbeavatkozásra volt szükség.
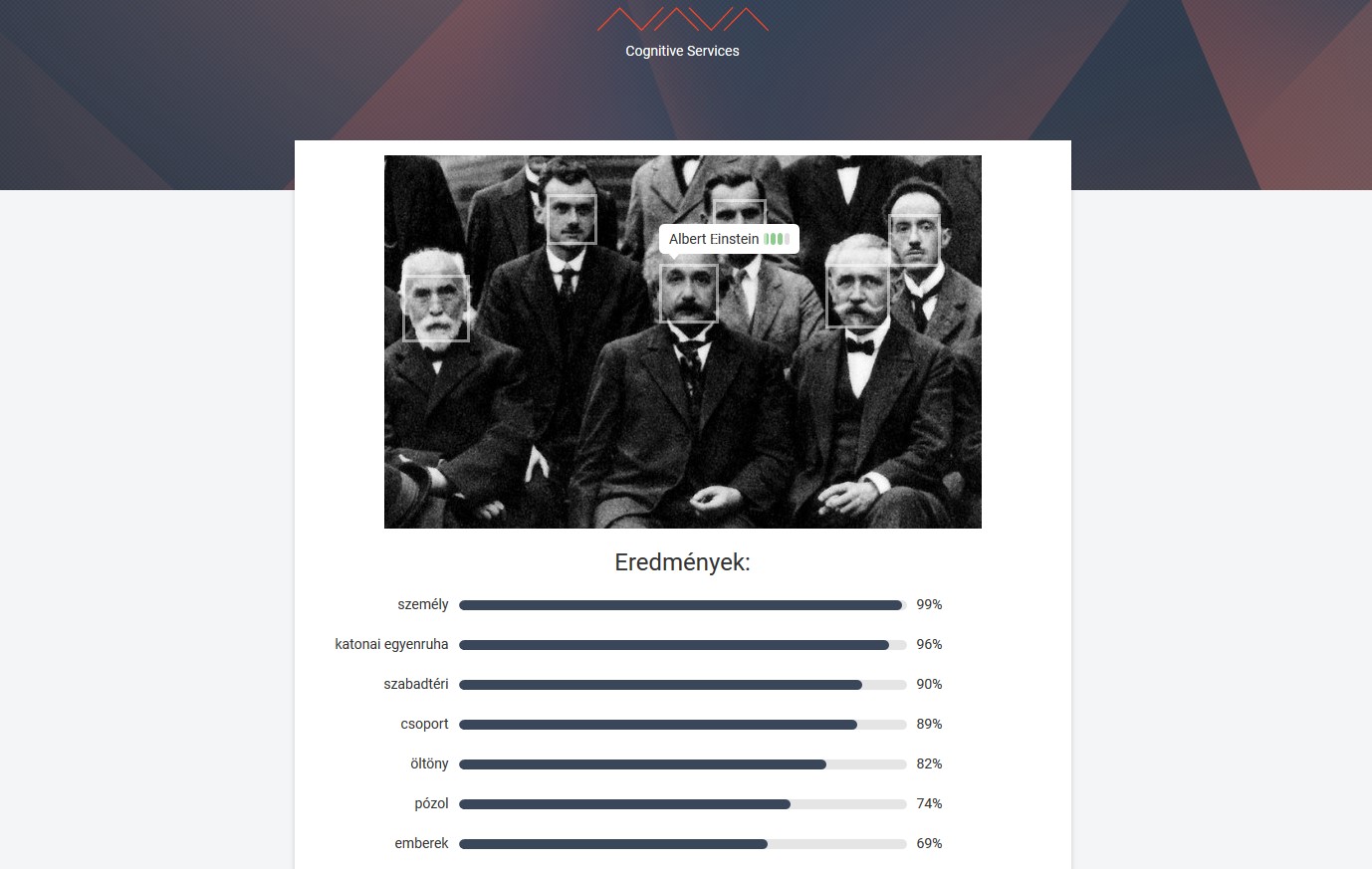
Az Azure Face API-ra támaszkodó személyfelismerési megoldás demonstrálására a NAVA egy dedikált weboldalt is létrehozott, ahol a látogatók tetszőleges képeken tesztelhetik a rendszer képességeit. Az itt megadott képeken található személyt amennyiben az algoritmus felismerni véli, kiírja annak nevét, illetve egy négyes skálán jelzi, hogy milyen biztos az eredményben. A kép alatt továbbá egy sor címkét felsorol, mint "személy", "szabadtéri", "öltöny" vagy épp "pózol", mellette százalékos értékkel jelezve mennyire biztos abban.
A terület iránt érdeklődőknek érdemes lehet eljátszani az eszközzel, illetve az Azure Cognitive Services alá tartozó Face API-ra is vetni egy pillantást - utóbbi részletes dokumentációja elérhető a Microsoft kapcsolódó oldalán.
[A Microsoft megbízásából készített anyag]