Cortex-A55: bemutatkozott az ARM új népmegoldása
Közel öt év után kap utódot a Cortex-A53, a népszerű processzormag helyét a Cortex-A55 veszi át, tömeggyártott processzor formájában legkorábban jövőre. Az új mikroarchitektúra az előddel kitaposott úton megy tovább, az ARM legújabb tervezése evolúciós lépcsőnek tekinthető, az az A53-mal megismert alapokat egészíti ki, illetve finomhangolja, elsősorban a magasabb számítási teljesítmény érdekében.
Bár a feladat elsőre egyszerűnek hangozhat, a tempó növelését a tranzisztorbüdzsé és a fogyasztás számottevő emelkedése nélkül kellett megugrani, amihez elsősorban a szűk keresztmetszetnek bizonyult memória-alrendszert szabta át az ARM, ami számos esetben nem tudta megfelelő ütemben etetni a sorrendi (in-order) végrehajtású mikroarchitektúrát. Ennek fényében az új előbetöltő mellett a maghoz tartozó másodszintű gyorsítótárak is jelentős átalakításokon estek át, ami a tervezőcég szerint az L2 esetében mintegy 50 százalékos késleltetés csökkenést eredményezett. Emellett már harmadszintű gyorsítótár is csatolható opcionálisan a maghoz, ami tovább növeli a sebességet
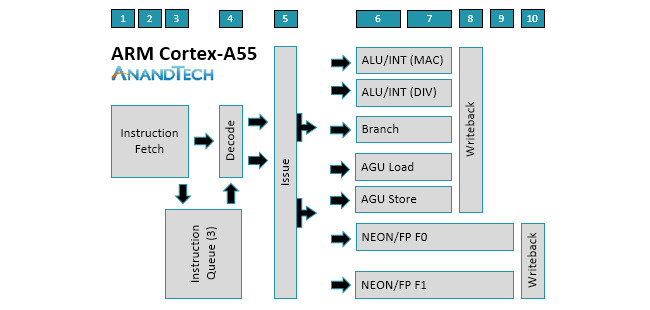
A mikroarchitektúra alapjai nem változtak, maradt a 2 utasítás széles (dual-issue), in-order felépítés a maga 8 fokozat hosszú futószalagjával. Utóbbi egyben azt is jelenti, hogy órajelben az A55 (valószínűleg) nem fogja számottevően felülmúlni elődjét attól függetlenül, hogy az új dizájn várhatóan 10, 7, illetve akár 5 nanométeres gyártástechnológiával is megépülhet majd. A 8 fokozat amolyan arany középútnak tűnik, ennél alacsonyabb értékkel nem csökkent volna jelentősen a fogyasztás és/vagy a tranzisztorok száma, a hosszabb opció pedig nem növelte volna számottevően a maximális órajelet, ellenben a disszipációval.
forrás: AnandTech
Mélyebbre ásva jönnek az apró, de fontos fejlesztések. Ezek közé tartozik, hogy a memóriaműveletek kezelésére immár két AGU (címkiszámító egység) portot találunk, egy dedikáltan a load, egy pedig a store műveletek végrehajtását végzi, szemben az A53 megoldásával, ahol egyetlen, de komplex AGU osztozott a két művelettípuson. Ezzel szemben az egészszámos műveleteket végző két ALU/INT egység nem változott, az egyik képes szorzásra és szorzás-összeadásra, a másik pedig a Radix-16 osztóművel osztásra, a műveletek pedig természetesen akár párhuzamosan is lefuthatnak, jellemzően egyetlen órajelciklus alatt.

A két darab, opcionális 64 bites NEON/FP háza táján kisebb módosításokat látni, így a végrehajtást továbbra is egy 128 bites regiszterfájl szolgálja ki. Az egységek nyolc 8 bites, négy 16 bites, illetve két 32 bites integer, vagy egy 32 vagy 64 bites lebegőpontos utasítást képesek végrehajtani egyetlen ciklus alatt. Az A55 mindezt a félpontosságú, tehát 16 bites lebegőpontos műveletek natív végrehajtásának lehetőségével egészíti ki, ami például bizonyos képi feldolgozásos műveleteknél, vagy gépi tanulás esetben jöhet kapóra. Szintén utóbbira erősít az INT8 műveletek végrehajtásának lehetősége, amit a natív támogatásnak hála az A53-nél négyszer-ötször gyorsabban képes végrehajtani az A55. Ezzel párhuzamosan gyorsult az FMA végrehajtás sebessége, a végrehajtási idő felére, 8-ról 4 ciklusra csökkent.
Gyorsítótárak
A cache-ek terén már sokkal több minden változott, például utasításokat tároló L1I is változott. A korábbi 2-utas megoldás helyét egy 4-utas, de még mindig VIPT (Virtually Indexed, Physically Tagged) rendszerű tár vette át, amelynek kapacitása 16, 32, vagy 64 kilobájt lehet, azaz a legkisebb lépcső duplája az A53 8 kilobájtos opciójának. E mellé társul memóriacím fordítási tár (TLB), amely 15 elemű, és az ARM szerint többféle lapmérettel is megbirkózik.
Fejlődött az elágazásbecslés is, ahol az ARM is beveti a neurális hálózat-alapú (vagy elnevezésű) fejlesztést, akárcsak a Samsung vagy az AMD. Az új rendszerben az ARM több becslőt alkalmaz, a fő algoritmus mellett úgynevezett 0-cycle micro-predictorok is vannak, amelyek bár nem olyan pontosak, mint a központi rész, ezért cserébe viszont gyorsabbak, optimális esetben pedig számottevően csökkenthetik a futószalagban keletkező "buborékokat". Ezt egészíti ki az indirekt becslő, amely csak indirekt elágazások esetén kapcsol be, a hozzá kapcsolódó 256 elemű BTAC (Branch Target Address Cache) tárral együtt.
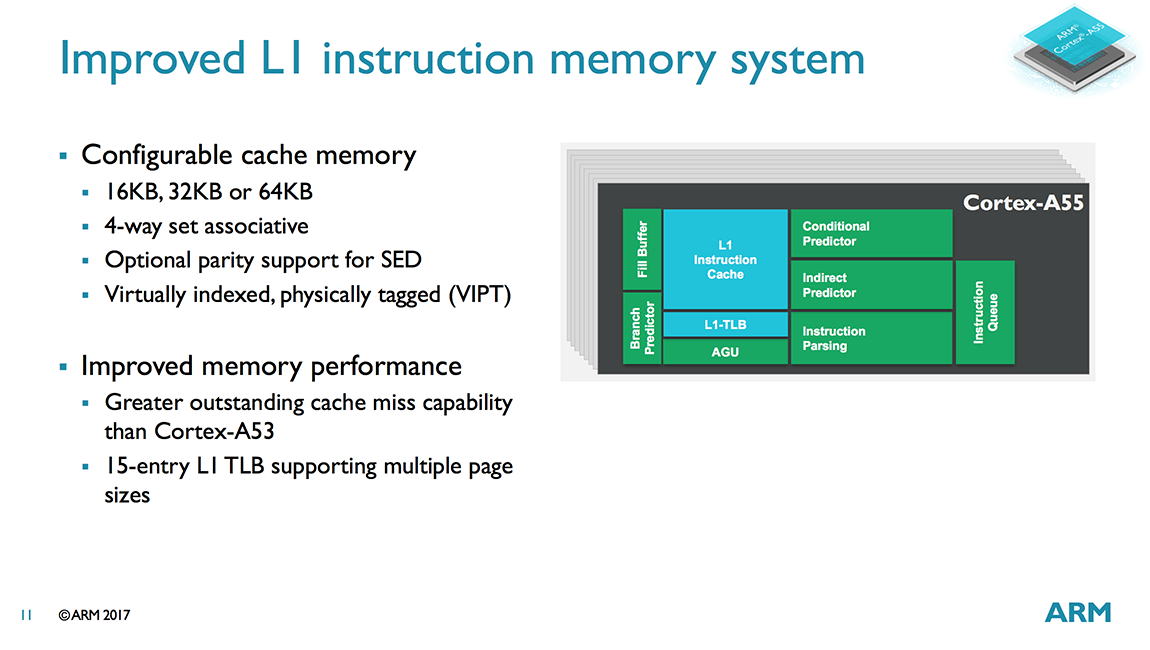
Javult az adat előbetöltés is, amely így nagyobb sávszélességet biztosíthat. A frissített megoldás képes komplexebb cache miss mintákat is felismerni, az adatokat pedig az L1 és az L2 cache-be is be tudja tölteni. Az ARM szerint ennek hatása szabad szemmel is jól látható lesz, például az okostelefonok felhasználói felületének teljesítményénél.
Az L1 adatcache sem úszta meg a változtatásokat, bár a gyorsítótár maradt 4-utas csoport-asszociatív, a korábbi ál-exkluzív (pseudo-exclusive) megoldást teljesen exkluzív rendszer váltotta az ARM. Ez tárhely szempontjából takarékosabb, ugyanis az L1D tartalma nem tükröződik az L2-ben. Búcsúzott az A53 esetében alkalmazott PIPT (Physically Indexed, Physically Tagged) is, helyét pedig az L1I-nél alkalmazott VIPT (Virtually Indexed, Physically Tagged) vette át, aminek hála jelentősen csökkent a késleltetés, ezzel ugyanis a gyorsítótár indexe a TLB fordítással párhuzamosan kereshető.
Az elsőszintű adatcache mérete az L1I-hez hasonlóan 16, 32, vagy 64 kilobájt lehet, tehát a minimum érték ebben az esetben is duplázódott. Ugyancsak meghízott az A53 esetében még 10 tagú micro-TLB, amely az A55 esetében 60 százalékkal nagyobb, immár 16 tagú, aminek hála a store műveleteket alkalmazó folyamatok jelentősen gyorsulhatnak.
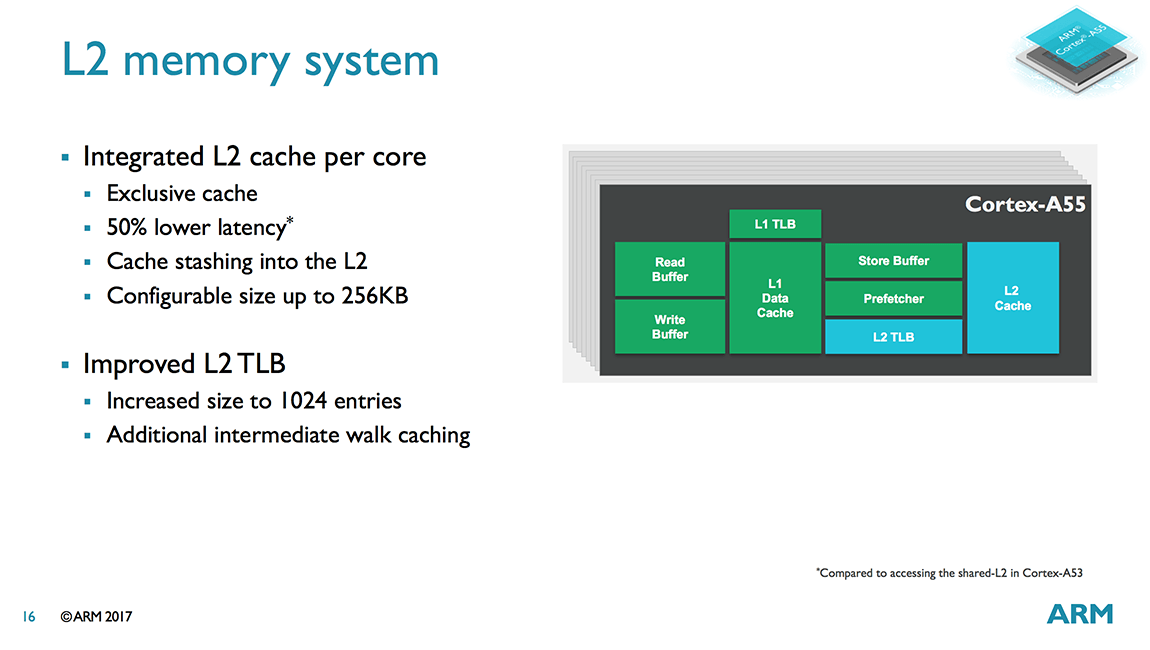
Bár L2 cache alkalmazása továbbra is opcionális, ugyanakkor az a DynamIQ-hoz elengedhetetlen, tehát egy többmagos rendszer esetében kötelező lesz az alkalmazása. A fixen 4-utas, másodszintű gyorsítótár és a mag többi elemének viszonyát szorosabbra fűzte az ARM, így az SRAM már minden esetben magórajelen üzemel, miközben a ciklusidő 12-ről 6-ra csökkent. Az emiatt megugrott fogyasztást az L1D-ből száműzött PIPT (Physically Indexed, Physically Tagged) implementálásával ellensúlyozta az ARM, amely az L2 esetében az alapvetően magasabb késleltetés miatt a gyakorlatban nem jelent hátrányt a VIPT-hez képest. Amennyiben a partner az L2 cache beépítése mellett dönt, úgy 64, 128, vagy 256 kilobájtos kapacitást választhat, az ARM várakozása szerint a középső opció lesz a legnépszerűbb. A három lehetőség mellé fixen egy 1024 elemű L2 TLB társul, ami az A53 értékének duplája.
Találkozzunk, idén is lesz SYSADMINDAY! Július 17-én lesz a hazai Sysadminday! Standup, üzemeltetői meetup, kvízek, szakmázás, barátok, még több sörcsap.
Ugyancsak opcionális a harmadszintű gyorsítótár, ugyanakkor az ARM szerint jelenlétéből sokat profitálhat a rendszer, hisz az in-order feldolgozás rendkívül érzékeny a cache miss jelenségre, azzal együtt pedig a kvázi felesleges memória hozzáférésekre.
Sok hűhó, de mennyiért?
A fejlesztések részletei mellett az ARM a várható teljesítmény növekedésről is szót ejtett, a tervezőcég teljesen azonos paraméterek mellett vetette össze a Cortex-A53 és Cortex-A55 magokat. A népszerű, több egészszámos műveletet futtató SPECint 2006 alatt 18 százalékos előnyt jelentett az új mag, a lebegőpontos SPECfp 2006 csomag alatt pedig 38 százalékos az előrelépés.

Konzumer piacon népszerűbb tesztekben is mért az ARM. A JavaScript végrehajtási tempót vizsgáló Octane v3 alatt szerény 14 százalékot gyorsult az A55, a több különféle műveletet futtató Geekbench v4 alatt pedig 21 százalékos előrelépést mutatott. Mindezért cserébe nagyjából 3 százalékkal nőtt a fogyasztás, ugyanakkor a hatékonyság még ennek ellenére is kedvezőbb, az ezt vizsgáló SPECint 2000 alatt 15 százalékos az A55 előnye.
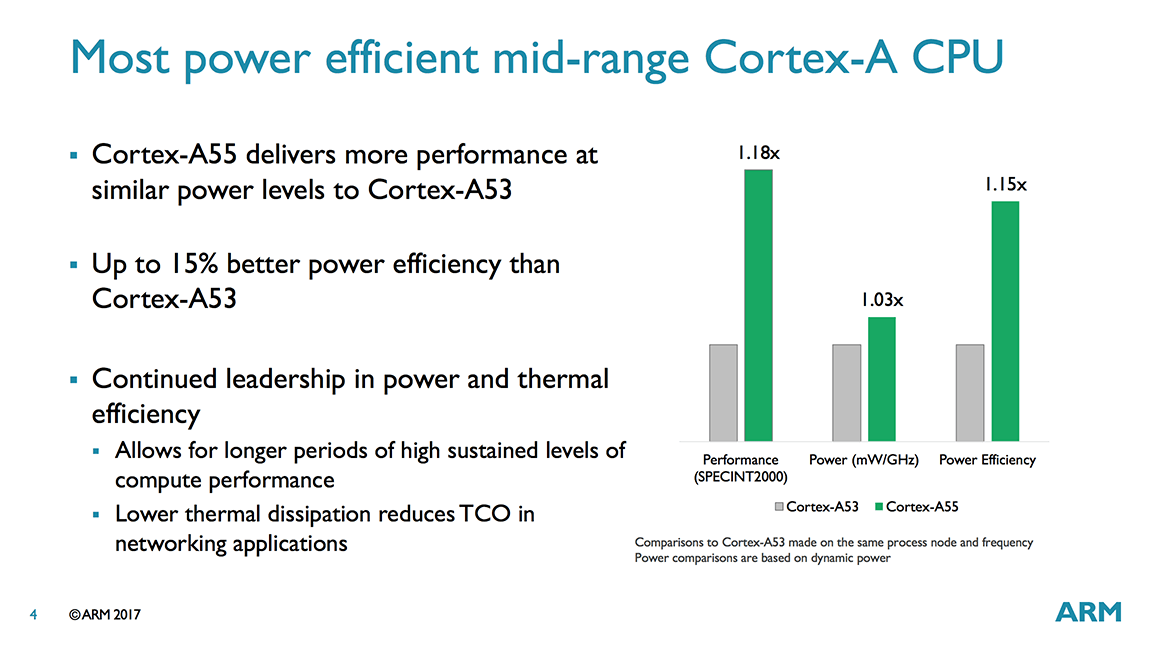
Mindent összevetve az előrelépés nem túl nagy, az öt év alatt elért 10-30 százalékos teljesítménynövekedés eléggé lehangoló. Ugyanakkor azt ismét ki kell hangsúlyozni, hogy az tervezők feladata nem volt egyszerű, hisz sem az A53 tranzisztorbüdzséjét, sem pedig a disszipációt nem léphették túl jelentősen, így a megcélzott területnek megfelelően Cortex-A55 egy erősen kompromisszumos megoldás lett, ami ennek ellenére majd valószínűleg számos alkalmazásprocesszorból köszön majd vissza, ám ez a szerény előrelépés tükrében nem minden esetben lehet jó hír.
A tisztán A55-es magokat felvonultató okostelefonos processzorok a legtöbb esetben nem jelentenek majd igazi előrelépést az évek óta piacon lévő A53-as modellekhez képest, azok mellé mindenképpen kelleni fog legalább egy darab erősebb (A7x) mag is, amire a DynamIQ biztosít majd lehetőséget. Az ARM elmondta, hogy az előd A53-at eddig 40 partner licencelte, és három év alatt nagyjából 1,7 milliárd különféle lapkába került be a középkategóriás mag.