A Facebook is saját tömörítőt fejlesztett
Nem csak a Google fejleszt gőzerővel modern tömörítő algoritmust, a Facebook is előállt saját megoldásával. A Zstandard szintén a veterán zlib helyére lépne, belső használatra ideális lehet.
Új tömörítési algoritmust fejlesztett a Facebook - jelentette be blogján a közösségi óriás. A Zstandard (zstd) névre keresztelt implementációt azon nyomban szabad szoftverként be is dobta a közösbe a cég BSD licenc alatt, forráskódját pedig GitHubon közzé is tette. A Facebook reményei szerint az algoritmus széles körben képes lesz kiváltani a hipernépszerű Deflate-alapú (Zip, gzip, zlib) tömörítőket, magasabb hatékonysága, jobb rugalmassága, modernebb kódolási filozófiája és jobb paraméterezése révén.
Ragyogó skálázódás
Fontos szempont volt, hogy a Zstandard mind sebességben, mind tömörítési hatékonyságban dinamikusan igazodni tudjon az aktuális igényekhez, így több, egymástól gyökeresen eltérő feladathoz is bevethető lesz majd. Ezt sikerült is teljesíteni, az algoritmus 22 fokozatban tud a tömörítési sebesség és a tömörítési arány között egyensúlyozni. Mindezt ráadásul úgy, hogy a specializált algoritmusokkal is fel tudja venni a versenyt - ami nem kis fegyvertény. A zlibbel összehasonlítva azonos sebesség mellett 10-15 százalékkal kisebb kimenetet képez, azonos tömörítési arány mellett pedig 3-5-ször gyorsabb a Facebook szerint.
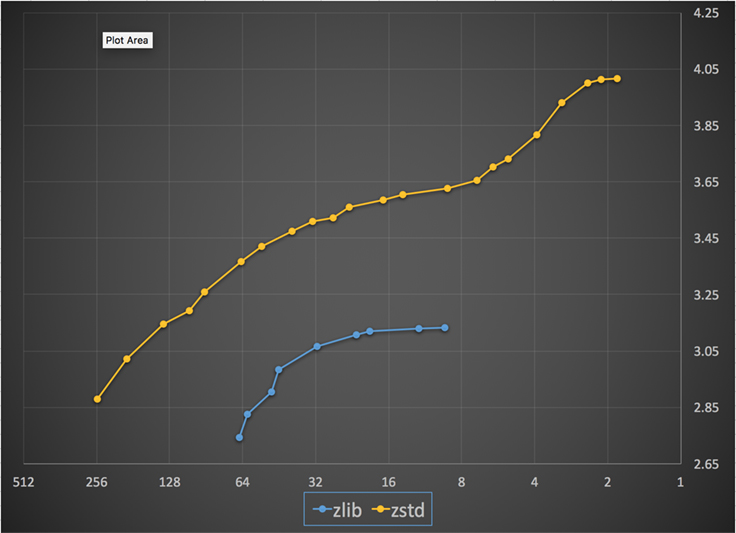
A fokozatok ráadásul nem számítanak a kitömörítésnél, vagyis a magasan ("erősen") tömörített anyagok is ugyanolyan sebességgel csomagolhatóak ki, mint a gyorsan tömörített adatok. Ennek ott van jelentősége, ahol a kitömörítés kliensoldalon (például okostelefonon) zajlik, így ennek erőforrásigényét érdemes a minimum közelében tartani.
Modern CPU-khoz
A fejlesztés során a Facebook mérnökei minden tekintetben igyekeztek a modern CPU-khoz igazítani az algoritmus paramétereit. Az egyik ilyen megfontolás, az elágazásmentes kód, amely segít elkerülni a téves elágazásbecslés esetén a futószalag tartalmának teljes ürítését és a munka újrakezdését. A teljesítménykritikus részek kódolásánál ezért nagy hangsúlyt fektettek a programozók arra, hogy feltételes utasításokat egyáltalán ne használjanak, ami nagyban gyorsítja az algoritmus futását.

Volt feltétel, nincs feltétel. Több munka, mégis gyorsabb.
Az újabb processzorok másik jellemzője, hogy az egyes processzormagok egyszerre több szálon is tudnak dolgozni - amennyiben azok függetlenek egymástól. A programozás során erre szintén igyekeztek a fejlesztők odafigyelni, hogy az egyes threadek egymástól teljesen függetlenek maradjanak és ne várjanak egymásra, így egy-egy magot az algoritmus maximálisan ki tud használni. A bejelentés szerint ezzel a szokásos, többmagos multithreadinghez képest is számottevő előrelépést sikerült elérni, ahogy az algoritmus egy magon egyszerre több szimbólum dekódolását is futtatni tudja párhuzamosan a dedikált adatstreameknek köszönhetően.
A harmadik hardverspecifikus újdonság pedig a kódoláshoz használt csúszóablak mérete. A zlib egy 32 kilobájtos ablakot használ, "ez a 90-es években jó döntésnek számított" - mondják a fejlesztők. A Zstandard ezzel ellentétben nem használ fix ablakot, az adott tömörítési fokozattól függően változik ennek mérete, amely az esetek többségében 1 megabájt (vagy kisebb), de 8 megabájtnál nagyobbra is méretezhető.
De mi hajtja?
A Zstandard lelke a Jarek Duda által kitalált Asymmetric Numeral System, illetve az arra épülő Finite State Entropy. Míg a Huffman-kódolás hátránya, hogy az egyes szimbólumok tömörítési korlátja egy bit, az aritmetikus kódolás már törtszámok használatával áttöri ezt a korlátot. Ez azonban lassú, mivel rengeteg osztást végez, ellenben a sima Huffmanhoz képest jóval magasabb tömörítési arányokat is el tud érni.
A Finite State Entropy ezt csavarja tovább, "ez egy olyan variáns, amely az egyes kódolási lépéseket előre kiszámolt táblázatokba rendezi", ezzel kiküszöböli a roppant lassú osztásokat - az algoritmus csupán összeadásokból, a táblázati adatok kinézéséből és eltolásból (bit shift) áll, emiatt rendkívül gyors tud lenni.
A Facebook szerint a Zstandard szokatlan gyorsasága egészen új alkalmazási területeket is meg tud nyitni a tömörítés előtt. A szokásos területek mellett (naplófájlok archiválása, a tömörített hálózati átvitel, stb.) mellett például adatbázisoknál is bevethető a megoldás. A cég szerint ma már az adatbázis-kiszolgálóknál nagyon eltolódott az egyensúly az IOPS és a tárolókapacitás között, köszönhetően az SSD-k és az in-memory megoldások használatának - vagyis hirtelen a kapacitás lett a szűk keresztmetszet. Az adatbázis-tömörítés másik előnye, hogy a tömörített írás sokkal kevésbé égeti az SSD-ket, meghosszabbítva azok élettartamát.
A Google-féle alternatíva a Brotli, ennek egyik különlegessége, hogy az algoritmus maga tartalmazza a hatalmas fix szótárat (például a Brotli könyvtár részeként), így ez a tömörített állományoknál nem jelenik meg overhead formájában. Ezzel a Brotli egészen kis adatmennyiség tömörítésére is alkalmassá válik. Erre a Zstandard is bevethető lesz, a Facebook ugyanis lehetővé teszi, hogy a könyvtárat használó fejlesztő saját egyedi kódszótárat hozzon létre a saját adatkorpuszából. Mivel a szótárnak előre elérhetőnek kell lennie mind a betömörítésnél, mind a kitömörítésnél, ezt ott érdemes bevetni, ahol mindkét oldalon ugyanaz a fejlesztő készíti a szoftvert - például mobilapp és backend szerver kommunikációjánál.
Na és melyik jobb?
A Google már korábban publikálta saját Deflate-alternatíváját, az LZ77-et és Huffman-kódolást kombináló Brotlit, amely fix könyvtárral és gigantikus, 16 megabájtos csúszóablakkal dolgozik - ezt szeptemberben itt mutattuk be.

A Facebook Zstandard ennek lesz majd versenytársa, az első független összevetések már meg is születtek, a Squash benchmark szerint a két algoritmus nagyjából összemérhető teljesítményű, különösen a középső fokozatokban, de másképp skálázódnak a két extrém felé: a Brotli magas fokozatokon erősebb tömörítést tud elérni (de lassabb), a Zstandard viszont magasabb sebességeknél jobb tömörítési arányt mutat. Ha a sebesség helyett a minél magasabb tömörítési arány a lényeg, akkor az lzma (amelyet a 7-zip is használ) a legjobb, sebességben pedig az lz4 a császár.
A Zstandardot a Facebook több formában is elérhetővé teszi. A zstd parancssoros szoftver mellett könyvtárként, tehát más alkalmazásba beépíthető formában is implementálta az algoritmust a csapat. Jó hír, hogy ezt C nyelven tették, így az gyakorlatilag minden létező platformra lefordítható, PC, szerver és mobileszköz egyaránt megcélozható vele, a zlib egyszerű kiváltáshoz pedig készült egy wrapper is, amellyel egyben cserélhető egyik könyvtár a másikra.