AI: a nem-emberi intelligencia már velünk van? 1. rész
A számos filmet ihlető szuperintelligens AI létrehozásához vezető úton előrébb tarthatunk mint sokan gondolnák. Mi kellett eddig és mi kell még ahhoz, hogy elkészítsük legveszélyesebb konkurensünket? Egyáltalán lehetséges-e, és ha igen milyen következményei lesznek egy hasonló intelligencia érkezésének? Mikor jön vissza Sarah Connor? Ezekre és hasonló fontos kérdésekre keressük a választ a következő cikkekben.
Egy-egy, néhány pohár sörrel megtámogatott eszmecsere során biztosan többen jutottak már arra az elkeserítő konklúzióra, hogy bizony túl későn születtünk bolygónk felderítéséhez, és túl korán ahhoz, hogy a csillagokat bejárhassuk - úgy tűnik világmegváltó vívmányok terén a mindennapokban be kell érnünk az okostelefonokkal, netán a küszöbön lévő önvezető autókkal.
De a helyzet nem ennyire elkeserítő, sőt: lehetséges, hogy hamarosan nem-emberi intelligenciával vehetjük fel a kapcsolatot. És ennek teremtői mi magunk lehetünk. A jövőkutatók szerint nem csak fontos mérföldkőhöz érkezik majd az emberiség még ebben az évszázadban (sőt, akár már annak első felében), de ez lehet fajunk történetének legfontosabb állomása. A mesterséges intelligencia, pontosabban a mesterséges szuperintelligencia megjelenéséről van szó, amelynek segítségével fejlődésünk ma szinte elképzelhetetlen mértékben felgyorsulhat - legalábbis ha túléljük a találkozást.
Cikksorozatunkban a mesterséges szuperintelligencia megjelenésének esélyeit vizsgáljuk meg, hogy pontosan mire lesz mindenképp szükség annak létrejöttéhez, hol járunk most ezen az úton és persze végül a legérdekesebb kérdésre is kitérünk, hogy mi lesz, ha már nem mi leszünk a legintelligensebb faj a bolygón - még ha ezen a téren csak találgatni tudunk is.
Kezdjük az elején
Egy komplex és messzire mutató kérdéskörről van szó, amelynek körbejárásához először érdemes tisztázni néhány ide tartozó fogalmat. Most elsősorban a terület alapjául szolgáló gépi tanulással foglalkozunk, de ízelítőként szaladjunk végig a mesterséges intelligencia kutatásában, illetve a jövőkutatók által használt AI-típusokon. A szakemberek az AI három formáját különböztetik meg, ezek a "keskeny" és általános mesterséges intelligencia, illetve a mesterséges szuperintelligencia, röviden ANI (artificial narrow intelligence), AGI (artificial general intelligence) és ASI (artificial super intelligence).
Az elsőért nem kell messzire menni, ANI-t a legtöbben már a zsebükbe nyúlva is találhatnak. A keskeny AI-okat jellemzően egyetlen funkció vagy feladat ellátására fejlesztik, ilyenek dolgoznak számos, az okostelefonokon használt szolgáltatás mögött, illetve ugyancsak ANI-k győzik le rendre sakk- és gobajnokainkat is. Ezeket már most széles körben használjuk, és bár egy-egy szűk területen összehasonlíthatatlanul jobbak lehetnek nálunk, összességében még mindig nagyon messze vannak az emberi értelemtől.

A következő lépcső az általános mesterséges intelligencia, amely már nem egy-egy specifikus feladatot céloz, esetében már emberi szintű intellektusról van szó, amely nem csak megold bizonyos feladatokat, de tanul, érvel és összetett koncepciókat is megért, illetve az absztrakt gondolkodásra is képes. Ettől persze még messze vagyunk, noha egyes kutatók szerint egy hasonló gépi öntudat már látótávolságon belül van. Az út végét a mesterséges szuperintelligencia jelenti, az ASI minden területen okosabb az embernél - legyen szó nálunk másfélszer, vagy ezerszer intelligensebb AI-ról, azt egyaránt az ASI kategóriába soroljuk.
Már az iskolapadban a gépi tanulók
Ha mesterséges intelligenciáról beszélünk, egy sor további fogalom is előkerül, amelyeket érdemes tisztába tenni, mint a machine learning, vagy gépi tanulás, a deep learning, illetve a neurális hálózatok (neural networks).
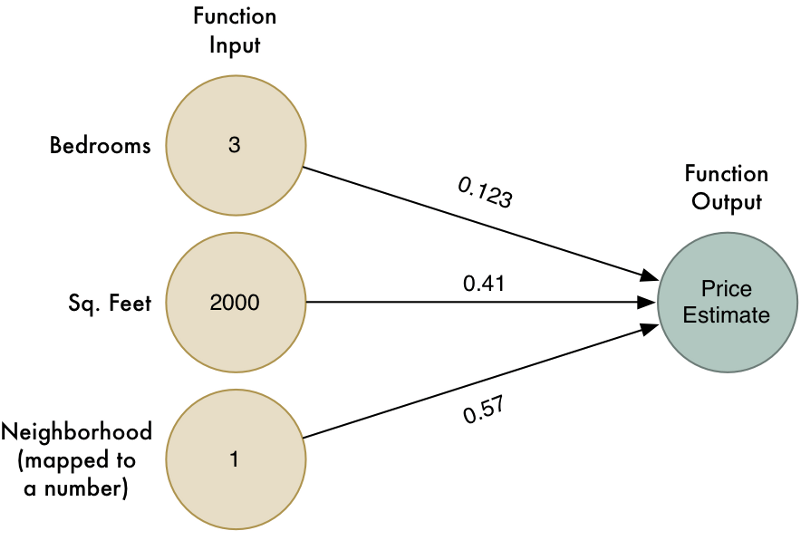
A területre remek bevezetőanyagok lehetnek Adam Geitgey medium.com-os cikkei, aki a gépi tanulást elsőként egy fiktív ingatlan-árbecslő algoritmuson keresztül mutatja be. A példa kifejezetten egyszerű, a rendszer megkap néhány adatot egy sor már elkelt házról és lakásról, mint az elhelyezkedés, az alapterület, illetve szobák száma, valamint a végső vételár, majd a példák alapján megkeresi a fenti paraméterek, illetve az ár közötti összefüggéseket. Később aztán ezek alapján árazza be az újonnan kapott ingatlanokat. A szakértőknek persze folyamatosan lehetőségük van finomítani az algoritmusokon, a különböző paraméterek súlyozásával, azaz különböző szorzókkal pontosítva, hogy egy-egy szempont éppen mekkora szerepet játszik a piaci ár megállapításában.
Az AI ára Fizetnek a befektetők, fizetnek a felhasználók, és nagy árat fizet az IT munkaerőpiac is. Vékony jégen járunk. Itt a 85. kraftie adás.
Itt érdemes tenni egy gyors kitérőt, a machine learningnek ugyanis több típusa is van, a fenti eljárás az úgynevezett felügyelt gépi tanulás kategóriájába esik (supervised machine learning). Ez a széles körben használt módszer feltételezi, hogy a rendszernek egy "tanár" a kiindulási adatokon túl kezdetben a "helyes megfejtést" is rendelkezésére bocsátja - a fiktív példában az értékesítés ténye a "helyes" megfelelője. A gép az így kikövetkeztetett korrelációkat és komplexebb összefüggéseket használja fel később élesben is.
Létezik felügyelet nélküli gépi tanulás is, amelynek során a számítógép csak egy sor adatot kap, bármiféle egyéb útmutatás nélkül. A rendszer ebben az adathalmazban próbál "rendet tenni" és struktúrát, mintázatot találni az információk között. A felügyelet nélküli gépi tanulásnál sok esetben maga a folyamat, vagyis a rejtett mintázatok felfedezése a cél is egyben. Ezen felül léteznek átmeneti megközelítések is, mint a félig felügyelt, illetve a megerősítésre alapuló gépi tanulás.
Hálóban az erő
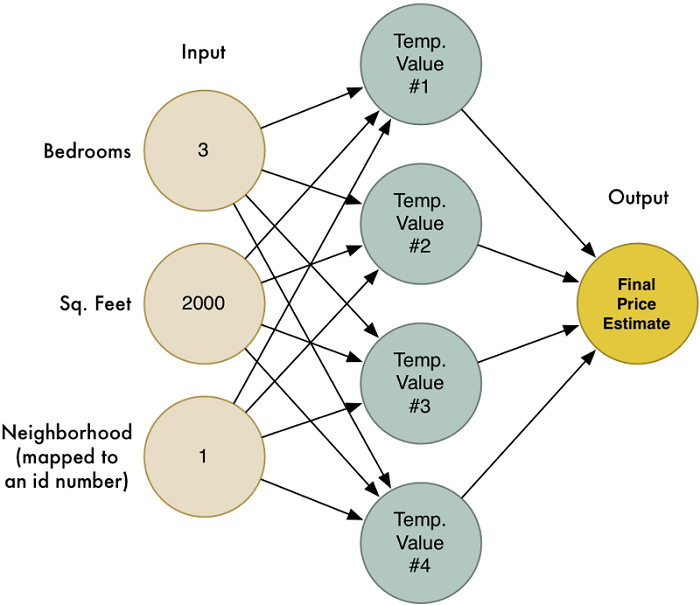
De vigyük a következő szintre a fenti virtuális ingatlanügynököt: az egyes paraméterek nem csak a lakás árára, de a többi paraméter súlyozására is hatással lehetnek, egy-egy kerületben például népszerűbbnek számíthatnak a nagy alapterületű, de egyetlen összefüggő belső térrel rendelkező ingatlanok, máshol pedig a sok szobára osztott lakás lehet sláger. Ennek megfelelően az algoritmust célszerű többször, különböző súlyozások mellett is lefuttatni, aztán ezeket az eredményeket magukat is súlyozni - így ismét számottevően közelebb kerülünk a vásárlókról legombolható összeg maximalizálásához.
Ennél a módszernél az eredeti algoritmus különböző súlyozásokat használó variációi, vagyis az egyes árképzési modellek kvázi node-okként működnek, és egészen kiterjedt hálót is alkothatnak. A rendszer pedig a sikeres modelleket (node-okat) felértékeli, a sikerteleneket pedig elkezdi hanyagolni - pontosan úgy, ahogy a biológiai idegrendszer is működik. Egyes összeköttetések megerősödnek és bejáratódnak, míg mások elhalványulnak és elszakadnak.
Érthető módon minél több kiindulóadatot adunk a gép kezébe, annál pontosabb eredményt kapunk, ugyanígy minél több csomópont alkotja a hálót, annál "okosabb" lehet a rendszer - valahogy úgy, mint az emberi-állati agy esetében. Ezzel a dolgot jelentősen leegyszerűsítve el is érkeztünk az idegsejtek tömegeinek működését mimikáló neurális hálózatokhoz.
A biológiai idegsejt-hálókhoz való hasonlóság tovább növelhető, ha "emlékezet" is társul a rendszerhez, azaz a megadott feladat elvégzése során figyelembe veszi a korábbi munkamenetek során szerzett tapasztalatokat. Jó példa lehet erre az okostelefonokon napi rendszerességgel használt automatikus szövegkiegészítő funkció, amely a felhasználó szokásaira építve, egy adott szótő láttán nem mindig ugyanazt a kifejezést ajánlja fel, helyette az utóbbi időkben jellemzően bepötyögött hasonló szavakat, illetve a szövegkörnyezetet is figyelembe veszi.
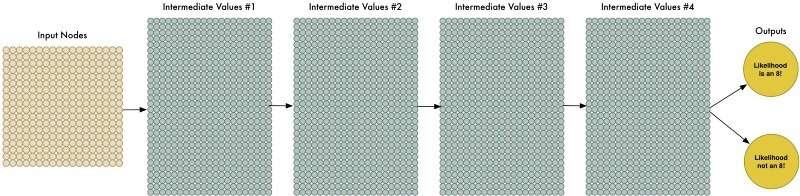
A machine learning lényege tehát már kezd alakot ölteni, de hogy jön a képbe a szintén sokat emlegetett deep learning, illetve a deep neural network? A "mély" tanulás, illetve a "mély" neurális hálózatok mára gyakorlatilag a mesterséges intelligencia szinonimájává váltak, pedig nem különböznek alapvetően a fentebb vázolt gépi tanulási folyamatoktól, noha sokkal hatékonyabban képesek jelentősen nagyobb adatmennyiséget is legyűrni. Persze ahogy azt nevük is sejteti, a "mély" hálózatok összetettebbek mezei társaiknál - a fő különbség, hogy itt a különböző súlyozású, köztes eredményekből a rendszer több réteget is bevet. Így jóval nagyobb mennyiségű adat feldolgozására is lehetőség van, ennek megfelelően pedig sokkal pontosabb eredmények kaphatók, illetve a gép jelentősen komplexebb problémákra is ráereszthető.
Bár a deep learning koncepciója már közel fél évszázada velünk van, csak a GPU-k teljesítményének növekedésével vált praktikussá a használata, azok ugyanis sokkal hatékonyabban birkóznak meg a területen szükséges mátrixszorzási feladatokkal, mint a hagyományos processzorok.
Adatok, adatok, adatok
A megoldással tehát nagy mennyiségű adat dolgozható fel hatékonyan, ami azért kiemelten fontos, mert a gépi tanulás, illetve az arra építő alkalmazások pontossága az esetek túlnyomó részében sokkal nagyobb mértékben múlik a rendelkezésre álló kiindulóadatok mennyiségén, mint azon, mennyire szofisztikált az azokat megrágó algoritmus. Legtöbbször sokkal jobban járunk egy "butácska" mély neurális hálózattal, amelyet temérdek információval látunk el, mint egy elképesztően kifinomult rendszerrel, amelynek viszont csak korlátozott volumenben állnak rendelkezésére adatok.
Hogy a mennyiség kérdése mennyire fontos, jól látszik a hasonló rendszereket igen aktívan használó online szolgáltatások üzletpolitikájából is: a Google Photos szolgáltatásába például korlátlan mennyiségben, "ingyen" tölthetünk fel fényképeket, valójában azonban természetesen szó sincs díjmentes tárhely-használatról, a képekből a Google rengeteg, kincset érő információt tud kibányászni. A feltöltött fotókkal a rendszer képfelismerő algoritmusa egyre okosabb lesz, közben pedig a fényképeken azonosított tartalomnak hála az adott felhasználóval is egyre szorosabbra fűzi ismeretségét a vállalat - persze ez utóbbit az adott régió szabályozásai korlátozhatják (az EU-ban például nem érhető el a szolgáltatás arcfelismerő része). A Google adatéhségét persze valószínűleg senkinek nem kell bemutatni, aki járt már a history.google.com oldalon, aki pedig még nem tette meg, érdemes felkeresnie a felhasználói előzményeket összegyűjtő weblapot.
A gépi tanulás, még ha a "legkeskenyebb" AI formájában is de már jól látható módon átszövi a mindennapokat - igaz egyelőre az emberhez vagy akár az állatvilág jelentős részéhez képest kifejezetten "buta" mesterséges intelligenciáról van szó. Azt azonban fontos kiemelni, hogy a beviteli adatok beadásán és az eredmények súlyozásán túl az eredményeket, illetve a tulajdonképpeni működés már most sem "emberi". A fejlesztők által megírt algoritmus ugyanis csak "meta", vagyis azt teszi lehetővé, hogy a tulajdonképpeni mintázatfelismerő algoritmus létrejöjjön.
Igaz ez például a gobajnokot verő Google-féle AlphaGo működésére is. Emberi fejlesztők írták azt a programot, amely rögzíti a go játék szabályait, és képes eldönteni a sikeres és sikertelen kimenetet és felruházta mintázatfelismerő képességgel. A rendszer a fentiek birtokában lejátszott saját magával néhány milliárd mérkőzést, ezek során azonosította a sikeres és sikertelen mintázatokat és stratégiákat, majd ezeket élőben is kipróbálta emberi játékos ellen. És ugyan az eredeti programozást értjük és ismerjük, a gép által felfedezett mintázatok és stratégiák visszafordítása már gyakorlatilag lehetetlen - az ezeket leíró adatsor ugyanis maga a neurális háló. Ilyen értelemben tehát már beszélhetünk nem-emberi intelligenciáról, igaz, az még csak igen specifikus területekre szorult be.
Addig még sok víz lefolyik a Dunán, hogy egy, akár csak az emberével megegyező értelmi képességű AI-t hozzunk létre. Ehhez ugyanis rendkívüli számítási teljesítményre lesz szükség - a vas kérdését (spoiler alert: kvantumszámítógépek) következő cikkünkben vizsgáljuk meg, ahol néhány említésre méltó, jelenleg "alkotó" AI-ra is kitérünk. Később vitatottabb területek következnek, beleértve a kérdést, valóban exponenciálisan gyorsul-e az emberiség fejlődése, és ha igen, hol helyezkedünk most el az égbe tartó görbén - és meddig maradunk rajta. Maradjatok velünk!