Látogatás a Fujitsu Siemens Computers fejlesztői központjában
Európa legnagyobb IT-szállítójának szervereit és tárolóit Paderbornban nyúzzák és finomhangolják a német mérnökök, hogy kevés gond legyen velük, és kellően nagy teljesítményt nyújtsanak. A gépekkel csurig pakolt, zajos laborok mellett a cég bemutatta középvállalatoknak szánt egyszerű szerver- és tárolómegoldásait.
Minőségellenőrzés Fujitsu Siemens módra
A Dortmund és Hannover közelségében fekvő Paderborn egyike a Fujitsu Siemens Computers (FSC) fejlesztői központjainak. A 144 ezer lakossal bíró városban a vállalat kiszolgálóinak és tárolóinak tesztelése, finomhangolása és továbbfejlesztése folyik. A volt siemensesek által működtetett német-japán vegyesvállalat Augsburgban, Sömmerdában, Münchenben és Sunnyvale-ben, a Szilícium-völgyben rendelkezik még hasonló és termelést is végző telephelyekkel. A FSC a 2006 márciusával záródó üzleti évben 6,65 milliárd euró forgalmat bonyolított, amihez társul egy 1,3 milliárdos szolgáltatási leányvállalat. Az FSC felségterülete az EMEA szuperrégió (Európa, Közel-Kelet, Afrika), míg a japánok a világ többi részét fedik le.
A paderborni létesítményben számos labor található, amelyek közül a minőségellenőrzést és -fejlesztést, a teljesítményteszteket, valamint az FSC alkalmazottainak és partnereinek továbbképzését szolgálókban jártunk. A minőségellenőrzést végző részlegeken szó szerint tömve voltak a helyiségek néhol irgalmatlanul zajos szerverekkel és tárolóberendezésekkel (sajnos fotókat nem lehetett készíteni), melyeket folyamatosan magas terhelésnek tesznek ki, hogy adatokat nyerjenek a meghibásodási rátákról és azok okairól.
Az egyik teremben egy rack kivitelű szalagos archiváló robotikájának repetitív tesztje folyt éppen. Az egyik vezető mérnök elmondása szerint például a szalagos rendszereknél a mai napig problémát okoz a belső mechanika esetleges pontatlansága vagy meghibásodása, ami akár az összes szalagot hozzáférhetetlenné teheti, megakadályozva az adatmentést, és kockázatnak téve ki ezzel az adatok biztonságát. Okos szoftveres megoldással elérhető, hogy a mechanika valahogy mégis hozzáférjen a szalagokhoz, de egyes esetekben manuális beavatkozásra lehet szükség, ami a nagy számok törvénye alapján jónéhány eszköznél biztosan bekövetkezik, az alacsony arány ellenére azonban így is kínos lehet az ügyfél előtt.
A szalagos tárolók másik érzékeny pontját természetesen maguk a kazetták, azon belül is a szalagok képezik. A vállalat szerint egy kazettának 10 ezer teljes írási ciklust el kell tudni viselnie, ami a gyakorlatban nemigen fordulhat elő. Arra a kérdésre, hogy egy szalag meddig képes nagy biztonsággal megtartani a rajta tárolt adatokat, azt a választ kapuk, hogy statisztikailag 30 évig biztosan, erre azonban nincsen valódi garancia. A mágnesszalagok még így is a magasan legmegbízhatóbb adattárolási megoldásnak számítanak manapság is.
A merevlemezek úgyis elhullanak
Míg a szalagokat teljesítményüknél fogva rendszeres archiválásra vagy adatmentésre alkalmazzák, addig a merevlemezek feladata a szerverek közvetlen ellátása. A magasabb teljesítménynek azonban ára van: a merevlemezek képezik messze a legnagyobb forrását a hardverhibáknak, és ezt nem csak a FSC állítja. Egy nagyobb storage rendszerben kiküszöbölhetetlen, hogy a nagy terhelés alatt álló tömbökben hulljanak a lemezek, akármilyen minőségbeli előírást alkalmaznak.
Legyen szó akár kommersz SATA, vagy akár felsőkategóriás SAS-meghajtókról (ne feledjük utóbbiak sokkal nagyobb mechanikai megterhelésnek vannak kitéve), a tesztlaborban legfeljebb 1-2 nap telik el anélkül, hogy egy-egy merevlemez meghibásodását jelezzék a szoftverek. Pontosabban többnyire a meghibásodás közeledtét, ugyanis detektálható a közelgő vég a olvasási, írási, pozicionálásbeli hibák exponenciális szaporodtával -- jelen sorok szerzőjének merevlemeze is éppen ebben "hibázgató" szakaszban tart.

A RAID-technológiáknak és diagnosztikai megoldásoknak köszönhetően azonban mára egy hibás merevlemez semmilyen körülmények között nem eredményezhet adatvesztést, egy cég üzletmenetében ugyanis ez ma már elfogadhatatlan. Ennek ellenére az FSC tapasztalata az, hogy a nagyobb lemeztömböket alkalmazó ügyfelek nemtetszésüket fejezik ki a viszonylag sűrű meghibásodások miatt. Az individuális meghajtókra megcélzott meghibásodási idő középértéke 1 millió üzemóra, amitől a gyakorlatban minden bizonnyal elmaradnak a merevlemezek, de még ilyen mutatók mellett is a nagyvállalati rendszerekben heti, vagy akár napi szinten hullhatnak.
A hardverek mellett természetesen a szoftveres összetevőket is tesztelni kell, és nem utolsó sorban a hardver és a szoftver együttműködését a legelképzelhetetlenebb szituációikban is. Az FSC paderborni laborjaiban például 4-12 hét közötti időt tölt el egy-egy újabb firmware, mielőtt nyilvánosan hozzáférhetővé válik, de a tárolók számos szerver és szoftverkörnyezetben való működése ellenőrzést igényel.
Ez az aspektus kifejezett figyelmet érdemel a szerverek esetében a virtualizáció fokozódó jelenléte miatt, ugyanis ez minden korábbinál heterogénebb szoftverkörnyezetek létrejöttét teszi lehetővé. Ottjártunkkor az egyik blade rendszerben az egyik gépen virtualizálva futó Windows Server 2003 platformot migrálták futás közben egy másik fizikai gépre, miközben az videolejátszást futtatott. A migráció anélkül megtörtént, hogy bármiféle emberi beavatkozásra szükség lett volna közben vagy azt követően, a videó is csak néhány pillanatra szaggatott be -- az Ethernet és storage címek is automatikusan konfigurálódtak. Bár a virtualizáció nem újdonság, látni egy ilyen demót mindig impresszív.
 Paderborn, a benchmarkolás fellegvára
Paderborn, a benchmarkolás fellegvára
A minőségellenőrzés mellett Paderborn másik nagy erőssége a benchmarkolás, vagyis a teljesítménymérés. Ez lényegében ugyanaz, mint amit a PC-s lapok is művelnek a 3DMarkkal és társaikkal, csak ebben az esetben egy egész, szerverekkel és diszkrendszerekkel csurig rakott teremben folyik mindez, nagyságrendekkel nagyobb ember-, idő- és pénzráfordítással. A benchmarklaborban több tucatnyi szerver és összesen több ezer merevlemezt tartalmazó tárolók találhatóak, amelyek akár 90 kilowattot is fogyaszthatnak. A terem hűtéséhez már integrált légkondicionáló rendszer szükséges.
Az FSC büszke a paderborni benchmarklaborjára, ugyanis számos világrekordot tartanak olyan iparágilag elfogadott tesztekben, mint a SPEC, a TPC vagy az SAP S/D. Egy-egy végleges szám publikálásához jellemzően 30-50 mérés szükséges, így egy-egy lefutás idejétől függően akár több napot is igényelhet egyetlen rendszer egyetlen benchmarkja. A túrát vezető mérnök szerint az egyik, ha nem a legkellemetlenebb benchmark a Microsoft Exchange, mivel a mérést végzőnek kell számos iterációval belőni a kiszolgáló maximális kapacitását a megcélzott válaszidő mellett. A másik rettenet a TPC-C, mely gigantikus háttértárat igényel, hogy etetni tudja a szervereket.
Felmerül a kérdés, hogy a gyakorlatilag bárki által hozzáférhető építőelemekből álló x86-os rendszerekben hol lehet előnyt találni, valamint hogy mi a valódi haszna ezeknek a méréseknek. Miközben itt hardvereket mérnek, az előnyt szoftveres finomhangolással lehet elérni, amibe beleértendő a BIOS-tuningolástól kezdve az operációs rendszeren és a compiler-optimalizációkon át az alkalmazások finomhangolásáig minden. A mérések nemcsak jó PR-t hozhatnak a cégnek, hanem visszajelzést szolgáltatnak a hardver- és szoftvermérnököknek, hanem know-how-t is biztosítanak a termékek értékesítésében nagy szerepet tanácsadók számára is, akik nemcsak teljesítményszintekre tudnak ígéretet tenni ezek alapján, hanem képesek így azt az ügyfélnél realizálni is.
[oldal:Szerverek és tárolómegoldások középvállalatoknak]
Új PRIMERGY kiszolgálók középvállalatoknak
A FSC a két héttel ezelőtt megrendezett CeBIT-re időzítve bővítette PRIMERGY szervercsaládját, valamint egy olyan FibreCAT storage megoldást mutatott be, melyeket kifejezetten a közepes méretű, 100-1000 alkalmazottat foglalkoztató vállalatoknak szán. Miután a nagyvállalati piac telítődött, úgy a szállítók figyelme egyre inkább a kisebb cégek kiszolgálása felé fordul, melyeknek IT-igényei szintén jelentősek, anyagi lehetőségeik és IT-szakértelmük azonban korlátozott.
A PRIMERGY RX300 S3, RX330 S1 és Econel 230R rack kivitelű szerverekkel a FSC kifejezetten a piac középső részének jobb lefedését célozza. A 2U magas RX300 S3 adatközpontokba szánt modell, nagy teljesítményt, skálázhatóságot és redundanciát vonultat fel Intel-alapokon. Két négymagos Xeon fogadása mellett 32 gigabájtos nyers memóriakapacitást kínál, és 6x300 gigabájt SAS vagy 6x500 SATA háttértárnak képes otthont adni.

Az RX330 S1 már Opteronokra épül, képességei nagyjából megegyeznek xeonos társáéval, azonban memóriatükrözésre nem képes, és kevesebb bővíthetőséggel rendelkezik. Az Econel 230R pedig lényegében az RX330 S1 redundanciától megfosztott, költséghatékony változata. A gépekben három szeparált légcsatorna biztosítja a levegő minél könnyedebb áramlását, hogy a hőmérsékletet a lehető legalacsonyabban tartsa.
Storage egyszerűen
A szerverek mellett egyre inkább felértékelődik a tárolók szerepe, ahogyan a középvállalatok által termelt és igényelt adattömeg is exponenciálisan növekszik. Ide a FSC FibreCAT termékcsaládjának SX60 és SX80 online storage termékeit célozza, melyek a vállalat "My very first SAN" (kb. A legelső tárolóhálózatom) csomagjának részét is képezik. Az SX60 az alacsony belépési költséget célozza meg SATA meghajtóival, és 2x12 lemezig skálázhatóságával, míg az SX80 már inkább a nagyobb vállalatok igényeit hivatott kielégíteni, akár 56 SAS/SATA diszk befogadására is képes másodpercenként 4 gigabites átviteli sebességgel.
Az SX60 és SX80 által felvonultatott képességek közé tartozik a FibreCap. A FibreCap a storage-ban található szuperkondenzátor elnevezése, mely az akkumulátort váltotta fel. A kondenzátor előnye, hogy sokkal hosszabb várható élettartammal rendelkezik, kevesebbe kerül, továbbá egy esetleges áramszünetet követő újbóli indításkor néhány percen belül feltöltődik, így a vezérlőkön található cache-ek védettséget élveznek. Azokban a modellekben, ahol a vészleállást (a cache-ek tartalmának a flash chipre kiírásához szükséges időt) akkumulátor hidalja át, az újbóli beindítást követően hosszú órákig védtelenek egy esetleg újabb áramkimaradással szemben, így a vállalat vagy adatvesztést kockáztat, vagy kikapcsolja a cache-t, ami viszont a teljesítményt fogja vissza drasztikusan.
A My very first SAN egy megoldás középvállalatok számára, azonban nem összetevők fix kombinációit tartalmazza, hanem egymással gond nélkül együttműködő, minősített eszközöket, valamint a javasolt eszközök révén egy útmutatót egy tárolási hálózat (SAN, storage area network) kiépítéséhez. A My very first SAN egy FibreCAT SX60 vagy SX80 eszközöket, Brocade SilkWorm Fibre Channel switcheket és Emulex adaptereket tartalmaz a szükséges szoftverekkel a központosított tárolás érdekében.
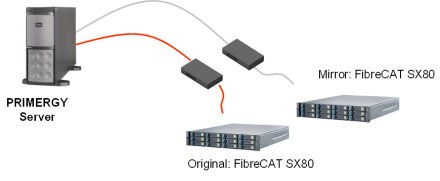
A csomag képes hibatűrő multipathingra (mikor egy tárolóhoz két független fizikai csatlakozás vezet), és akár valósidejű tükrözésre (két párhuzamos, független FibreCAT ugyanazt tárolja), ehhez azonban szükséges a DuplexDataManager szoftver. Amennyiben a FibreCAT-ek mellé egy PRIMERGY szervert is vásárol valaki, ingyen kapja az alkalmazást. A FibreCAT-ek mellé ingyen jár a Computer Associates Brightor ARCserve Backup adatmentési, valamint a XOsoft Enterprise Rewinder folyamatos adatmentési szoftverei.
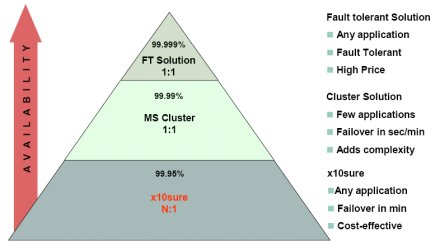
x10sure: megfizethető(bb) redundancia
 Továbbra is a középvállalatoknál maradva, a FSC Paderbornban prezentálta magas rendelkezésre állást biztosító, költséghatékony megoldását. Az x10sure koncepciójának lényege, hogy egyetlen tartalék szerverre van mindössze szükség az egész szervezetben, és egy automatizált monitorozó rendszer a meghibásodott szervert leállítja, majd az online storage-ból a tartalékra tölti be a rendszerképet, és bootolja fel. A megoldás két szépséghibája, hogy magának az x10sure szoftvernek is dedikált szerverre, valamint centralizált tárolóra van szüksége. Így kijelenthető, hogy 2-3 szervernél már nem éri meg a befektetést, a kiszolgálók számának növekedtével azonban egyre vonzóbbá válik.
Továbbra is a középvállalatoknál maradva, a FSC Paderbornban prezentálta magas rendelkezésre állást biztosító, költséghatékony megoldását. Az x10sure koncepciójának lényege, hogy egyetlen tartalék szerverre van mindössze szükség az egész szervezetben, és egy automatizált monitorozó rendszer a meghibásodott szervert leállítja, majd az online storage-ból a tartalékra tölti be a rendszerképet, és bootolja fel. A megoldás két szépséghibája, hogy magának az x10sure szoftvernek is dedikált szerverre, valamint centralizált tárolóra van szüksége. Így kijelenthető, hogy 2-3 szervernél már nem éri meg a befektetést, a kiszolgálók számának növekedtével azonban egyre vonzóbbá válik.
Az x10sure olyanoknak kíván rendelkezésre állási megoldást kínálni, akiknek ugyan szüksége lenne rá az üzletmenet folytonosságának biztosításához, ugyanakkor a nagyvállalati klaszterizált és teljesen hibatűrő megoldásokat nem tudják megfizetni -- mivel olyan szintű rendelkezésre állásra sincs valójában szükségük. Az x10sure révén egy meghibásodást követően néhány perc alatt rendelkezésre áll a tartalékszerver rajta az éles környezettel, és az eredeti gép hálózati címeivel (LAN, LUN, SAN). Az eljárás teljesen független az alkalmazástól, ugyanakkor az újrabootolást követően esetleg szükség lehet emberi beavatkozásra az alkalmazások konfigurálásához.
Az x10sure-t futtató és a tartalék szerver anélkül telepíthetőek egy éles környezetbe, hogy arra bármiféle hatással lennének, a védelem működéséhez kliensek telepítésére, módosítására nincs szükség. A konfiguráció rendkívül egyszerű, mindössze a tartalék gépet és a tárolót kell "megmutatni" a szoftvernek, és néhány percen belül életbe lép a védelem. Jelen sorok írójának két másik újságíróval együtt egy csapatot alkotva 8 percen belül sikerült egy lépésről-lépésre leírás alapján telepítenie, konfigurálnia, és élesítenie az x10sure-t. A megoldás előfizetéses alapon működik, az árak évi 10 ezer eurótól kezdődnek, ez az összeg 5 szerver felügyeletét foglalja magában. Hazánkban az x10sure az év későbbi részében válik hozzáférhetővé.
[oldal:Eljött a szerverek kikapcsolásának ideje]
Az álló lovak is túl sokat esznek
A középvállalatoktól az adatközpontok felé felé fordulva a Fujitsu Siemens is egyre nagyobb figyelmet fordít az energiatudatosságra, mint az informatikai fejlődési irányvonalat döntően formáló szempontra. A szerverek számából, átlagos fogyasztásból, és az energiaárak növekedéséből kifolyólag a vállalatoknál, és főként az adatközpontokban kiemelt hangsúly helyeződik az energia hatékony felhasználására. Egy, az AMD megbízásából készült tanulmány becslése szerint 5 év alatt a szerverek és a hűtésükhöz szükséges eszközök együttes globális fogyasztása megduplázódott, és meghaladta a 120 milliárd kilowattórát, ami mintegy 8 milliárd dollárjába került az üzemeltetőknek.
A szerverek száma és a növekvő fogyasztás egyúttal az egyre sűrűbb meghibásodást is magával hozta, ugyanis a magasabb hőmérséklet mind az elektronikus, mind a mechanikus eszközök élettartamát megrövidíti. Egy teljesen populált rackszekrény összfogyasztása akár a 20 kilowattot is elérheti, ami jelentős energiaköltséget és hőfejlődést jelent. Egy szerver fogyasztása természetesen nagyban függ a konfigurációtól és a futtatott feladattól, ugyanakkor általános szabályként elmondható, hogy a legfőbb tényezők a processzorok, a memória, a ventilátorok, valamint a tápellátás hatékonysága.
Amint azzal a HWSW olvasóinak többsége bizonyára tisztában van, a processzorgyártók manapság számos technikát bevetnek annak érdekében, hogy minél energiahatékonyabb chipeket állítsanak elő. A mikroarchitekturális fejlesztéseken és a fejlett gyártástechnológián túl ebben a konzervatívabb órajeleken futó sokmagos felépítés az egyik eszköz, míg a pazarlás elkerülésének érdekében a hordozható gépekben megismert dinamikus órajelszabályozást vezették be: mikor egy processzormag nincs teljes terhelés alatt, akkor tápfeszültségét és órajelét egy előre a kalibrált táblázat alapján lépcsőzetesen csökkenti (demand based switching). Ezzel párhuzamosan a ventilátorok is visszafoghatóak.
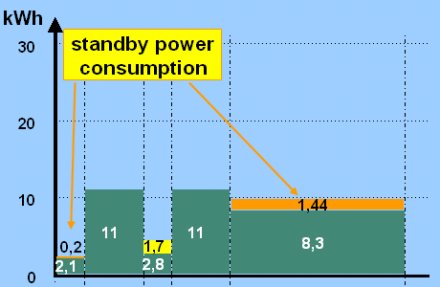
Bár szervereket senki nem azért üzemeltet, hogy üresjáratban tartsa őket, a kapacitásigény időben egyenletlen eloszlásából kifolyólag a csúcsidőszakon kívüli órákban számos kiszolgáló rendkívül alacsony kihasználtsággal működik, vagyis a feladatok elvégzése konszolidálható lenne kevesebb gépre is. A terheletlen gép alig fogyaszt, gondolhatnánk, ez azonban sajnos nem igaz: a tápegységek és az egész tápellátási rendszer egyik sajátossága, hogy hatékonysága egy bizonyos teljesítménytartományban optimális, az alatt vagy felett drasztikusan romlik.
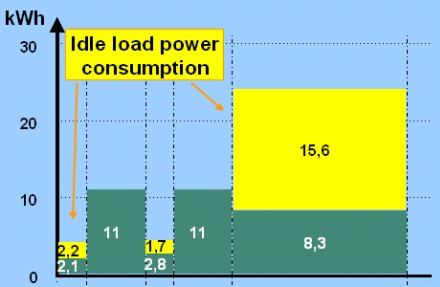
Ez azt jelenti, hogy az ideális esetben 80 százalékos hatékonyság felett dolgozó táp terheletlen állapotban is rengeteg áramot vesz fel, mivel a gép által igényelt energia csökkenésével romlik a tápellátás hatékonysága, így a valódi fogyasztás messze nem arányosan, hanem a lineárisnál lényegesen rosszabbul csökken. Egy-egy üresen üzemelő, tehát értéket nem termelő gép 2-300 wattot is emészthet folyamatosan, ami egy nagyobb gépparknál jelentős pazarlás.
Erre az egyetlen ésszerű megoldás, ami talán ellenkezik sokak szerverekkel kapcsolatos elképzelésével, ha ezekben az időszakokban kikapcsoljuk a gépet. Az FSC az Adaptive Services Control Center (ASCC) részeként fejlesztett ki olyan megoldást, a Power Savert, amely képes előre meghatározott időben vagy esemény hatására standby üzemmódba küldeni a szervereket, vagy onnan feléleszteni azokat, amivel az energiafelvétel ugyan nem szűnik meg, de ekkor a tápegységek mindössze 20-30 wattot fogyasztanak. Az ASCC PS segítségével már egy közepes vállalat is évi több százezer forint áramköltséget spórolhat meg, miközben javítja szervereinek várható élettartamát, egy nagyobb adatközpont megtakarítása pedig tízmillió forintokra is rúghat.
Etc.: PRIMERGY gépek HP Systems Insight Manager környezetbe
A nagyobb szállítók egy közkedvelt eszköze ügyfeleik magukhoz láncolásához az azokhoz adott menedzsmentszoftver, amelyek természetesen szinte kizárólag adott szállító eszközeit kezelik, így egy megszerzett ügyfélhez a riválisoknak nehezebb bekerülni, mivel annak a gépei nem illeszthetőek be egyszerűen az alkalmazott felügyeleti rendszerbe.
Mivel a HP a világon és Európában is a legnagyobb szállítója az x86-os gépeknek, rengeteg ügyfelet dominálva, ezért riválisai számára fontos, hogy ezt a belépési korlátot elhárítsák. Az FSC állítja, hogy a HP Systems Insight Manager "alá" a ServerView képes integrálódni, vagyis egy HP-dominált környezetbe az eddigieknél praktikusabban illeszthetőek az FSC PRIMERGY szerverei is.
Véleménye van?
kipróbáltuk