Kiteregette csőben lévő fejlesztéseit az Intel
Korábbi gyakorlatához képest rendhagyó rendezvényen részletezte következő néhány évre tervezett fejlesztésit az Intel. A chipgyártó PR stratégiai váltását az elmúlt hónapokban leszerződtetett, egykoron AMD-s szakemberek inspirálhatták, Raja Kodurival és Jim Kellerrel az élvonalban. Ugyancsak a nyitottabb kommunikáció felé billenthette a mérleget az Inteltől szokatlan csúszássorozat, illetve az e miatti bizonytalanság. A 10 nanométeres gyártástechnológia, illetve az arra épülő termékek ugyanis jelen állás szerint nagyjából 2-3 évvel az eredetileg tervezett után kerülhetnek piacra, valamikor jövő év második felében.
CPU-s fejlesztések
A legnagyobb érdeklődés továbbra is az Intel gyökereinek számító CPU-s fejlesztéseket övezi. A 2015-ben megjelent Skylake óta ugyanis csupán kisebb ráncfelvarrásokkal igyekezett szinten tartani termékpalettáját a chipgyártó, amely tehát régóta adós egy új, élvonalbeli mikroarchitektúrával. Az ígéret szerint pár év késéssel jövőre végre megérkezhet a hőn áhított utód, amely Sunny Cove kódnéven került fel a vállalat útitervére. A közzétett információk alapján az Ice Lake lapkadizájn alapját (is) adó fejlesztés az egyszálas végrehajtás tempójára, a skálázhatóságra, illetve új utasításokra fókuszál.
Ezt várhatóan valamikor 2020-ban követheti a Willow Cove mikroarchitektúra, amelynél a gyorsítótárakhoz, a tranzisztorkészlethez, illetve a biztonsági funkciókhoz nyúl hozzá komolyabban az Intel. Utóbbit nem részletezte a vállalat, ám az elmúlt szűk egy év fejleményei alapján vélhetően az egyre több tagot számláló Spectre sebezhetőségeket igyekszik majd foltozni a fejlesztés. A harmadik publikált, csőben lévő fejlesztés a Golden Cove, amely várhatóan 2021 környékén kerül majd piacra. Ennél a Sunny Cove-hoz hasonlóan ismét fókuszba kerül az egyszálas végrehajtás teljesítménye. Emellett dedikált, fixfunkciós egységet (és/vagy utasításkészletet) kaphatnak a gépi tanulásos kódok, így gyorsítva azok végrehajtását. Hasonló fejlesztés kerülhet be a networkinggel kapcsolatos műveletek gyorsításához. Ez utóbbi nem lenne alapvetően új, a Xeon D modellek egy részében található QuickAssist Technology ugyancsak a hálózatos végrehajtást gyorsítja olyan jellemző művelettípusoknál, mint a titkosítás és a tömörítés.
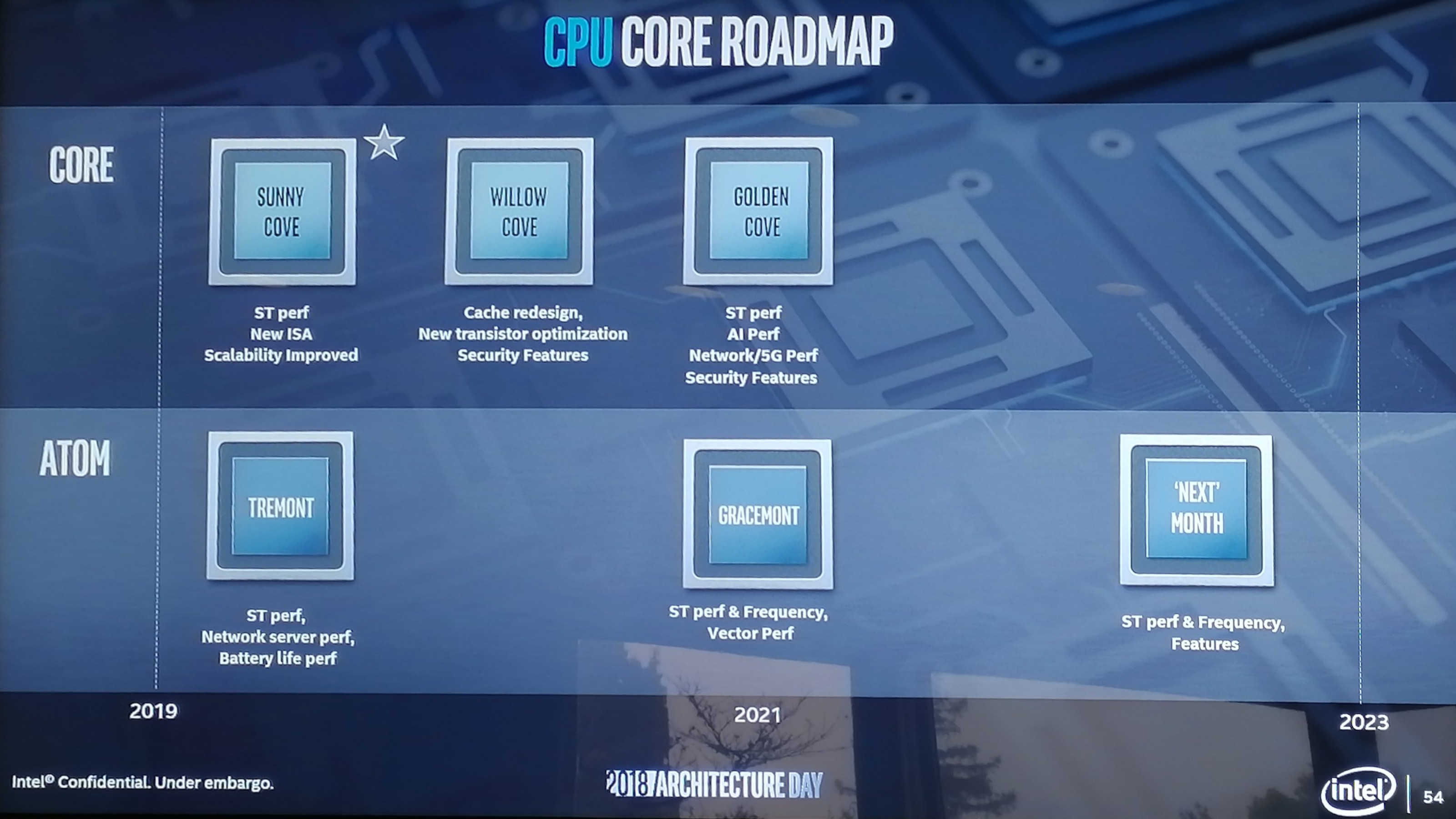
Azt egyelőre nem tudni, hogy a Golden Cove milyen gyártástechnológiával érkezik, de a 2021 környéki piacra kerülés alapján nem zárható ki a 7 nanométeres csíkszélesség sem. Az erre irányuló kérdésékre válaszként csupán annyit közölt az Intel, hogy új fejlesztési iránya teljesen szakít a pár éve elföldelt tick–tock igen sikeres stratégiájával, az egyes mikroarchitektúrákat nem konkrét csíkszélességekhez igazítják.
A tick–tockkal a gyártó két lépcsőben innovált: előbb a meglévő mikroarchitektúrát költöztette kisebb csíkszélességre, majd a következő generációnál a gyártástechnológiát megtartva új mikroarchitektúrát fejlesztett. A megközelítés előnye volt, hogy a cég egyszerre csak egy lovat cserélt a szekér előtt, a processzorgyártás két nagy kockázatát, a mikroarchitektúra és a csíkszélesség cseréjét szétválasztva. A fejlettebb gyártástechnológia felfuttatása elegendő időt biztosított a tervezőcsapatok számára, hogy a csíkszélesség csökkentésével előálló, a gazdaságosan gyártható lapkaméretbe beleférő többlet tranzisztormennyiséget a következő mikroarchitektúrában átgondoltan, optimálisan költsék el.
Üzemeltetői meetup és Szabó Balázs standupja a SYSADMINDAY-en! MOST PÉNTEKEN 4 klassz előadással, értékes képzéskuponokkal vár az idei Sysadminday!
Az új, a gyártástechnológia szempontjából kötetlenebb megközelítés bár lehetővé teszi, hogy egy akár több éves csúszás miatt ne ragadjanak a csőben kritikus fontosságú fejlesztések, a rugalmasságért cserébe elvész a mikroarchitektúra-gyártástechnológia optimalizáció egy része. Az óvatosabb hozzáállás egyik oka tehát, hogy az élvonalbeli gyártástechnológiai fejlesztések egyre több és komolyabb kockázatot hordoznak, a 10 nanométernél elkövetett ballépésekből tanulva pedig a jövőben lényegesen óvatosabb lesz az Intel.
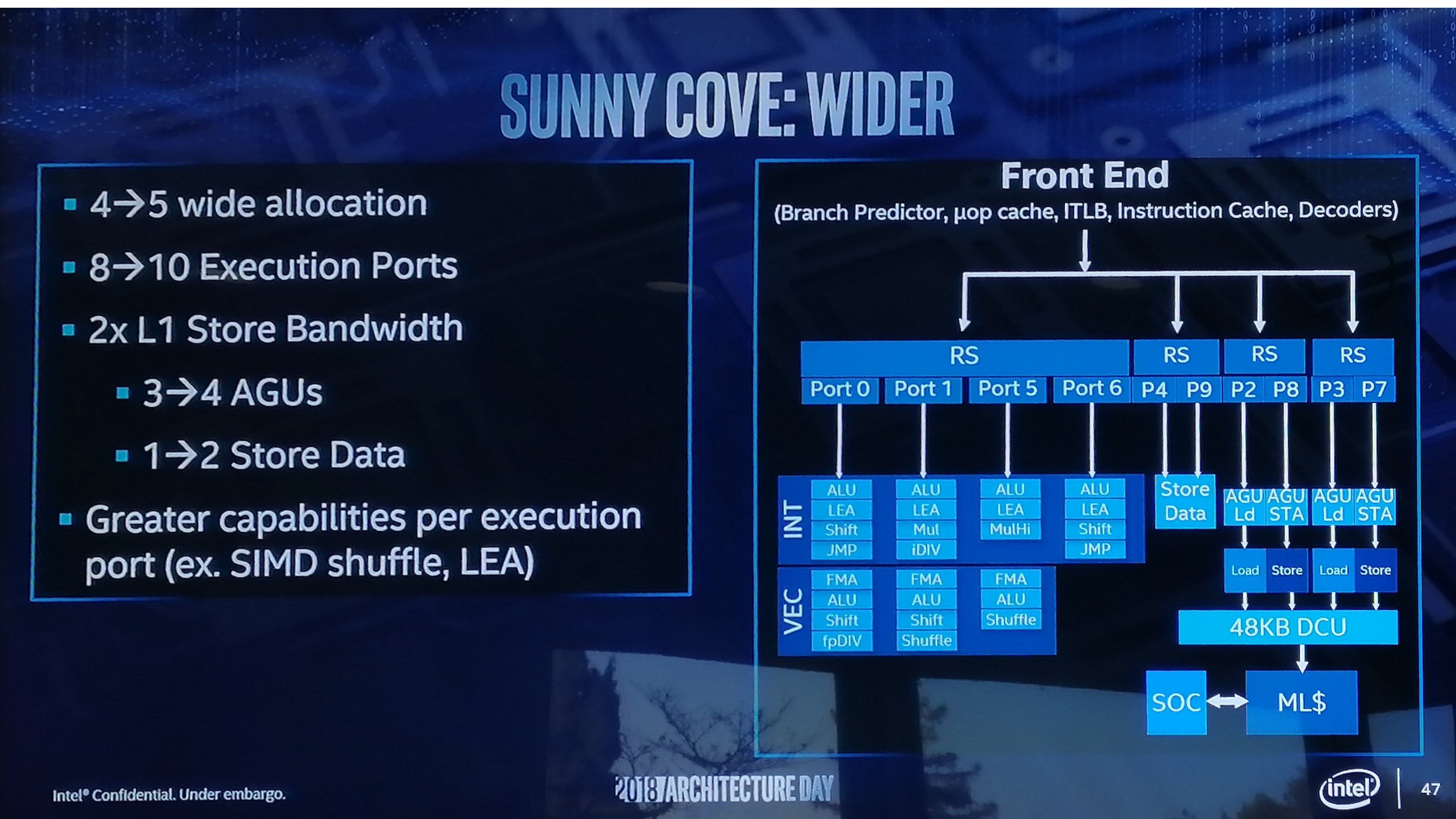
A chipgyártó a jövő évre datált, Sunny Cove kódnevű mikroarchitektúrájáról néhány részletet is megosztott. Ezek alapján 50 százalékkal, 48 kilobájtra nő az L1D gyorsítótár mérete. Az L2 cache kapacitását a célszegmenstől teszi függővé az Intel, így a PC-s Core processzorok esetében várhatóan marad a nem túl nagy, 256 kilobájtos méret, a Xeonoknál pedig 1 megabájt lehet a kapacitás. Ugyancsak nő a ROB, a másodszintű TLB, illetve az uOp cache kapacitása, ám ezek pontos méretét egyelőre nem közölte az Intel. Ezzel párhuzamosan számos ponton "kiszélesítette" új mikroarchitektúráját a cég. A Sunny Cove már 5 utasítás széles, mely 25 százalékos előrelépés a Skylake-hez képest. Ezzel együtt két további végrehajtóporttal, összesen tízre bővül a repertoár, némileg átrendezve az erőforrásokat. Erre részben a Skylake egyes szűk keresztmetszeteinek átvágásához volt szükség, végeredményben kiegyensúlyozottabb lehet a végrehajtás. Arról egyelőre csak találgatni lehet, hogy mindez a gyakorlatban mennyit hoz majd a konyhára.
Szintén említésre érdemes, hogy a Sunny Cove mikroarchitektúra alapértelmezetten támogatja az AVX-512 utasításkészletet, amely magában foglalja a különféle aritmetikai műveletek gyorsítására hivatott IFMA-t (Integer Fused Multiply Add) is. A Vector-AES-nek hála több AES művelet futtatható párhuzamosan, amely mellé sorakozik fel az ugyancsak kriptográfiai végrehajtás gyorsításához beépített Vector Carryless Multiply, Galois Field, illetve SHA és SHA-NI. Végül, de nem utolsó sorban 57 bitesre szélesedik ki a lineáris, 52 bitesre pedig a fizikai címtér, melynek hála egy Sunny Cove-alapú (szerver)processzor akár 4 terabájt memóriát is kezelhet. Utóbbi legkorábban 2020 környékén jöhet el, ekkor kerülhet piacra Xeon márkanéven az Ice Lake-SP fejlesztés.
Az Intel big.LITTLE-je
A prezentáció szerint az Intel nem engedi el az okostelefonos piacon csúfosan megbukott Atom termékvonal kezét, a következő években újabb tagokkal bővül a család. Várhatóan jövőre érkezik a Tremont kódnevű mikroarchitektúra, amely az ígéret szerint az egyszálas és a hálózati kiszolgálós teljesítményre, illetve a hatékonyságra fókuszál majd. Az ezt leváltó Gracemont két évvel később, 2021 magasságában kerülhet piacra, az Intel szerint ez elsősorban egyszálas teljesítményben, órajelben, illetve vektoros műveletek végrehajtási tempójában múlhatja felül elődjét.
Az Atomra az elmúlt pár évben látottaknál nagyobb szerep hárulhat, az Intel ugyanis a korábbi pletykáknak megfelelően összeházasítaná a teljesítményre kihegyezett Core, illetve a hatékonyságra fókuszáló Atom magokat. Az egyelőre csak Hybrid x86 néven futó koncepció nagyon hasonlít az ARM big.LITTLE-re. Az Intel ilyen irányú erőfeszítései azt támasztják alá, hogy a vállalat is belefutott a mikroarchitektúra-skálázás problémájába, amibe kivétel nélkül minden más processzorgyártó is: a sebességre kihegyezett, erős magok sokat is fogyasztanak, ami lefelé csak korlátozottan skálázódik (alacsonyabb órajelen is megmarad a fogyasztás egy része). A megoldás itt is az, mint amit a többi gyártó használ, az erős magok mellé gyenge, de alacsony fogyasztású egységek kerülnek be Atom magok formájában.
Az Intel által megmutatott fejlesztés egyetlen Sunny Cove, illetve négy, vélhetően Tremont (Atom) magot tartalmaz egy 10 nanométeres lapkába integrálva. Előbbi mag egy 512 kilobájtos L2 cache-sel, utóbbiak pedig egy 1,5 megabájtos megosztott L2-vel rendelkeznek, amelyeket egyetlen nagyobb, 4 megabájtos L3 köt össze. A processzormagok mellé egy 64 EU-s (Execution Unit) Gen11 GPU is társul, a memóriavezérlő pedig 64 bites (4x16 bit). Az apró, betokozva mindössze 12x12 milliméteres chip mindössze 2 milliwattot fogyaszt üresjáratban, maximális terhelés mellett pedig 7 wattig kúszhat fel az érték, amelyre így akár passzív hűtésű notebookok is építhetőek.

A fejlesztés további érdekessége, hogy elsőként alkalmazza a gyártó ugyancsak vadiúj, Foveros névre keresztelt 3D tokozási eljárását. Az iparági körökben jól ismert technológia lényege, hogy a fix interpózert alkalmazó, úgynevezett 2.5D-s megoldásokkal ellentétben egymásra építik a lapkákat, hasonlóan, mint a rétegzett, HBM memóriáknál. Ennek előnye, hogy ilyen módon lényegesen kisebb lehet a komplett processzor tokozása, amely területérzékeny termékek esetében fontos szempont. A 3D tokozásnak hála a funkcionalitás alapján külön lapkákra felosztott, heterogén koncepció előnyéről sem kell lemondani.
A konkurens AMD által is alkalmazott irány lényege, hogy komponensektől függően más-más gyártástechnológiával készülnek a lapkák, az így elkészült különálló chipeket pedig a processzor tokozásán belül "drótozzák" össze. A megközelítéssel végeredményben csökkenthetőek az előállítási költségek, nem utolsó sorban pedig felgyorsítható az egyes újabb gyártástechnológiák bevetése, nem kell megvárni, hogy a kihozatal elérje a nagyobb lapkák gazdaságos előállításához szükséges szintet.
Ily módon a jövőben megjelenő újabb (és még drágább) gyártástechnológiákat elsőként csak az ilyen szempontból kritikus egységek (pl. CPU magok, cache, GPU) előállítására lehet felhasználni, a csíkszélességre sokkal kevésbé érzékeny áramkörök maradhatnak a már jól bejáratott, olcsóbban üzemeltethető technológiákon, amelyeket nem utolsó sorban tranzisztorszinten lehet hozzáigazítani a különféle részegységekhez (IO, FPGA, RF, stb.).
A Hybrid x86-os fejlesztésnél a CPU magokat, a GPU-t, illettve a kisebb vezérlőket tartalmazó 10 nanométeres lapkát egy 22 nanométeres PCH-ra (chipset) ültette rá az Intel a szóban forgó 3D tokozási eljárása segítségével. A chipgyártó állítja, a Foveros rendkívül sűrű vezetékezést (828 darab/mm2) tesz lehetővé alacsony ellenállás, így pedig energiafelhasználás mellett (0,15 pJ/bit).
Sínen vannak a GPU-s fejlesztések
A CPU-k mellett a GPU-k kapták a másik főszerepet az Intel rendezvényén. A vállalat ezen a téren sem mutatott sokat az elmúlt években, a Skylake óta gyakorlatilag grafikában sem történt említésre érdemes előrelépés. A soron következő, Gen11 kódnevű integrált GPU ezen végre változtathat. Az Ice Lake-kel megjelenő fejlesztés lehet az Intel első, 1 TFLOPS-ra képes mainstream mobil egysége, hála a GT2-es konfigurációba tervezett 64 EU-nak. Utóbbi önmagában jelentős (166 százalékos) ugrás, a jelenleg piacon lévő GT2-es GPU-k (pl. UHD Graphics 630) ugyanis mindössze 24 EU-t tartalmaznak. Ehhez jönnek hozzá a különféle mikroarchitektúrális fejlesztések, a gyorsabb memória-hozzáférés, illetve a nagyobb, 3 megabájtos dedikált L3 szelet.

Említésre érdemes még, hogy bár utolsóként, de az Intel is bevezeti tile based renderinget. Az eljárás lényege szerint a rendszer igyekszik pixelszinten szűrni megjelenített képen nem látható elemeket (pl. háromszögeket), ezzel tehermentesítve a GPU-t a felesleges számításoktól, amely így erőforrásaival a hasznos kalkulációkra fókuszálhat. A Coarse Pixel Shading az Nvidia Variable Pixel Shadingjéhez hasonlóan csökkenti az árnyalásos számításokhoz szükséges erőforrásokat a mindenkor szükséges részletesség fényében. Továbbá javul a memóriatömörítés hatékonysága is, amely önmagában 4 százalékkal gyorsíthatja a megjelenítést.
A GPU mikroarchitektúrája mellett fejlődik a media blokk is, amely így jobb HEVC kódolást/dekódolást ígér, már akár 8K felbontás mellett. A kijelzőmotor sem maradt érintetlenül, amely végre megkapja az AMD által csak Freesyncként marketingelt VESA Adaptive Sync technológia támogatását. Ennek hála szinkronban tartható a kijelző képfrissítési frekvenciája a videokártya felől érkező elkészült képkockákkal, így küszöbölve ki az olyan gyakori megjelenítési hibákat, mint a képtörés (tearing).
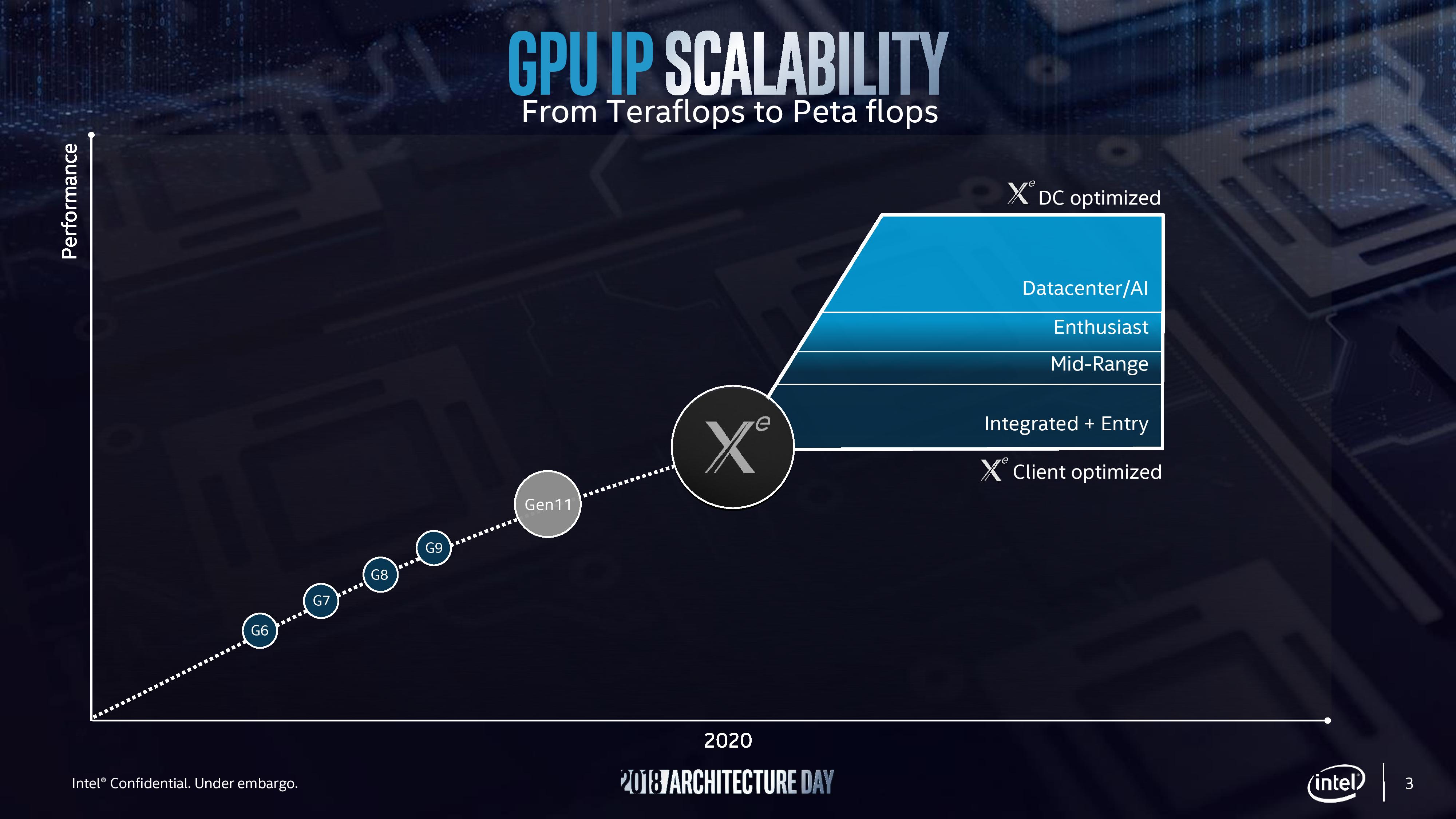
Végül, de nem utolsó sorban a diszkrét GPU-s fejlesztésről is szót ejtett az Intel. Az XE (stilizáltan Xe) márkanév alá érkező videokártyák várhatóan már a Gen12-es mikroarchitektúrára épülnek, amellyel a tervek szerint a belépőszintű integrált megoldásoktól kezdve a nagy adatközpontokig, a komplett piacot megpróbálja majd lefedni a chipgyártó.