Gépi tanulásos fejlesztőcsapatot állít rá a Twitter az álhírszűrésre
A Twitter gépi tanulással foglalkozó Cortex részlegén belül újabb kutatócsoport alakul a Fabula AI felvásárlásával. A neves kutatók a szabadalmaztatott Geometric Deep Learning gráfalapú gépi tanulási tehcnológiájukat szeretnék bevetni élesben a közösségi hálózaton, hogy kiszűrjék és kategorizálják a Twitteren terjedő álhíreket.
Még mindig nem elég felkészültek a közösségi média oldalak az álhírek kiszűrésével kapcsolatban, ezért az Európai Bizottság határozottabb intézkedéseket sürgetett. Ennek egyik eredménye a Twitter frissen bejelentett felvásárlása, melynek során az álhírek gépi tanulás alapú felismerésével foglalkozó Fabula AI-t kebelezte be. A londoni startup kifejezetten az álhírek mintázatának felismerésével foglalkozik, és hogy megkülönböztesse a félrevezető információkat a hiteles hírektől. A megoldásának középpontjában egyébként kevésbé a tartalomelemzés, hanem inkább a terjedés módjának és a terjesztőknek a viselkedésvizsgálata, interakcióinak elemzése áll - mivel a kutatók szerint a valódi és az álhírek terjedése egészen más mintázatot mutat.
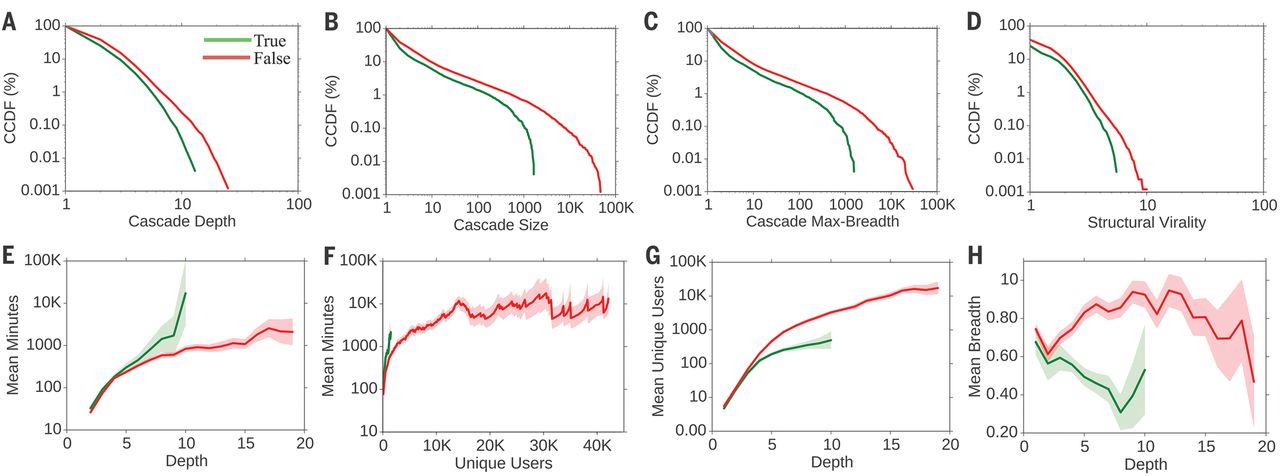
Részlet a Science 2018-as cikkéből, amely az álhírek és valódi hírek terjedési különbségét mutatja
Most pedig a Twitter a startup fejlesztőiből egy saját kutatócsoportot alapít a Cortex részlegén belül, ahol a gépi tanulás szakértői az eddigi munkájukat folytathatják, csak éppen mostantól kifejezetten a Twitter számára. A közösségi oldal ezzel valóban a gépi tanulás területének nagyágyúi közül szerzett meg néhányat, köztük például Michael Bronsteint, aki az új munkája mellett megtartja egyetemi pozícióját is az Imperial College-ban. A Twitternél főbb kutatási területek közé többek közt a természetes nyelvi feldolgozás, a megerősítő tanulás, a gépi tanulási etika és az ajánlórendszerek tartoznak majd.
Ollé, lesz SYSADMINDAY! Duna melletti szabadtéri helyszínen idén is megrendezzük a hazai Sysadmindayt, az IT-üzemeltetők világnapját. Standup, IT security meetup, szakmázás, barátok, még több sörcsap.
Azonban a legfontosabb a gráfalapú mélytanulásos technológia az említett területek közül, amelyet Federico Monti technológiai igazgató és Fabula AI-társalapító külön is hangsúlyozott. A tervek szerint a startup a saját, szabadalmaztatott gráfalapú megközelítését (Geometric Deep Learning) szeretné majd bevetni a Twitteren az álhírek szűrésére, és a szolgáltatásán keresztüli beszélgetések minőségének fejlesztésére. Azaz a fejlesztők a gyakorlatban is kipróbálhatják, mennyire működik a kifejezetten nagy közösségi hálókra tervezett, álhírfelismerő és kategorizáló megoldásuk.A felvásárlás részleteit egyik cég sem közölte, így a vételárat és azt sem, hogy a technológia elérhetővé válik-e más cégek számára a Twitteren kívül. A Fabula AI ugyanis eredetileg idén tervezte egy API kiadását platformok és kiadók számára. A TechCrunch forrásai szerint viszont a londoni startup végül úgy döntött, hogy "valódi és mélyebb hatást tud elérni" a Twitteren keresztül mint egy decentralizált, nyílt platformmal. Mostantól viszont a Twitteren múlik, hogy mit tesz a technológiával, a szóvivő elmondása szerint a "következő hónapokban" fog kiderülni, hogy a közösségi oldal hogyan tudja majd integrálni a Fabula AI csapatát és megoldását.