Ütős lett az első Pascal-alapú Tesla
Lerántotta a leplet első Pascal mikroarchitektúrát használó termékéről az Nvidia. A Tesla P100 számos egyedi megoldást tartalmaz, a kártya formátuma mellett az adatbusz is új, a gyorsító elsőként alkalmazza az NVLink csatolót. A vállalat mindezt egy saját, számítási teljesítményre kihegyezett szerverrel fejelte meg, az akár 170 TFLOS tempóra képes DGX-1 összesen nyolc kártyát tartalmaz
Végre részleteiben is beszélt első Pascal kódnevű lapkájáról az Nvidia. A GPU Technology Forumon nem csak a legújabb grafikus processzort taglalták az előadók, a vállalat a DGX-1 típusjelzésű HPC szerveréről is lerántotta a leplet. A szuperszámítógépként aposztrofált 3U magasságú rendszerbe nyolc darab egyedi kialakítású csúcskártyát préseltek a mérnökök, melyek már a saját fejlesztésű NVLink csatolón keresztül kommunikálnak egymással.
A bejelentetések alapját az Nvidia új grafikus mikroarchitektúrája, a Pascal adja, mely mélységében is átalakult az előző két generációhoz, a Keplerhez és a Maxwellhez viszonyítva. A legfontosabb módosítás, hogy a GPU alapvető szervező egységének számító SM-eket (streaming multiprocessor) kettéosztották, egy SM így két végrehajtóblokkból áll. Mindkét rész tartalmaz FP32-es CUDA magokat, utasítás puffert, két műveletindító egységet (dispatch unit), illetve egy warp ütemezőt. Utóbbi órajelenként két warp műveletet indíthat.
A másik lényeges változás, hogy a különböző egységek arányait az Nvidia alaposan újraegyensúlyozta. Kezdjük a CUDA-magokkal. Ezek száma megfeleződött a Maxwellhez képest, egyetlen SM 64 darab FP32-es CUDA magot és négy textúrázót tartalmaz. Emellett az SM-ek 32 darab nagy pontosságú FP64-es CUDA magot is felvonultatnak, ami a Maxwell nyolcszorosa, ez a mérnöki-tudományos és szuperszámítógépes feladatok alatt lényegesen magasabb teljesítményt hozhat. Fontos tulajdonság, hogy az FP32-es egységek egy időben akár két FP16-os műveletet is képesek végrehajtani. Ezzel az egyszeres pontosságú tempóhoz mérten duplázható a sebesség, már amennyiben elég a félpontosság.
Az újraegyensúlyozás részeként változott a CUDA-magok és a regiszterek aránya is. A regiszterek száma SM-enként nem változott, de a Pascal jóval több, de kisebb SM-ből épül fel. Ennek folyományaként a regiszterek összmérete jelentősen nőtt, a GM200-hoz képest több mint duplájára, pontosan 14336 kilobájtra, ami növeli a hatékonyságot, a végrehajtószálak több erőforrásból gazdálkodhatnak. Emellett az L2 gyorsítótár is gyarapodott, a GM200-hoz képest 33 százalékkal, 4 megabájtra hízott.
Ezeken felül további általános optimalizációkkal javítottak a Pascal képességein. Egyszerűsítették az adatutak elrendezését, amivel nem csak tranzisztorokat, de energiát is megtakarítottak a mérnökök. Emellett javítottak az ütemezésen, illetve a load/store műveletek átfedésén is, így tovább nőtt a lebegőpontos végrehajtás hatékonysága.
A GP100 dizájnja összesen 60 SM-et tartalmaz, amiből az Nvidia (egyelőre) 56 darabot engedélyezett, ez összesen 3584 aktív futószalagot jelent. Erre valószínűleg a kedvezőbb kihozatal miatt volt szükség, ugyanis a grafikus processzor az elődökhöz hasonlóan igen nagy. A lapka a korábbi csúcs-GPU-k méretét mutatja, 610 mm²-es területével alig nagyobb mint a GM200, mely 601 mm²-en fekszik el. Lényeges különbség, hogy a GP100 már a TSMC 16 nanométeres FinFET+ gyártástechnológiájával készül, ami jelentősen magasabb tranzisztorsűrűséget, illetve alacsonyabb disszipációt (vagy magasabb órajelet) kínál. Előbbinek köszönhetően közel azonos terültre nagyjából 90 százalékkal több tranzisztort helyezhettek a mérnökök, míg a GM200-ban 8 milliárd fért, addig a GP100-ban már 15,3 milliárd tranzisztort zsúfolhattak a tervezők. Tudomásunk szerint ez a legnagyobb, tömegtermelésben gyártott processzor valaha - ekkora fába vágta tehát fejszéjét az Nvidia.
A GP100 első szerepét a Tesla P100-on kapta, ahol az Nvidia legújabb GPU-jára meglehetősen magas órajeleket szabtak. Az alapfrekvencia 1328 MHz, ami a GPU-k világában új rekordnak számít, ráadásul ehhez még turbó (boost) órajel is társul, melynek értéke 1480 MHz. Mindez a 3584 végrehajtó tükrében kimagasló, ez alapján a később érkező, kisebb GPU-k órajele akár a 2 GHz-et is megközelítheti majd. A magas órajeleknek (is) köszönhetően félpontosság mellett 21,2, egyszeres pontosság esetében 10,6, duplapontosság esetében pedig 5,3 TFLOPS lehet a maximális számítási teljesítmény.
Éles bevetésen a HBM2
Az Nvidia legújabb grafikus processzora memória terén is újít, a GP100 elsőként alkalmazza a rétegzett HBM2 memóriát, összesen 16 gigabájt kapacitással. A beszállító személyére egyelőre nem derült fény, az SK Hynix mellett a Samsung is lehet a partner. A chipek darabonként 4 gigabájtosak, órajelük pedig 700 MHz. A négy lapka egy összesen 4096 bites buszhoz kapcsolódik, amivel az elméleti maximális memória-sávszélesség 720 GB/s, mely több mint duplája a GDDR5-ös Tesla M40 értékének. Fejlesztői szempontból legalább ilyen fontos lépés egységes (egységesen címezhető) virtuális memória hardveres támogatása. A GP100 ehhez 49 bites virtuális címzést vezet be, mellyel egyszerre fedhető le a modern CPU-k és GPU-k 48 bites címtere, a rendszerben lévő egyes processzorok memóriájának fizikai mérete ezzel már nem lehet limitáló tényező.
Az Nvidia közleményében az adatbiztonság kérdésére is kitért, a vállalat szerint a HBM2 ebből a szempontból is jobb mint a korábbi megoldások, hisz a chipek natívan támogatják a bithibák javítására hivatott ECC-t. Ehhez korábban a rendelkezésre álló kapacitás és sávszélesség egy részét fel kellett áldozni, például a Tesla K40 esetében 750 megabájtot foglaltak az ECC bitek, így a 12 gigabájt memóriábal csak 11,25-öt lehetett szabadon felhasználni. A hibajavítást a memória mellett természetesen az L1 és L2 chache-ek, illetve a regiszterek is támogatják.
A memóriákhoz kapcsolódó érdekesség, hogy a GPU és a HBM2-es lapkák a TSMC CoWoS (Chip-On-Wafer-On-Substrate) technológiájával kerülnek egy közös átvezetőre (interposer), ami eltér az AMD tavaly bemutatott saját megoldásától. A konkurens AMD Fiji kódnevű GPU-jánál a grafikus processzort gyártó TSMC mellett az átvezető réteget készítő UMC, illetve a HBM chipeket szállító SK Hynix közreműködésére is szükség volt, az összeállítás végső fázisát pedig egy negyedik cég, az ASE végezte. Az Nvidia GP100-as chipjénél a folyamatok már házon belül, a TSMC üzemeiben történhetnek.
Nyerd meg az 5 darab, 1000 eurós Craft konferenciajegy egyikét! A kétnapos, nemzetközi fejlesztői konferencia apropójából a HWSW kraftie nyereményjátékot indít.
A Tesla P100 a Kepler-alapú, de két GPU-s Tesla K80-éval azonos, 300 wattos TDP keretet kapott, ami viszont a közvetlen előd Tesla M40 értékénél 50 wattal több. A kártya kialakítása teljesen egyedi, az Nvidia háziszabványára épül. Processzor tokozása a 90-es évek slotos megoldásaira hajaz, a NYÁK a GPU-t, a memóriát, illetve a tápellátáshoz szükséges főbb komponenseket egyaránt tartalmazza. A Tesla P100 egyedi szabványú verziója úgynevezett mezzanine csatlakozót használ, a hozzá passzoló foglalatot pedig emiatt Mezznek keresztelte az Nvidia. Bár a vállalat erről egyelőre nem árult el konkrétumokat, később szabványos PCI Express formában is felbukkan majd a GP100 grafikus processzor.
Az NVLink busz is megérkezett
De nem csak a foglalat egyedi, ugyanis a Tesla P100 elsőként alkalmazza élesben az Nvidia saját fejlesztésű NVLink buszát, mely a PCI Express skálázódási problémájára jelent megoldást. A szabványos PCIe a GPU-k összekötésére, illetve a CPU-GPU szorosabb együttműködését feltételező GPGPU-feladatokhoz kevés. A korlátokra már régóta vannak megoldások, az AMD HyperTransport, vagy az Intel Quick Path Interconnect (QPI) hasonló problémákra adott válaszok, amelyek rendkívül gyors és alacsony késleltetésű pont-pont kommunikációt tesznek lehetővé.
Az NVLink (a fent említett HyperTransporthoz és QPI-hez hasonlóan) közvetlenül a processzorok között teremt kapcsolatot, az interfészben nincsenek közvetítőlapkák és elosztók. Ennek megfelelően egy blokk két GPU-t képes összekötni, több blokkal pedig több GPU összeköttetése is megvalósítható, a chipek ilyenkor NUMA architektúrában hálózatba is rendezhetőek. Ezzel egy GPU a rendszerben lévő másik GPU (vagy CPU) memóriájához is hozzáférhet, abban végrehajthat (akár atomi) műveleteket.
NVLink az NVHS (NVidia High-Speed Signaling) rendszerre alapoz, mely egy differenciált vezetékpáron keresztül 20 gigabites átvitelt tesz lehetővé, vagyis az átvitel hallatlanul magas, 20 gigabtranszfer másodpercenkénti tempón ketyeg számításaink szerint. Egyetlen blokk 8+8 (egy egy irányú) sávot tartalmaz, ez adja ki az aggregált 40 gigabájtos sávszélességet két irányba. A blokkok kombinálhatóak is, amivel az elméleti sávszélesség tovább skálázható.
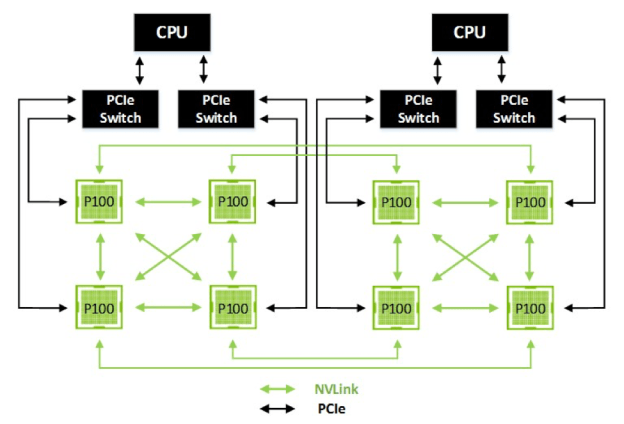
A Tesla P100 négy linket tartalmaz, melyek együttesen 160 GB/s átviteli sebességre képesek. Az Nvidia egy két CPU-val és nyolc GPU-val szerelt rendszert hozott fel példaként, melyek között (részben) az NVLink biztosította az adat összeköttetést. Beépített NVLink blokk hiányában a processzorokhoz jelenleg PCIe kapcsolókon keresztül csatlakozhatnak a GPU-k, ugyanakkor az Nvidia az OpenPOWER konzorcium tagjaként már korábban elérhetővé tette a partnereinek a technológiát, így egyes IBM Power CPU-k beépítve tartalmazzák az NVLink blokkot, az ilyen processzorokra épülő rendszerekből teljesen elhagyható lesz a PCI Express.
Egy saját HPC szerver is született
A sok újdonság szemléltetését az Nvidia saját szakembereire bízta, akik ehhez egy komplett rendszer raktak össze. A DGX-1 3U magas, melybe az Intel Haswell-E Xeonjai kerültek, az E5-2696 v3 CPU-kból két darab került a házba 512 gigabájt DDR4-2133 memóriával társítva. A háttértár szerepét négy 1,92 terabájtos SSD látja el RAID 0-ban, a hálózati kapcsolatokért pedig két 10 gigabites Ethernet vezérlő felel.
Mindezek mellé összesen nyolc darab Tesla P100 gyorsítót sikerült beépíteni, az apró kártyák két sorban ülnek a foglalatokban. Ezzel félpontosságú műveleteknél közel 170, egyszeres pontosság esetében pedig 80 TFLOPS feletti tempó érhető el az összesen 28672 CUDA-egységet felvonultató rendszerrel. Ez azt jelenti, hogy (elvben) öt ilyen dobozzal már fel lehet kerülni a legfrissebb top500-as szuperszámítógépes listára - persze ha a hardverből ennek a teljesítménynek nagy része elő is húzható.
Ahogy magát a Tesla GP100 kártyát, úgy a DGX-1 szervert is elsősorban mérnöki-tudományos feladatokhoz, például deep learninghez ajánlja az Nvidia, a vállalat az első (3U) dobozba zárt szuperszámítógépeként aposztrofálja komplett rendszerét. Az Nvidia DGX-1 ára 129 000 dollár, mely már előrendelhető, a szállítás pedig júniusban indul a kiemelt partnereknek. Később az OEM gyártók számára is elérhetővé válnak a P100-as kártyák, ugyanakkor a vállalat közleménye szerint erre jelen állás szerint egészen 2017 januárjáig kell majd várni, egészen eddig a cég saját hatáskörben értékesíti a P100-ra épülő megoldásokat.