Hálót szőtt a Skylake-alapú Xeonokba az Intel
Az évek óta használt gyűrűs megoldást egy hálós topólógia váltja. Komplexebb, de gyorsabb, és kevesebbet fogyaszt.
Ahogy közeleg az Intel vadiúj szerveres platformjának rajtja, úgy csepegteti a technikai részleteket a cég. Szerencsére ezekből most nincs hiány, ugyanis a Skylake-SP több ponton is eltér az elsősorban PC-s rendszerekbe szánt, lassan már két éve piacon lévő Skylake (és Kaby Lake) architektúrától. A fejlesztések elsősorban a cache alrendszert, illetve ehhez kapcsolódóan a magok és az egyes integrált vezérlők közti adatmozgás hatékonyságának növelését célozzák. Ennek jegyében nyúlt hozzá komolyabban a(z L2 és L3) gyorsítótárakhoz az Intel, a változás szele pedig a topológiát is megcsapta, az évek óta alkalmazott (kör)gyűrűs buszrendszert leváltotta a gyártó.
A Gyűrűk Urától a Pókemberig
Az Intel terminológiájában csak Ring Bus néven emlegetett megoldást bő 7 éve, a Nehalem-EX szerverprocesszorokkal debütált, a Sandy Bridge bemutatkozásával pedig a PC-s központi egységekbe is átkerült a fejlesztés, amit az azóta megjelent összes Intel Core processzor alkalmaz. A fejlesztés létjogosultságát elsősorban a sokmagos processzorok adták, az egyes magok közti hatékony kommunikáció kialakítása ugyanis korántsem triviális feladat. A probléma gyökerét a jellemzően nagy méretű, harmadszintű gyorsítótár jelenti, amit az elektronikai implementáció nehézségei miatt a tervezők kénytelenek több szeletre bontani. Egy ekkora memóriaterületet egyben kezelni ugyanis rendkívül komplex feladat lenne, ami miatt például a sebesség is jelentős csorbát szenvedne, ezzel párhuzamosan pedig a disszipáció is megnőne.
Ezért a mérnökök a 2010-ben bemutatott Nehalem-EX-nél az egyes cache-blokkokat egy-egy maghoz rendelték, az összeköttetést pedig egy széles belső, full-duplex körbusz (a Ring Bus) biztosította. A címzés teljesen "lapos", a késleltetésnövekedés pedig a szomszédos szeletből 1, a legtávolabbiból pedig legfeljebb 12 órajel. A körbusz két, szemben forgó körből áll, vagyis egy-egy állomás két irányból is fogadhat egyszerre adatokat, azonban egyszerre csak egyet tud kiolvasni, ezért a konfliktus feloldása és a sebesség megőrzése érdekében a mérnökök polaritással látták el az egyes irányokat és az állomásokat, hogy az állomás csak megfelelő polaritású körből fogadja az adatokat. Mivel a körök, vagyis az adatsávok órajelenként felváltják a polaritásukat, ezért egy adott időben egy állomásra csak az egyik sávról (kör) érkezhetnek adatok, elkerülve az esetleges konfliktust.
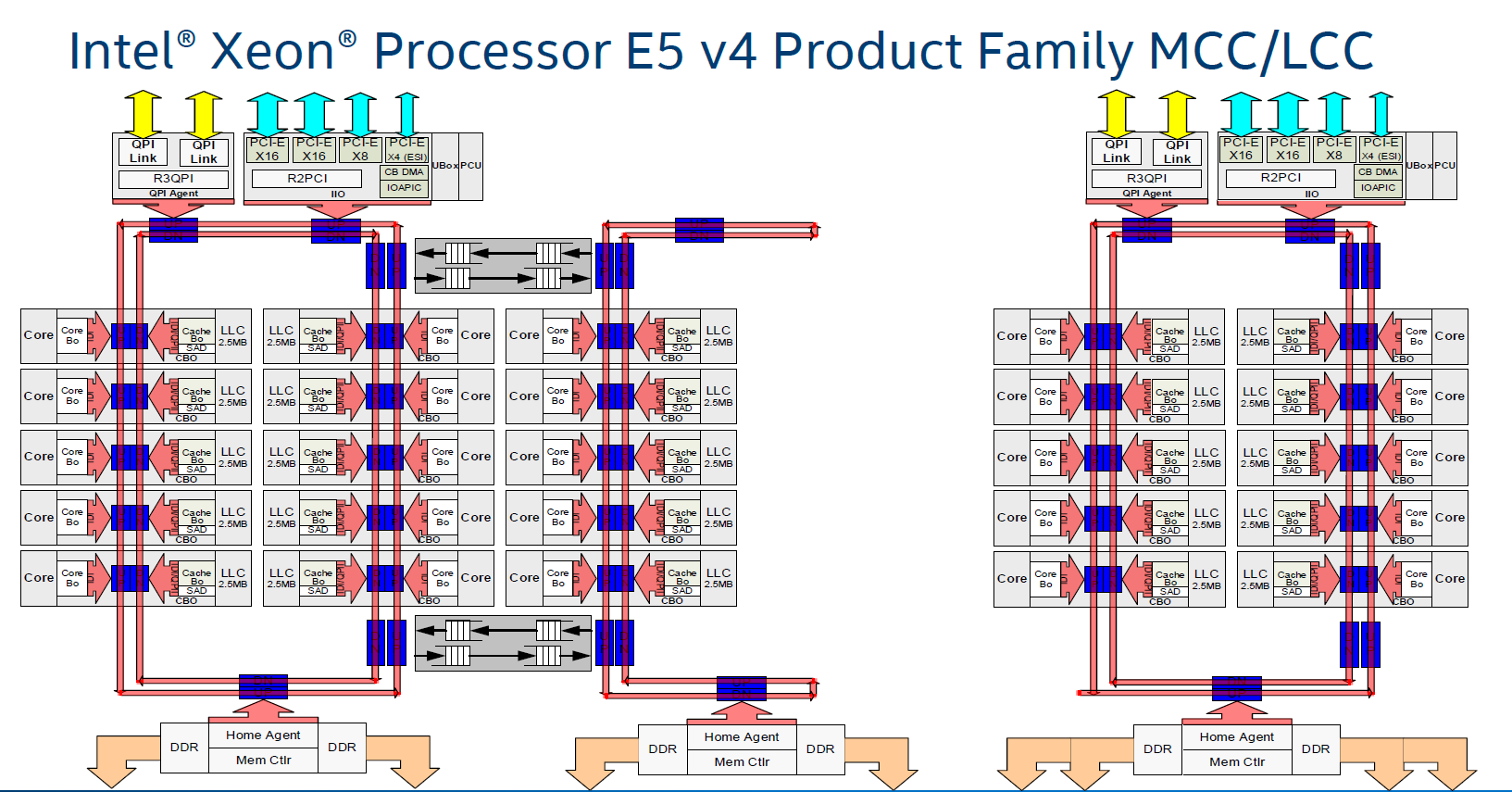
A Ring Bus 10-12 magig jó alternatívát jelent, azonban e fölött már két párhuzamosan futó körbuszt kell beépíteni, amivel a monolitikus lapkadizájn ellenére gyakorlatilag két különálló részre bomlik a processzor belső felépítésre. A két körbuszt egy pár, ugyancsak full-duplex, pufferelt kapcsoló köti össze, ami lassítja a két különálló körben található magok adatkommunikációját, a "határátlépésért" ugyanis 5 órajeles büntetés jár, így magszámtól függően bizonyos esetekben akár 20 órajel fölé is szaladhat a késleltetés - a megközelítés hasonló az AMD által alkalmazott Core Complex felépítéshez, amelyben két-két magcsoportra bontja a sokmagos chipeket. A magas késleltetés értelemszerűen negatívan befolyásolja a végrehajtás sebességét, miközben a hosszú adatút a fogyasztásra van rossz hatással, a belső buszrendszer disszipációja elfogyasztja a processzor fogyasztási büdzséjének egy részét, ami végül alacsonyabb turbó órajelet eredményez.
Nagy pénz, nagy szívás: útravaló csúcstámadó IT-soknak Az informatikai vezetősködés sokak álma, de az árnyoldalaival kevesen vannak tisztában.
20 mag felett a jelenség könnyen mérhető hatást gyakorol a rendszer teljesítményére, a Skylake-SP pedig már egészen 28 magig skálázódik. Az Intel ezért elérkezettnek látta az időt egy új buszrendszer bevezetéséhez. Ötletekért nem kellett a szomszédba menni, ugyanis a vállalat kínálatában már létezik 72 magos processzor is, a Xeon Phi "Knights Landing" ugyanis épp ennyi Silvermont egységet tartalmaz. A párosával, 36 csempébe rendezett magokat ebben az esetben már háló topológiával (mesh) kapcsolják össze.
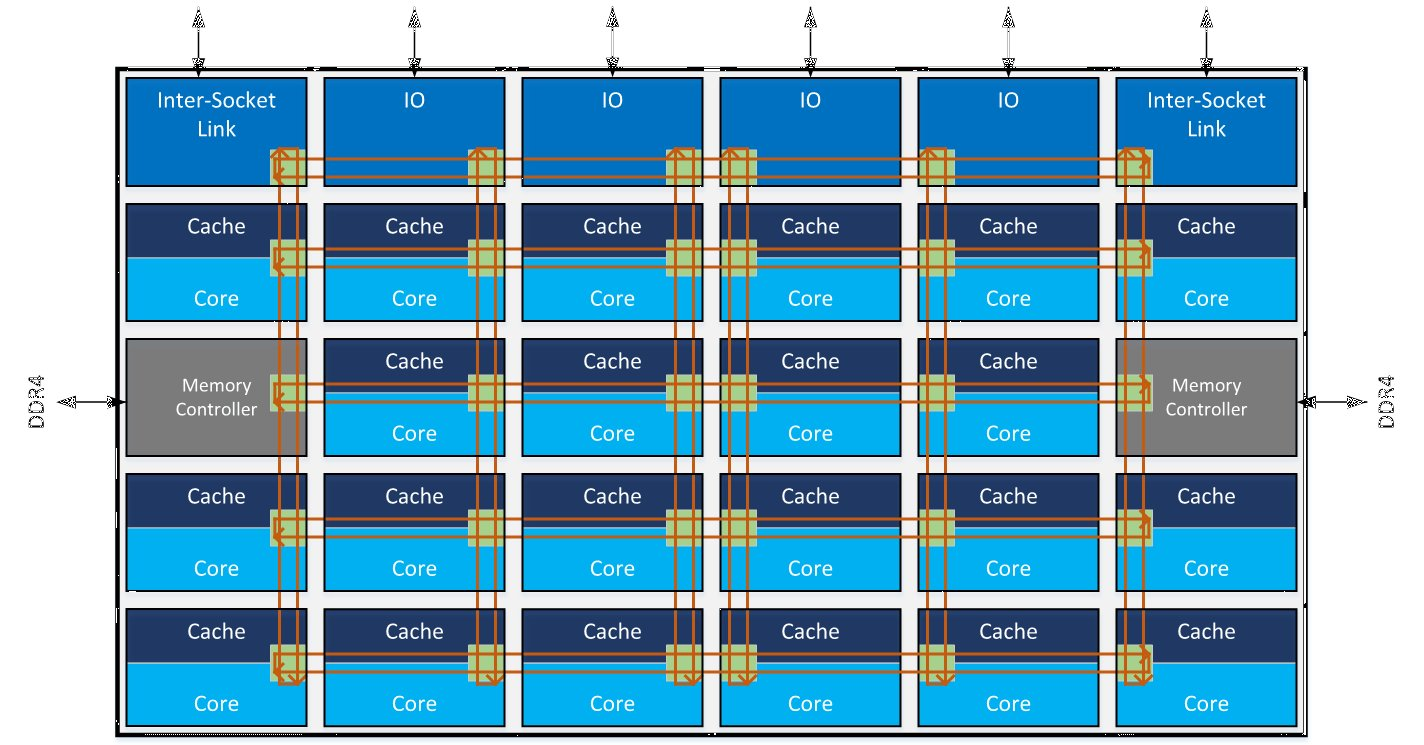
Az új topológia lényege, hogy minden sor és minden oszlop kap egy dedikált kommunikációs sávot (egy egyirányú gyűrűt), amelyen keresztül kommunikálhat. Ez azt jelenti, hogy az azonos soron vagy azonos oszlopon található egységek közvetlenül tudnak beszélgetni, a külön soron és külön oszlopon található egységek között viszont valahol "el kell kanyarodnia" az üzenetnek. Vagyis a megcímzett XY koordinátán található egységhez úgy jut el a jel, hogy előbb az Y sort keresi meg, majd azon a soron eljut az X állomáshoz.
A megoldás másik, kevésbé feltűnő előnye a kifelé mutató kommunikáció gyorsulása. Míg a gyűrűn a PCI Express csatoló és a memóriavezérlő egy-egy állomást kapott, az új rendszerben az UPI névre keresztelt Inter-Socket Link (amely a Quick Path Interconnectet váltja a foglalatok közöttii kommunikációban) a két sarkon foglal helyet, a memóriavezérlő a jobb és bal szélen, a PCI Express kimenetek pedig a felső élen - mind-mind külön porton. Ez jóval magasabb aggregált sávszélességet tesz elérhetővé az előző megoldáshoz képest.
Sakktábla a körgyűrű helyett
A megoldás tehát a magokat és az integrált vezérlőket egy vertikálisan és horizontálisan elrendezett csatornákból álló, komplex háló köti össze. A megoldás előnye a fenti ábrán is jól látható, például bizonyos, középen elhelyezkedő magok 1 ciklus alatt hozzáférhetnek szomszédjaik gyorsítótárának tartalmához, a példaként szereplő 22 magos kialakításban pedig a legtávolabbi magot is el lehet érni 8 ciklus alatt. A megoldás előnye, hogy jól skálázható, ahhoz nem szükséges a késleltetést növelő pufferelt kapcsoló beépítése, illetve kiszámíthatóan alacsony a késleltetés a kommunikációban, nincs meg a veszélye, hogy egy azonos feladaton dolgozó magpár külön magcsoportra kerül és a lassú kommunikáció szűk keresztmetszetet képez (mint az már említett AMD CCX-es esetben).
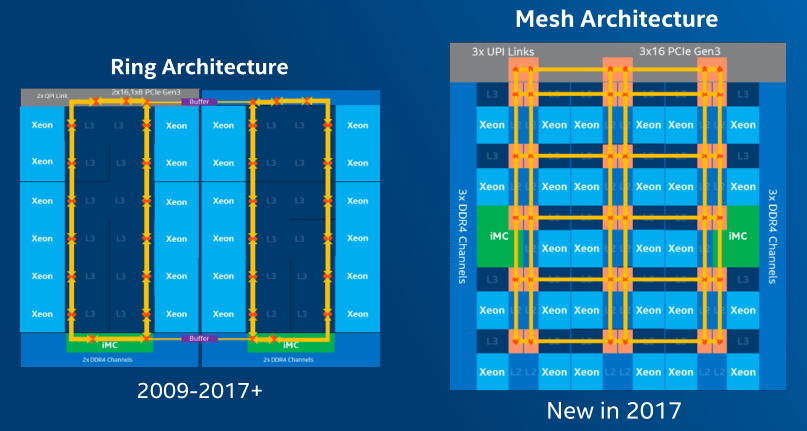
Természetesen nem csak előnyökkel rendelkezik a hálós buszrendszer. A megoldás lényegesen komplexebb, így több tranzisztort emészt fel mint az egyszerűbb, körgyűrűs megoldás, ebből adódóan pedig a vezérlése is bonyolultabb. Pontos számokról nem beszél az Intel, így egyelőre csupán annyit tudni, hogy a hálós buszrendszer nagyobb sávszélességet biztosít, amivel nem csak a magok közti kommunikáció gyorsul, hanem például a memória elérésének tempója is javul. A vállalat azt is elmondta, hogy az új busz alacsonyabb órajelet igényel, azonos magszám esetében pedig disszipációja a körbuszénál kisebb.
A hálós rendszert egyelőre csak a Skylake-X és Skylake-SP processzorok kapják meg, arról nincs információ, hogy a PC-s környezetbe szánt 2-4-6 magos dizájnokhoz lecsurog-e a fejlesztés, amennyiben pedig igen, akkor mikor. Ezek a lapkák lényegesen egyszerűbb felépítésűek, így elképzelhető, hogy az Intel ezeknél még pár generációig megtartja a körgyűrűs buszrendszert.