Network coding: a hatékony böngészős videostreamért
A network coding manapság még keveset használt fogalom és ritka kutatási terület, pedig fontos webes alkalmazási lehetőségei lehetnek. Ennek egyik bizonyítéka Braun Patrik János, a BME AUT PhD hallgatójának Peer-to-peer technológiával támogatott Video on Demand streamelésről szóló vizsgálata.
A hálózati kódolás hatékonyságának vizsgálatával, ezen belül is az újdonságnak számító network coding alkalmazási lehetőségeivel foglalkozik Braun Patrik János, ezt kutatja doktoranduszként a BME Automatizálási és Alkalmazott Informatikai Tanszéken, és ezzel vett részt kiállítóként az idei CES-en és IEEE CCNC-n, utóbbiról pedig a legjobb előadásért járó díjat is elhozta. A network coding egyelőre meglehetősen egyedi kutatási területnek számít, mivel a hazai egyetemen kívül főként az Aalborgi és a Drezdai Egyetem, valamint az MIT foglalkozik vele. A magyar kutató először 2015-ben Drezdában kezdte vizsgálni a WebRTC és Network Coding alapú Peer-to-perrel támogatott Video on Demand streamelést, és pár hónap alatt sikerült egy működő prototípust létrehoznia, majd ezen dolgozott tovább a későbbiekben.
Mi is az a network Coding?
A network coding egy kódolási technológia, de Braun nem magával a kódolás megalkotásával foglalkozik, hanem a felhasználás lehetőségeit vizsgálja. "Úgy kell elképzelni, hogy ha kódolás nélkül egy 10 megabájtos videót akarunk átvinni 10 részletben a hálózaton, akkor 10 darab 1 megabájtos adatszelet fog utazni. Ha elveszik a második és a harmadik csomag, akkor a szervernek pont ugyanazt a két csomagot kell újraküldeni, külön az eredeti videót nem lehet majd megnézni, vagy csak részleteiben. Olyan ez mintha egy puzzle-ből hiányoznának darabok, mert ha hiányzik egy darab, akkor pont az oda passzolót kell beletenni." - magyarázta a kiinduló problémát.

Braun Patrik János az IEEE CCNC-n
Ezzel szemben a network coding, pontosabban Random Linear Network Coding (RLNC) használatával nem az eredeti tízszer 1 megabájt utazik a hálózaton, hanem 1 megabájtos összekódolt darabok - megfelelő beleállítások mellett sok száz, ezer vagy tízezer kódolt csomagot lehet így előállítani. Ezek a csomagok paritási adatokat is hordoznak, és úgy viselkednek, hogy bármelyik tíz birtokában elő lehet állítani az eredeti adatot. Így ha elveszik valamelyik csomag, akkor csak egy újabb, tetszőlegesen kódolt csomagot kell elküldeni, függetlenül attól, hogy melyik csomag veszett el. "Egy vödrünk van és ezt kell megtölteni, ha tele van a vödör, akkor készen vagyunk. Nem számít, hogy melyik csomag van nálunk, ha elegendő mennyiségű csomagunk van. Természetesen a kódolás más nehézségeket hoz be a kommunikációba, de bizonyos helyzetekben ezek elhanyagolhatóak." - mutatott rá a BME AUT doktorandusza.
P2P videónézés böngészőben
A network coding területén belül Braun a böngészőben meglévő technológiák felhasználásával P2P-alapon szeretné megvalósítani a VoD streamelést egy erre a célra megalkotott protokoll segítségével. Hogy meg tudja mondani mennyit segít a network coding, ezért létrehozta a WebPeer protokollt, amelyet network coding támogatással kiegészítve létrejött a CodedWebPeer. "A megoldást úgy kell elképzelni, mintha a YouTube-t néznénk és az adat nem csak a Google-től jönne, hanem ha a szomszéd is pont ugyan azt a videót nézi, akkor tőle is. A megoldás hasonlít a BitTorrenthez, csak itt mindig jelen van egy szerver, aminek minden adat, ebben az esetben videó megvan. Ez azért szükséges, hogyha épp senki nem néz egy adott videót, akkor is biztosak lehessünk benne, hogy le tudjuk tölteni a szerverről." - magyarázta a kutató.
Viszont végtelen mennyiségű adatot nem lehet a böngészőben tárolni vagy legalábbis nagy technikai kihívást jelent, ezért egy idő után törölni kell a megnézett részeket. "De ha már megnéztük a film felét és a másik felét töröltük, akkor mit adunk oda a szomszédnak?" Mivel milliós felhasználószámról beszélünk, ezért nem lehet teljesen lekövetni, hogy kinél milyen adat van, így a megoldás véletlenszerűen töröl - a matematikában a véletlen szokott működni, elméletileg a rendszernek az egész filmre nézve egyenletesen kellene törölni az adatokat.
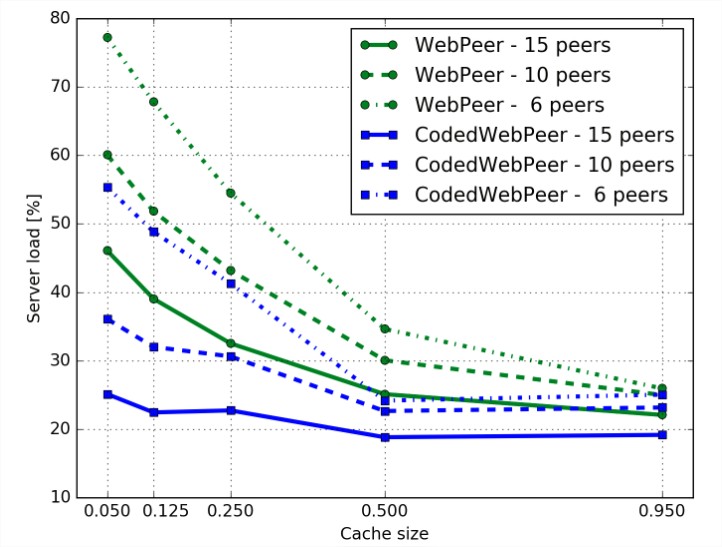
"Minél több adatot eldobunk, annál több peerre van szükség az adatok visszaállításához, míg a WebPeernél ez az arány exponenciálisan nő, ahhoz képest a network condingnál csak nagyon kis mértékben." - mondta Braun. Azonban egyelőre meglepően sokszor fennáll a “születésnapi paradoxon probléma” az eredmények szerint, vagyis vannak olyan adatok, amelyek éppen senkinél nincsenek meg - ebben az esetben mindenképp a szerverhez kell fordulni.
Nehezíti a feladatot, hogy böngészőben még nem teljesen egyértelmű az ilyen technológiák kivitelezése. WebRTC segítségével lehetséges lenne a böngészők közötti, szerver nélküli direkt kommunikáció, de ez a technológia még nem standard. A kihívás része az is, hogy az emberek a filmet úgy szeretnék nézni, hogy az elejével kezdik, és közben is tölthetik a soron következő részleteket, vagyis az adatokat sorrendben akarják leszedni és nem véletlenszerűen - de ezt bonyolítja, hogy a rendszer kitöröl egyes részeket.
Az viszont, hogy melyik darabot kéri el a rendszer a központi szerverről vagy egy másik felhasználótól alapvetően "egy üzleti döntés", mivel fejlesztési szempontból csak a prioritási sorrend változik. Braun meglátása szerint egy szolgáltatónak az a célja, hogy ne veszítsen felhasználót, ezért nem érdemes mindent rájuk hárítania. Viszont a technológia egyik fontos aspektusa, hogy kisebb cégek nem engedhetik meg maguknak Google-méretű szerverparkok fenntartását, és így nagy mennyiségű felhasználót nem tudnak megfelelő minőségben kiszolgálni - míg ezzel a megoldással az adatnak csak kis része származik a szervertől, nagy részét pedig a többi hálózatban lévő kliens ki tudja kiszolgálni, ami nagy mértékben csökkenti a szerverterhelést és ezzel együtt a költségeket.
Nagy pénz, nagy szívás: útravaló csúcstámadó IT-soknak Az informatikai vezetősködés sokak álma, de az árnyoldalaival kevesen vannak tisztában.
A megoldás terhelést ad a felhasználói oldalnak, mert a kliensek sávszélességét és számítási kapacitását használja, miközben azok egymásnak küldenek adatokat. A kutató szerint erre megoldást jelenthetnének olyan kedvezmények, amelyek adatmegosztás esetén csökkentik az előfizetési díjat. "A kedvenc személyes példám, mikor 2016-ban mindenki a foci EB-t nézte, az M4 Sport nem tudta azt megfelelő minőségben közvetíteni a hirtelen megnövekedett igény miatt (...) sokszor megszakadt, elment az adatás és a szomszédból hallottuk, hogy gólt rúgtunk, miközben nálunk fekete volt a képernyő. Akkor én odaadtam volna az összes CPU időmet és sávszélességemet, csak időben lássam a közvetítést." - mesélte Braun.
Hasonló network coding nélküli megoldások már léteznek a piacon, de ez a kutatás abban különbözik tőlük, hogy az adatot képes network codinggal kódoltan továbbítani, és ez még hatékonyabbá teszi a szolgáltatást, például gyorsabb letöltést és a szerver terheltségének csökkentését ígéri. A P2P kutatáson Braun Patrik a jövőben is aktívan dolgozik, a PhD befejezését az MIT-n tervezi, eközben pedig magyar és német professzorokkal közösen azon is dolgozik, hogy termék, szolgáltatás vagy cég legyen belőle.
Kutatási beszámolók Braun Patrik János ResearchGate felhasználói profilján elérhetőek.