Golyóálló HP Integrity szerverek
Ha számítógépek kerülnek szóba, akkor minden bizonnyal a teljesítmény a jellemzés és összehasonlítás leggyakoribb alapja, notebookok, asztali konfigurációk vagy szerverek esetében egyaránt. A teljesítmény az egyik legfontosabb tulajdonság, mérése pedig önmagában is egy igen összetett, és mély ismereteket igénylő terület, azonban messze nem az egyetlen releváns tényező egy számítógép kiértékelésekor -- különösen nem egy szerver esetében.
Az IT felelőssége
Az informatikai rendszerek az üzleti produktivitást nem csak teljesítményükkel, hanem megbízhatóságukkal, rendelkezésre állásukkal, és szervizelhetőségükkel is meghatározzák -- ez a RAS, vagyis a Reliability, Availability, Serviceability. Ha a teljesítmény a számítási kapacitás mennyiségét mutatja, akkor a RAS a minőségét. Minél nagyobb az IT-rendszer által támogatott üzleti folyamatok és adatok értéke, annál inkább felértékelődnek a RAS-képességek, így nem véletlen, hogy létezik egy stabil, évi több mint 25 milliárd dolláros piac, ahova az x86-os tömegszerverek nem tudnak betörni. Ezt az üzletileg kritikus szerverpiacot célozza a HP Integrity szervercsaládja, HP-UX, Windows, Linux és OpenVMS szoftver platformokkal egyaránt.
Bármekkora lehet az IT-rendszer teljesítménye, ha feladatát hibásan, vagy egy leállás miatt egyáltalán nem végzi el. Ezek az esetleges adatvesztések és kiesések az informatikai infrastruktúra költségét többszörösen is meghaladó üzleti kárt okozhatnak a mai, folyamatos és gyors működést igénylő világunkban: elszalasztott bevételek, hírnév és bizalom sérülése, kötbér és kártérítések. A pénzügyi, telekommunikációs, kereskedelmi, energetikai vagy termelőipari szektorokban óránként akár több tíz- vagy százmillió forintos kár is keletkezhet egy-egy leállással.
Igaz, a leállások túlnyomó többségének forrása nem a szerver hardver vagy szoftver komponensei, hanem emberi hiba, vagy a géptermet érintő események. Az operátorok átlagosan a kiesett idő 29 százalékáért felelősek, míg a teremkarbantartás szorosan a második befutó, a katasztrofális események 8 százalékkal pedig a harmadik helyen vannak. Utóbbi két faktor bár ritka, ha bekövetkeznek azonban, hosszas leállást, és rengeteg kárt okozhatnak.
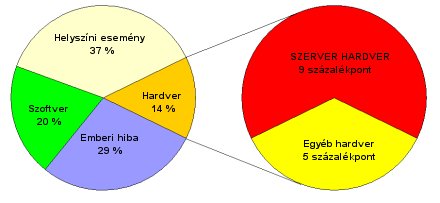
| RAS? |
|
De mi is pontosan a RAS? A reliability, azaz a megbízhatóság a rendszer azon képességét mutatja, várhatóan mennyi hibát fog produkálni működése során. Ezt jellemzően a hibák várható éves számával mérik, amely egy statisztikai átlag, a valóságban ennél jobban és rosszabbul teljesítő konfigurációk is találhatóak. Tökéletes hibamentesség azonban nem létezhet, főleg nem az olyan komplex rendszerek esetében, mint a szerverek, ezért a minél magasabb megbízhatóság mellett szükség van a RAS-ban foglalt további két jellemzőre is.
A rendelkezésre állás (avaliability) hivatott számszerűsíteni, hogy egy szerver az idő mekkora hányadában képes elfogadható szintű működésre, vagyis feladata zavartalan ellátására. Minél több a kilences, annál nagyobb a (jellemzően a hardverre meghatározott) rendelkezésre állás várható ideje: 99,5 százalékos szintnél évente 44 órát is állhat a gép (persze nem egyhuzamban), 99,9 százaléknál kevesebb mint 9-et, és minden egyes kilencessel ennek tizedét -- az Integrity NonStop például hét kilencesre is képes, vagyis az idő 99,99999 százalékban végzi feladatát, átlagosan évente 3 másodpercnyi nem tervezett leállást ér el. A szervizelhetőség lényegében a rendelkezésre állás részének tekinthető, hiszen befolyásolja, szükség van-e egyáltalán leálláshoz egy hiba kijavításához vagy egy upgrade elvégzéséhez, illetve ha már megtörtént a baj, akkor mennyi idő alatt lehet ismét működőképessé tenni a rendszert. A cél, hogy minél egyszerűbben, gyorsabban, a gép leállása nélkül lehessen elvégezni a lehető legtöbb műveletet. |
A golyóálló Integrity hozzávalói
A HP Integrity szerverek az Intel Itanium processzorokra alapoznak, így a meghatározó RAS-képességek egy része is ezekben található. A processzorok komplexitásuk exponenciális fokozódásával egyre több lehetséges probléma forrásává válnak, kezdve a tervezési hibáktól az egyes tranzisztorok vagy komplett logikai blokkok elromlásán át a lappangó bithibákig. Emiatt egyre több és több figyelmet kell fordítani a processzorszintű RAS-ra, hogy elkerülhetőek legyenek a rendszerleállások, vagy ami még rosszabb: az észrevétlen adatsérülések.
A Montecito kódnéven ismert jelenlegi Itanium 2 fejlett hibafelismerő, -javító és azokat elszigetelő képességekkel rendelkezik, melyek révén a rivális RISC és mainframe processzorok megbízhatósági szintjét is meghaladja -- nem beszélve a Xeon és Opteron chipekről. Az 1,72 milliárd tranzisztorból felépülő Montecito mind a magok logikájában, mind a hatalmas gyorsítótáraiban képes detektálni és javítani a legtöbb hibát, beleértve a kozmikus vagy egyéb háttérsugárzásból fakadó bithibákat (soft errors), ezáltal meggátolni a leállást, de legfőképpen az adatsérüléseket.
Sőt a legkritikusabb feladatok ellátásához akár párba is foghatóak Montecitók egymás ellenőrzésére, hogy egyazon utasításfolyam párhuzamos feldolgozásával egyikük hibázása vagy meghibásodása esetén se sérülhessenek meg az adatok. Ha egy processzor meghibásodik, akkor a HP-UX operációs rendszer támogatásával képes a feladatokba egy tartalékchipet bevonni, ha rendelkezésre áll.

A HP Integrity gépekben a processzorból kikerülve is védettséget élveznek az adatok. Az Itanium processzorok ECC-védett adatbuszon kommunikálnak a chipsettel, és azon keresztül a memóriával, más processzorokkal és a perifériákkal. Nagyobb, több tíz vagy száz gigabájtos memóriakapacitásnál a DRAM-chipek szintén a hibák jelentős forrásává válhatnak.
Ezért mind a belépő kategóriás zx2, mind a cellás felépítésű, skálázódó szervereket támogató sx2000 chipset is kifinomult hibajavítási algoritmusokat támogat, melyek a bit- és a hardveres hibákat egyaránt kezelni képesek az ún. proaktív scrubbing (súrolás, bithibák javítása) valamint a dupla-chipvédelem (double-chip sparing, egyszerre két chip elromlását is képes tolerálni). Ezek a memóriakapacitás vagy sebesség feláldozása nélkül a hagyományos ECC-hez képest 1200-szoros megbízhatóságot érnek el.
A meghibásodások természetesen leginkább a magas mechanikus vagy elektromos terhelésnek kitett alkatrészeket, vagyis a merevlemezeket, ventilátorokat, tápegységeket és hálózati eszközöket sújtja, de mára ezek nem okozhatnak sem leállást, sem adatvesztést a redundanciát biztosító megoldások (RAID, multipathing, redundáns tápellátás és hűtés) miatt, így az Integrity szervereknél is természetes meglétük.
Nem szokványos megoldás azonban, hogy a cellás (vagyis több rendszer alaplapból felépülő) Integrity szerverek (rx7640-től felfelé) hibatűrő összeköttetéseken kapcsolódnak egymáshoz, mégpedig egy hardveres tűzfalon keresztül, mely képes akár elektronikailag is elszigetelni egymástól, vagyis particionálni a cellákat, így azok semmilyen hatással nem lehetnek a többire, így a hiba vagy támadás nem terjedhet tovább más cellákra.
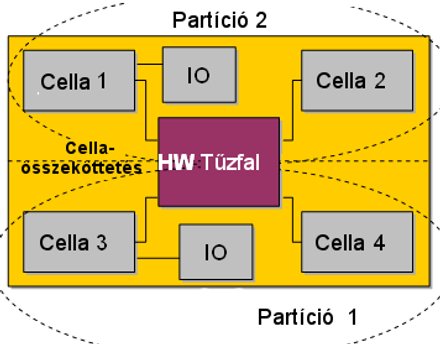
Ez a felépítés teszi lehetővé, hogy akár az egyik cella katasztrófális fizikai károsodása mellett is zavartalanul működjön tovább a többi, sőt a feladatokat is megszakítás nélkül átvegye, átvegyék tőle. A hardveresen izolált partíciók tizenhatszor magasabb megízhatósággal rendelkeznek, mint a szoftveresek, így a rivális RISC-rendszerek nem tervezett kieséseinek töredékét szenvedik el a HP Integrity szerverei.
A HP Integrity szerverek kritikus rendelkezésre állását példázza az fenti video is, ahol egy nagy erejű puskával lőnek bele működő rx7640 kiszolgálóba, szétroncsolva a gép egyik felét. Az izolált hardveres particionálás révén a sértetlen cella tovább üzemel, és gyakorlatialg megszakítás nélkül átveszi megsemmisített társa feladatait. A demonstrációról további részleteket itt olvashat.
Az üzletileg kritikus felhasználási területekre tervezett Integrity szerverekkel kapcsolatos további részletekért látogasson el a HP weboldalára.
Készült a HP megbízásából