AMD Vega: az első fontos részletek
Alaposan áttervezett memória-alrendszerrel, rengeteg adósságot törlesztve érkezik az AMD Vega generációs GPU-ja. Lássuk az izgalmas részleteket!
Elkezdett beszélni legújabb GPU-s architektúrájáról az AMD. A Vega kódnéven érkező új generáció a GCN öt évvel ezelőtti bevezetése óta a legnagyobb ugrást ígéri, ennek megfelelően a vállalat szinte minden ponton hozzányúlt az architektúrához, az egyszerű feldolgozó egységektől a memóriavezérlőig. Az AMD messze nem terítette az összes kártyáját, a rajtig még hátralévő néhány hónapban további érdekes részletekre számítunk.
Újragondolt memória
A Vega az első említések óta úgy szerepel az AMD terméktervein, mint a HBM2-t elhozó architektúra. Ezt a cég be is váltja, a Vega valóban az új, második generációs rétegzett memóriát használja majd, de a memória-alrendszer átdolgozása ennél sokkal mélyebb - annyira, hogy a "világ legjobban skálázódó GPU memóriaarchitektúrájának" nevezi az AMD.
Kezdjük a HBM2-vel. Az AMD még 2015-ben mutatta be első rétegzett memóriát használó egységeit, a Fury sorozatot. Ezek még a HBM első generációjára építettek, így hatalmas memóriasávszélességgel gazdálkodhattak, viszont a maximális kapacitást korlátozta a technológia - a négy mellékelt chip 4 gigabájtnál megállt. A HBM2 ehhez képest két ponton újít: egyrészt az effektív órajelet duplázza, másrészt a stackek kapacitását nyolcszorosára emeli. A két fejlesztés eredője, hogy azonos sávszélesség elérhető fele annyi stack segítségével is, miközben a maximális kapacitás még mindig négyszerezhető, így két modullal is 16 gigabájt lehet a maximum.
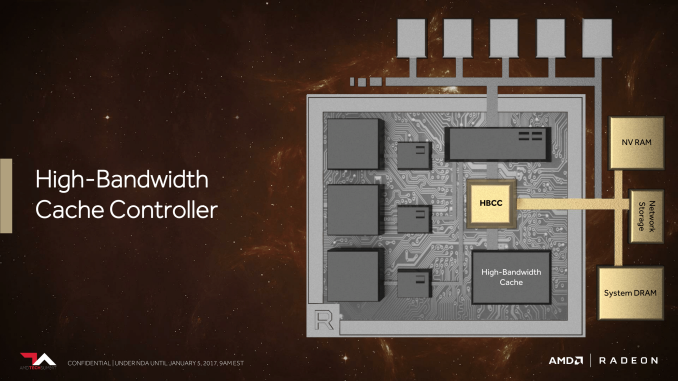
A másik fontos újítás a memóriavezérlőt érinti, amelynek neve immár High-Bandwidth Cache Controller, és ez kezeli (értelemszerűen) a HBM2 memóriát, illetve a lapkán kívüli memóriát, legyen az a kártyára integrált NAND vagy a rendszermemória. Ez, az egységes memóriakezelés nyitja meg az utat azelőtt, hogy ezeket a különböző típusú, különböző előnyöket és hátrányokat kínáló tárolókat a memóriavezérlő hatékonyan tudja kihasználni - és ez a Vega egyik legfontosabb fejlesztése.
A GPU-k memóriavezérlői ugyanis a PC-s memóriakezeléshez képest viszonylag egyszerűek, a komplex lapozás (paging), a különböző sebességű memóriák rétegzése és ezek közötti adatmenedzsment nem túl fejlett. Ez azt jelenti, hogy olyan esetekben, amikor az adathalmaz nagyobb, mint a helyi memória, a GPU-k kemény teljesítménykorlátba ütköznek. Ha ehhez hozzávesszük, hogy (legalábbis az AMD saját vizsgálata szerint) a szoftverek sem végzik el a házi feladatot a memóriahasználat optimalizálásában (sokkal több adatot töltenek be, mint amennyit valójában kihasználnak), akkor hátható, hogy van itt lehetőség a fejlődésre.

A fejlesztésnek közvetlen hatása első körben a professzionális (szerverek, munkaállomások) alkalmazások alatt lesz, ahol az adathalmazok jellemzően messze túlnyúlnak a kártyán található VRAM kapacitásán, az okos rétegzés, a gyakran használt adatok előtöltése a gyors memóriába kritikus lesz. A másik terület, ahol szintén hasznos lesz a fejlett vezérlő a GPU-virtualizáció, ezt szolgálja ki a látványosan kibővített, 512 terabájtos címezhető virtuális címtér, így a GPU-t egyszerre használó alkalmazások sem futnak ki a megcímezhető memóriából.
Hasonló logika vezette egyébként korábban a Radeon Pro SSG fejlesztését is, ott a kártyán található VRAM-ot SSD-vel egészítette ki az AMD, annak érdekében, hogy a nagy adathalmazokért se kelljen kinyúlni a rendszermemóriába. A közelség itt kritikus, a közbeékelődő elemek (vezérlő, CPU, RAM) átugrásával és az SSD közvetlenül a GPU-ra kötésével (némileg meglepő módon) értelmezhető teljesítménynövekedést sikerült az AMD-nek elérnie. Meglepő egyébként a dolog azért, mert hagyományosan a VRAM után a rendszer-RAM számít a második leggyorsabb tárolónak a hierarchiában, nagy statikus adathalmazok tárolásához azonban az integrált, kártyán ülő SSD is hatékony tud lenni - a gyakorlat ezt igazolja.
Új generációs feldolgozók
A tulajdonképpeni munkát végző feldolgozó egységekhez az AMD gyakorlatilag a GCN rajtja óta nem nyúlt érdemben, ebben hoz komoly változást a Vega - nem véletlen, hogy a cég a Compute Unit (CU) kifejezést most Next-Generation Compute Unitra (NCU) cseréli. Az új egységek (játékos szempontból) legfontosabb újdonsága, hogy azokat kimondottan magasabb órajelekhez optimalizálta az AMD, így magasabb teljesítmény is érhető el velük.

A profi felhasználók számára fontosabb változás, hogy az új mikroarchitektúra egy órajel alatt képes két fél pontosságú (FP16) lebegőpontos műveletet elvégezni. Az utasításpárnak "kompatibilisnek" kell lennie (ez valószínűleg azonos utasítás típust jelent), ezeket az egység képes "összecsomagolni" egyetlen FP32-es utasításba és egyben, egyszerre elvégezni. Ugyanez a gyorsulás az INT8 típusú számítások alatt is elérhető, ez elsősorban a neurális hálók alkalmazásánál számottevő. Mindez a játékok alatt nem releváns, ott egységesen FP32-es számításokat használnak, így ott elsősorban az órajel emelkedése hoz majd magasabb sebességet.
Na meg a körítés. Mert az NCU-kat körbevevő elemek is alapos átrajzolást kaptak. Az egyik ilyen a Shader Engine modulokat érinti, ezek a nagyobb egységek fogják össze a CU-kat és a többi kiszolgáló elemet az AMD architektúrájában. A GCN egyik limitációja a Shader Engine-ek számára vonatkozott, egy lapka csak 4 ilyen egység között tudta a feladatokat kiosztani, az AnandTech elemzése szerint a Vega várhatóan eltörölte ezt a korlátot, és immár több SE is képes hatékonyan együtt dolgozni, ami kitolja a chipek maximális méretét és teljesítményét.
A geometria-futószalag esetében a cég mintegy kétszeres sebességnövekedést ígér, a specifikációk szerint órajelenként 11 poligont képes a 4 mértani motor feldolgozni, ez kimagasló eredménynek számít, a komplex geometriával rendelkező új játékoknál ennek látványos hatása lehet. Erre rásegít, hogy a futószalag sokkal hatékonyabban és gyorsabban képes megkülönböztetni a takarásban lévő képelemeket, amelyek kiszámítása később nem foglal további értékes számítási kapacitást - ez nagyot javít a lapka hatékonyságán.
Nagy pénz, nagy szívás: útravaló csúcstámadó IT-soknak Az informatikai vezetősködés sokak álma, de az árnyoldalaival kevesen vannak tisztában.
Szintén fontos optimalizálást hoz a Draw Stream Binning Rasterizer, ami a tile-based (mozaikos) feldolgozás egyik formája, segítségével pedig csökkenthető a memóriahozzáférések gyakorisága. Ez egyébként a már említett takarásban lévő pixelek kiszűrését is hatékonyabbá teszi. A backend oldalon egy egészen másik típusú fejlesztés jön, a ROP egységek immár szintén hozzáférnek a chipen található másodszintű gyorsítótárhoz, így a késleltetett renderinget használó játékoknál lehetségessé válik, hogy a ROP-ok által elkészített textúrákat alapanyagként a chip más részei újrahasznosítsák, rengeteget spórolva ezzel.
Az első Vega-alapú chipet az AMD egyébként már december közepén bejelentette a Radeon Instinct gyorsítócsalád részeként, ez az MI25. A Vegát használó GPU-k konzumer piacon várhatóan az első félévben (annak is a vége felé) várhatóak, jelen állás szerint két különböző GPU-val támadja majd a piacot a vállalat.