A Sarkcsillagból merítenek erőt az új Radeonok
Még ha csak részben is, de lekerült a lepel a következő generációs Radeonok képességeiről. Többé-kevésbé szinte mindenhez hozzányúltak a tervezők.
Először beszélt részletesebben legújabb, várhatóan idén nyáron megjelenő új grafikus architektúrájáról az AMD-ről a tavaly külön divízióba szervezett RTG (Radeon Technologies Group). Ehhez az idei CES-t használta ki a divízió, ahol számos egyéb részlet mellett a soron következő mikroarchitektúráról is szót ejtettek a vállalat szakemberei.
Nyerd meg az 5 darab, 1000 eurós Craft konferenciajegy egyikét! A kétnapos, nemzetközi fejlesztői konferencia apropójából a HWSW kraftie nyereményjátékot indít.
Sok minden egyéb mellett a névadáson is változtatott az RTG, így született meg a Polaris (Sarkcsillag) elnevezés. Az AMD nem először kölcsönzi égitestek neveit termékeihez, legutóbb a Phenom processzorokat keresztelték el csillagokról (pl. Deneb, Thuban). A Polaris alá a mikroarchitektúra mellett a memóriavezérlő, a képi anyagok kódolásáért és dekódolásáért felelős egységek, valamint a kijelzővezérlő blokkja is besorakozik, így alkotva egy teljes egységet. A vállalat reményei szerint, az általuk csak makroarchitektúraként emlegetett egész névadásával könnyebben megkülönböztethetővé válnak az újabb termékek.

Jelentős mértékben újult meg a mikroarchitektúra. A szinte pontosan négy éve bemutatott GCN az évek során csak kisebb, leginkább funkcióbeli újításokkal gazdagodott, melyek nem befolyásolták számottevő mértékben az összteljesítményt. A GCN negyedik iterációja ("GCN4") ezzel szemben komolyabb, mind a számítási teljesítményt, mind pedig az energiahatékonyságot komolyabban befolyásoló változtatások vezet be, melyek egy részét ismertették is a fejlesztők. Ez a lépés már nagyon időszerű volt, ugyanis az Nvidia a Maxwell-alapú GeForce termékekkel faképnél hagyta a Radeonokat, mind teljesítményt, mind hatékonyságot tekintve.
Az alap nem változott, a GCN4 a 2012-ben piacra dobott pillérekre építkezik. Mindez nem meglepő, hisz időközben a konzolpiac (PS4, Xbox One) is erre rendezkedett be, ugyanakkor az Nvidia sikeres fejlesztései komolyabb módosításokra sarkallták a fejlesztőket. Ennek értelmében javult a GCN3 esetében bevezetett, a színadatok tömörítésére vonatkozó Delta Color Compression eljárás hatékonysága. Ez főként a szűkösebb memória-sávszélességgel rendelkező megoldások (pl. APU-k) esetében igazán hasznos, miközben az energiahatékonyságot tekintve minden termékre pozitív hatással lehet. Az RTG a shaderek végrehajtásának hatékonyságát is növelte, ugyanakkor ezekről további részleteket egyelőre nem árult el. Tekintve a Fury GPU 4096 végrehajtóval elért relatíve gyenge skálázódását, utóbbira már nagy szükség volt.
Az újítások listájában feltűnt a CPU-kból már ismert instruction prefetch, azaz az utasítás előbetöltés. Ez elsősorban az egyszálú teljesítményre lehet kedvező hatással, azaz ettől leginkább a különféle compute, tehát az általános számítási műveletek végrehajtása gyorsulhat majd. A GCN esetében a CU-k (Compute Unit) "etetéséért" felelős ACE (Asynchronous Compute Engine) egységek szerepét a Hardware Scheduler (HWS) veszi át, mely képességeit tekintve két ACE egységnek felel meg.

A GPU-ba egy új egység is került, az úgynevezett Primitive Discard Accelerator feladata a kirajzolt kép szempontjából irreleváns háromszögek elhagyása. A fixfunkciós blokk ezen próbál tovább javítani úgy, hogy a primitívekről a lehető leggyorsabban megmondja, hogy azok hasznosak vagy sem. Mindez elsősorban a komplexebb, több primitívvel operáló jelenetek tempóját gyorsíthatja. Az AMD ezzel faraghat hátrányából konkurenshez képest, az Nvidia ugyanis már jó ideje profitál egy hasonló végeredményre képes technikából.
Az fejlesztők az L2 gyorsítótárat is újdonságként aposztrofálták, ugyanakkor részleteket erről sem árultak el. A konkurens Maxwell mikroarchitektúrája ezen a téren újított, ugyanis a GPU-s területen szokatlanul nagy, 2-3 MB-os másodszintű cache-t kapott. Mindez az energiahatékonyság szempontjából is sokat segített, miközben a mikroarchitektúra korlátait valamelyest elmosta. Ennek fényében nem lenne meglepetés, ha a Polaris is egy relatíve nagyobb L2 gyorsítótárral érkezne, követve a konkurens mintáját.
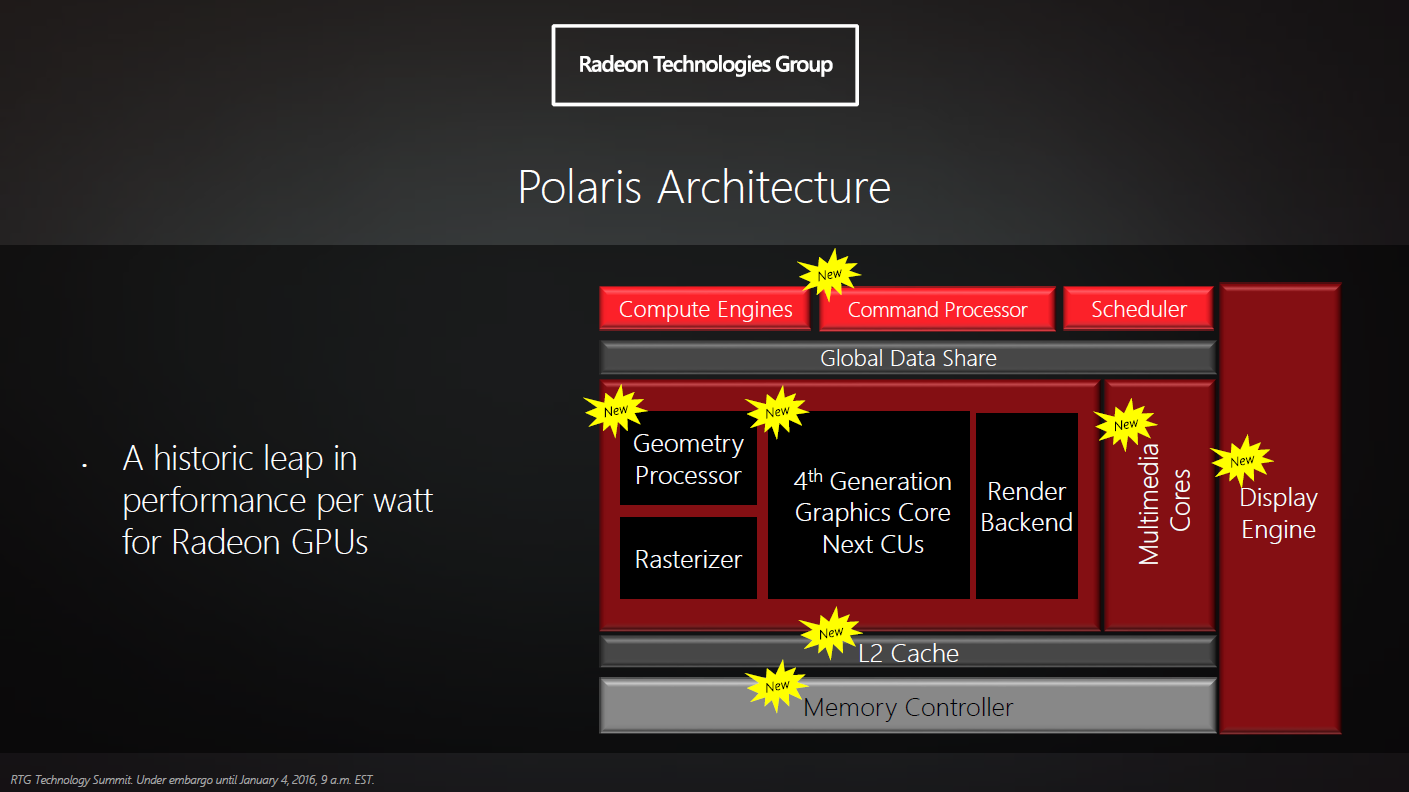
A gyorsítótárhoz kapcsolódó memóriavezérlőn is fejlesztettek, ugyanakkor itt valószínűleg csak optimalizálásokról lehet szó, vagyis várhatóan marad a jól bevált hubvezérelt kontroller. Ehhez GDDR5 vagy HBM típusú memória csatlakozhat, de arról nem szólt a fáma, hogy utóbbi pontosan milyen formában lesz jelen. Annyi borítékolható, hogy a költséges HBM-et a csúcskategória, illetve legfeljebb a közvetlen az alatt elhelyezkedő megoldások kapják meg, a többi modell továbbra is a költséghatékony GDDR5-tel érkezik.
A kijelzővezérlő blokk újításairól még tavaly decemberben beszélt részleteiben a vállalat. Sok egyéb más újítás mellett végre lesz HDMI 2.0a és DisplayPort 1.3 támogatás, miközben a FreeSync is kiterjesztést kap. A tervezők által csak multimédiás magokként emlegetett szekció tudása is nő. A HDR-hez kapcsolódóan megjelenik 10 bites (Main 10 profile) 4K HEVC/H.265 anyagok hardveres dekódolásának lehetősége, miközben már 4K felbontású HEVC formátumú anyagok tömörítésére is képes lesz a blokk, ráadásul mindezt legfeljebb 60 FPS mellett.
Az előadás külön kitért a gyártástechnológiára, ezzel pedig fény derült egy kvázi nyílt titokra. Bár azt egyelőre nem árulták el, hogy pontosan ki vagy kik lesznek a bérgyártók, de a vállalat egyértelműen 14 nanométerről beszélt, ilyen technológiája pedig jelenleg csak az Intelnek, a Samsungnak, illetve utóbbi jóvoltából a GlobalFoundries-nek van. A konkurens Intelt kizárva utóbbi kettő marad, akik a pár héttel ezelőtt felröppent hír szerint valószínűleg megosztva végzik majd a gyártást. Bár ez még nem zárja ki teljesen a TSMC-t, ugyanakkor tovább nőtt az esélye annak, hogy a tajvaniak (egyelőre) kimaradnak az üzletből.

A legutóbbi pénzügyi jelentés szerint az AMD legalább 33 millió dollárt dobott ki 20 nanométeres GPU-k tervezésére, melyekből végül csak tapasztalat lett, piacképes termék nem. A problémát a magas szivárgási áram okozta, nem lehetett kordában tartani a grafikus processzorok fogyasztását. A vállalatnak emiatt ki kellett hagynia egy generációt, az így keletkezett réseket leginkább átnevezésekkel próbálta betapasztani. Az Nvidia ezt elegánsan hidalta át a Maxwell GPU-kkal, az AMD végül pedig komoly hátrányba került a konkurenssel szemben. Ennek fényében nem csoda, hogy a cég most megváltóként tekint a FinFET-re, hisz az elmúlt években a Radeonok rendre elsőként aknázták ki az fejlettebb gyártástechnológiák által kínált előnyt.
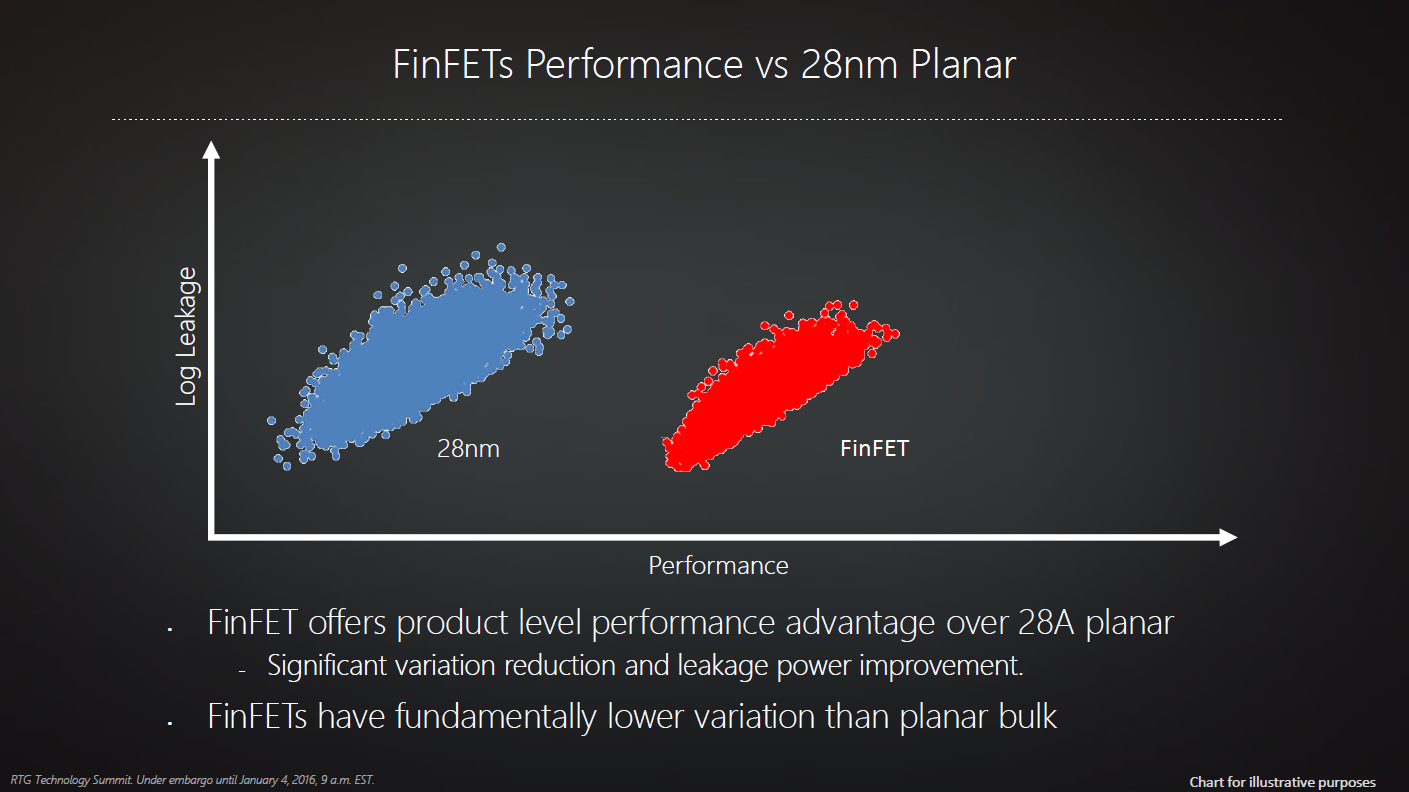
Az AMD reménye tehát most a háromkapus tranzisztorokban csillant fel, melyek jelentősen csökkentik a szivárgási áramot, 14 nanométeren kisebb értékkel számolnak mint a 28 nanométeres planáris eljárás esetében - bónuszként pedig a szórás is jóval alacsonyabb. Eközben természetesen tovább nő a sűrűség, azonos tranzisztorszám mellett csökkenhet a lapka területe, illetve annak disszipációja. Bár a 20 nanométeres lépcső kimaradt, a fejlesztések sajátossága miatt a 28-ról 14 nanométerre való ugrás mégsem tekinthető két teljes lépcsőnek, hisz a Samsung (akárcsak a TSMC) a 20 nanométeres technológiára alapozva fejlesztette ki a 14 (illetve 16) nanométeres FinFET eljárását. Ennek ellenére a csíkszélesség csökkenésétől várható a nagyobb előrelépés, míg a mikroarchitektúra frissítése kisebb, de számottevő mértékben járul majd hozzá a vállalat szerinti, kétszer kedvezőbb teljesítmény/fogyasztás mutatóhoz.
AMD’s Revolutionary 14nm FinFET Polaris GPU Architecture
Még több videóJelenleg úgy fest, hogy minden adott egy igazán nagy ugráshoz mind a számítási teljesítmény, a megjelenítési tempót, mind pedig a teljesítmény/fogyasztás mutatót tekintve. Ugyanakkor azt még megtippelni is nehéz, hogy az új Radeonok mennyire tudják felvenni a versenyt a legfőbb rivális Nvidia új termékeivel. A Pascal fedőnevű megoldásokról ugyanis egyelőre azon túl nem sokat tudni, hogy a GPU-k a TSMC 16 nanométeres FinFET gyártástechnológiájával készülnek majd, illetve a komolyabb modellek szintén rétegzett memóriával érkeznek. Az első nagy összecsapás a nyári hónapok során várható, amikor mindkét vállalat piacra dobhatja új grafikus kártyáit.